- The paper introduces a two-stage framework that first disentangles word-level prosodic features and then predicts them using context-derived information.
- It employs CNNs, BiLSTMs, and a fine-tuned BERT model to integrate syntactic and semantic features, enhancing the realism of synthesized speech.
- Experimental results show a 26% improvement in closure with natural speech compared to baseline models like Tacotron-2, validated through MUSHRA tests.
CAMP: A Two-Stage Approach to Modelling Prosody in Context
Introduction
"CAMP: a Two-Stage Approach to Modelling Prosody in Context" investigates advanced techniques for improving prosody modeling in Text-to-Speech (TTS) systems. The paper addresses two significant issues in prosody modeling: the slow variation of prosody signals compared to other signals, and the problem of generating appropriate prosody in the absence of sufficient context. To solve these, the authors propose a two-stage approach that learns to disentangle prosodic information at the word level using a context-aware model of prosody (CAMP) and employ syntactic and semantic information to create a context-dependent prior over this prosodic space.
Methodology
The proposed method consists of two distinct stages. In the first stage, prosodic representation is learned from mel-spectrograms, auto-encoded with a word-level reference encoder that is specifically designed to capture suprasegmental prosody features. In the second stage, a prosody predictor uses context-derived features to predict the word-level prosodic representations. This context-aware prediction employs text-derived syntactic and semantic features, utilizing a combination of CNNs and BiLSTMs for context encoding, along with a fine-tuned BERT model for capturing semantic nuances.
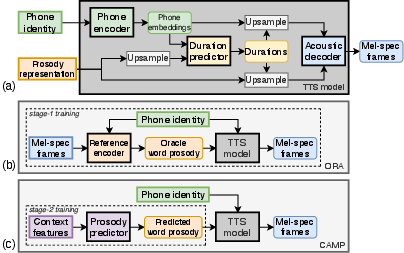
Figure 1: TTS model synthesis driven by a prosody representation, and CAMP's context-aware prosody prediction.
The first stage is crucial for separating prosody from segmental and background information, while the second stage ensures the contextual relevance of prosody output by the model, effectively addressing the context deficiency problem prevalent in existing TTS systems.
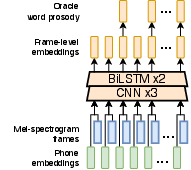
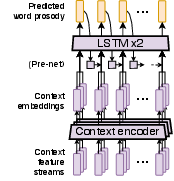
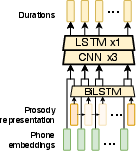
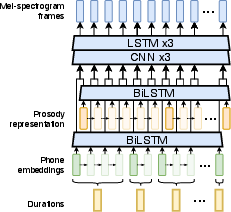
Figure 2: Word-level reference encoder, a crucial component in learning prosodic representation.
Evaluation and Results
The study conducted comprehensive subjective evaluations using ablation tests and comparative analysis against state-of-the-art models. Key benchmarks included Tacotron-2 as a baseline, with enhancements through a jointly-trained duration model. Results exhibited that CAMP surpassed existing models, producing a 26% improvement in the gap with natural speech, attributed to its two-stage architecture as highlighted in the MUSHRA evaluation.
The evaluation also underscored the efficacy of incorporating BERT as a semantic context feature encoder, further enhancing the richness of generated prosody due to its capacity to capture both syntactic and semantic aspects of language.

Figure 3: Preference test demonstrating enhanced prosody with a duration model over Tacotron-2.
Discussion
The proposed CAMP model excels in addressing prosody variability and context inadequacies, offering a robust technique for generating more natural and contextually appropriate prosody in TTS. A significant insight from the study is the necessity of effectively leveraging text-derived context features and the superiority of using a joint duration model for prosody prediction.
To enhance further, researchers could explore leveraging multi-speaker datasets for improved disentanglement and exploring advanced methods of context feature extraction, expanding the context window to include neighboring sentences for richer contextual modeling.
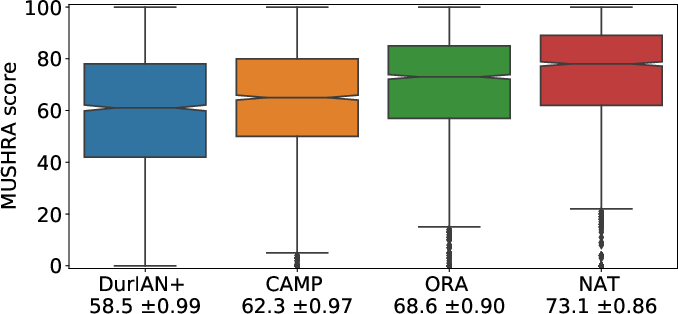
Figure 4: MUSHRA results with CAMP, showing significant improvement over previous models in perceived prosody quality.
Conclusion
"CAMP: A Two-Stage Approach to Modelling Prosody in Context" provides a substantial contribution to prosody modelling in speech synthesis, proving that a bifurcated approach leveraging context and advanced representation learning can close the gap toward natural prosody. Future explorations might involve scaling the model for multi-speaker scenarios and refining context-feature synergy, laying the groundwork for continuous improvements in TTS systems' prosodic output.

