- The paper presents an adaptive multilevel SVM algorithm that integrates AMG-inspired coarsening and dynamic recovery to maintain high classification quality.
- It confines expensive kernel parameter tuning to coarse levels and uses localized refinement to limit training to critical data points.
- Empirical results show that AML-SVM delivers superior G-mean performance and reduced computation times, especially on large-scale, imbalanced datasets.
Adaptive Multilevel Learning with Support Vector Machines: Technical Analysis of AML-SVM
Introduction: Motivation and Context
Support Vector Machines (SVMs) remain a primary supervised learning paradigm for high-accuracy, robust classification, particularly well-suited for high-dimensional and complex decision boundaries. However, their nonlinear kernelized variants incur O(n2f) to O(n3f) complexity in both compute and storage for datasets of size n and feature count f due to the kernel matrix, restricting scalability in the presence of modern large-scale data. While previous scalable SVM approaches exploit parallel solvers, data partitioning, and graph-based representations, they often suffer from issues such as quality degradation during refining stages or from strict partitioning protocols.
AML-SVM (Adaptive Multilevel Learning with SVMs) introduces an improved multilevel computational learning pipeline that adaptively corrects for quality drops during hierarchical solution refinement and enables robust, scalable nonlinear SVM training. The core contributions center on integrating adaptive validation-driven refinement and multi-threaded parameter tuning within a flexible algebraic multigrid (AMG)-inspired coarsening/uncoarsening framework.
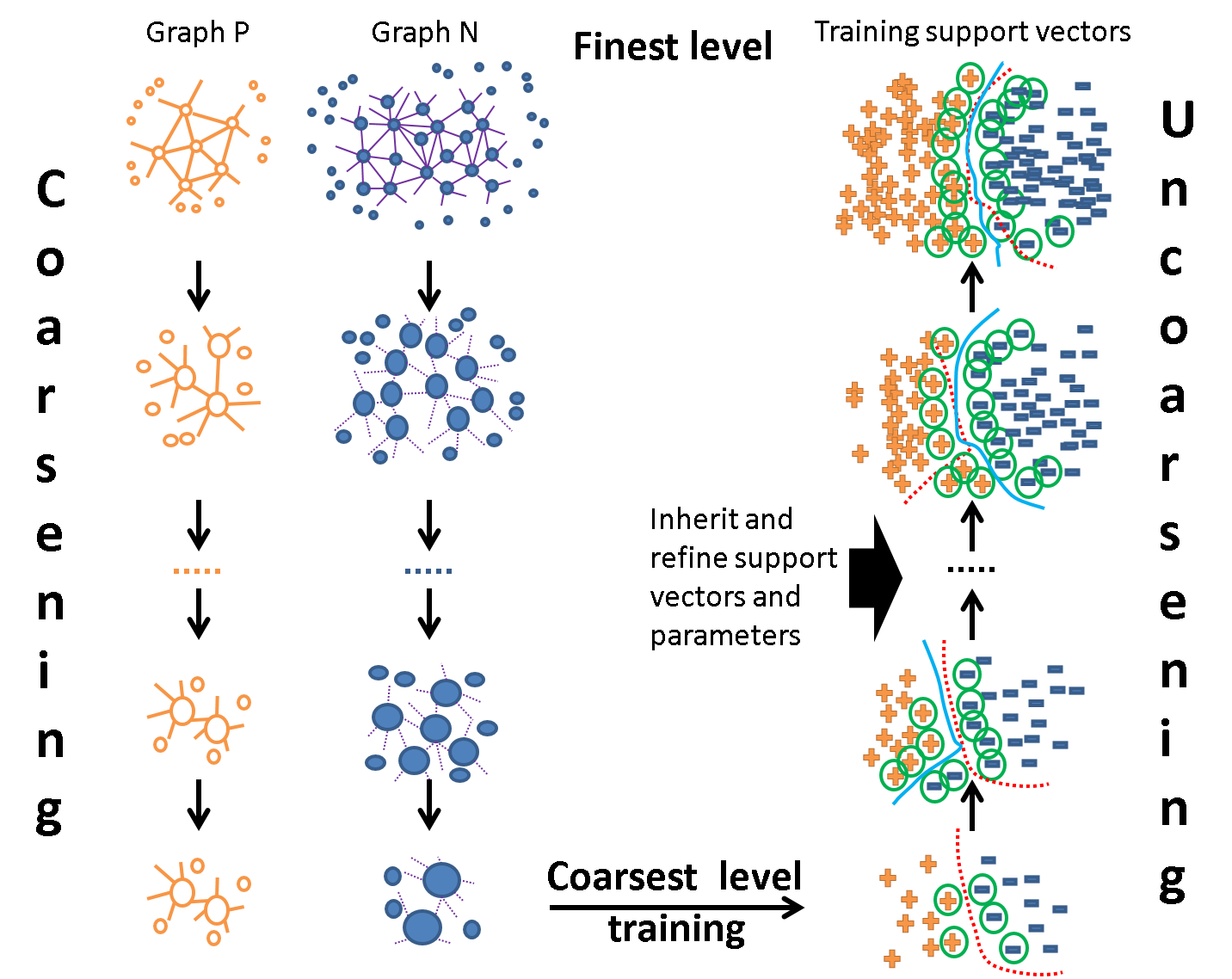
Figure 1: Adaptive multilevel learning framework scheme.
Framework Architecture and Multilevel Learning Protocol
AML-SVM extends the Multilevel SVM (MLSVM) approach, where successive approximation of the training dataset is accomplished via algebraic multigrid coarsening. This yields a hierarchy of problems, each with a reduced data representation. At the coarsest level, a compact kernel SVM is trained with exhaustive parameter fitting. The solution (support vectors and fitted parameters) is then recursively lifted and refined at increasingly finer levels, but only on data points proximate to the previous support vectors, drastically limiting training set sizes at each level.
Key architectural principles are:
- Localized Solution Refinement: Only data near the evolving separating hyperplane (i.e., in the vicinity of inherited support vectors) is maintained at finer levels, exploiting the observation that most original data points are irrelevant for margin determination.
- Coarse-level Expensive Operations: Time-intensive operations, including kernel parameter fitting (via Nested Uniform Design, NUD), are confined to coarse levels.
- Model Selection Across Hierarchies: The best classifier may not reside at the finest level—intermediate levels may yield superior generalization and sparser support sets.
- Instance and Class Weighting: Through volume-aware weighting by propagation of fine-level point contributions to coarse aggregates, class imbalance is elegantly compensated without loss of granularity.
Coarsening leverages approximate k-nearest neighbor (kNN) graphs constructed separately for each class, with k=10 empirically supporting robust aggregation. The interpolation process for coarse-to-fine point reconstruction utilizes the AMG paradigm, enabling fractions of data points to propagate to several aggregates, yielding a flexible, less stringent representation compared to hard clustering.
Adaptive Refinement and Recovery for Quality Drop
A critical observation in empirical evaluation of standard multilevel SVM is the phenomenon of unnatural quality trends—in certain datasets, refinement leads to significant drops in validation G-mean at intermediate levels, attributed to suboptimal support vector propagation and corresponding neighborhood selection mistakes.
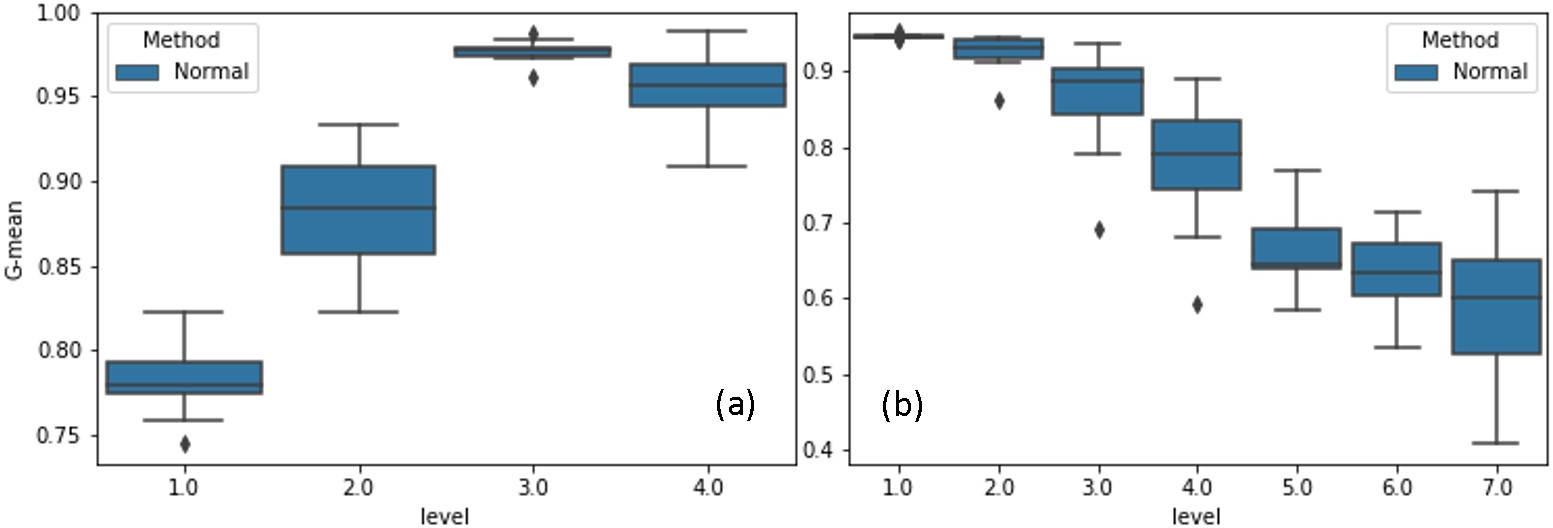
Figure 2: Natural (a) and unnatural (b) trends, increasing and decreasing the classification quality (G-mean), respectively, during refinement.
AML-SVM introduces a detection-and-recovery protocol: At each level, model quality is evaluated using a large validation set. If a significant degradation is detected (quantified by G-mean threshold violation), training is dynamically augmented by including nearest neighbors of misclassified validation points, thereby filling the training data representation gap. This enforces the inclusion of samples critical for correcting prior misclassification boundaries and is inherently adaptive—the process continues until the quality drop is recovered or further augmentation yields no substantial improvement.
For extremely large datasets, validation subset sampling schemes may use disparate ratios per class for computational tractability (e.g., 2% for majority, 50% for minority), maintaining statistical representativeness. Early stopping is employed to avoid fine-level overfitting and resource exhaustion once continued refinement fails to improve validation metrics.
AML-SVM is benchmarked against state-of-the-art implementations including LIBSVM, DC-SVM, and the original MLSVM. Across diverse, heavily imbalanced datasets (sizes up to $11$M, imbalance ratios ϵ from $0.5$ to $0.98$), AML-SVM matches or exceeds classification performance while significantly reducing wall clock times due to both algorithmic and parallelization gains.
Notably:
- For large datasets (e.g., HIGGS: n=11M, f=28), AML-SVM yields G-mean of 0.61 with wall times of 882s, outperforming alternatives both numerically and in compute efficiency.
- On challenging datasets (e.g., SUSY, Buzz), AML-SVM achieves high G-mean while incurring order-of-magnitude lower wall times compared to serial solvers, reflecting both effective reduction of training set size by selective refinement and multi-threaded parameter tuning.
- Quality variance across levels is substantially decreased, and best models often reside in middle levels, supporting the assertion that exhaustive refinement to the finest granularity is not universally optimal.
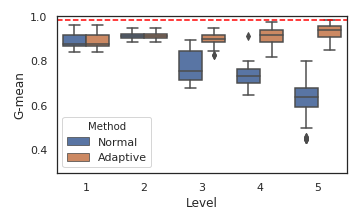
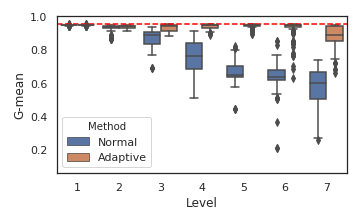
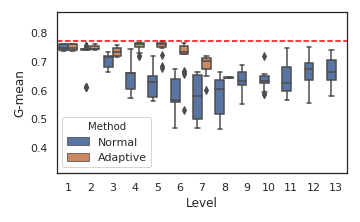
Figure 3: Comparing the prediction quality across levels for Clean, Cod, and SUSY data set from top to bottom
The visualizations for synthetic and real datasets further demonstrate the framework's ability to generalize across diverse data geometries and to adaptively recover from refinement-induced model degradation.
Practical and Theoretical Implications
The AML-SVM protocol demonstrates practical scalability for nonlinear SVMs, previously limited by quadratic kernel growth and sensitivity to parameter choice in high-imbalance or high-dimensionality regimes. By confining computational burden to coarse summaries and adaptively augmenting critical underrepresented regions during refinement, the framework is robust to both over- and underfitting, and less sensitive to configuration parameters.
Theoretically, this strongly supports hierarchical learning as both a computational and regularization device for large-scale kernel methods, and points toward the utility of AMG-inspired, instance-fractional aggregation in both supervised and unsupervised learning. Volume-aware aggregation, dynamic data augmentation, and multi-threaded parameter search can be further extrapolated to distributed and federated settings, where maintaining quality across heterogenous, partitioned data will be vital.
Future Developments
Directions for further research include extending the AML-SVM framework to:
- Multi-class and multi-label kernel learning with adaptive error recovery at each class.
- Integration with ensemble learning by aggregating classifiers across the multilevel hierarchy for added robustness.
- Automated selection of best hierarchy level(s) via meta-learning over G-mean and support vector statistics to suppress overfitting.
- Exploration of synergy between AML-SVM style data reduction and recent large-scale deep kernel machines or hybrid neural-SVM constructs.
Conclusion
AML-SVM establishes an adaptive, multilevel computational pipeline for nonlinear SVMs that enables both high-quality classification and broad scalability to large-scale, highly imbalanced data. The essential innovation lies in the adaptive data augmentation protocol, recovery from validation-induced quality drops, and hierarchical regularization, all embedded within a computationally efficient AMG-inspired framework. This architecture advances both the empirical tractability and the theoretical robustness of kernel SVMs as a competitive baseline for modern large-scale classification tasks (2011.02592).

