- The paper introduces MONeT, a framework that jointly optimizes memory checkpointing and efficient operator implementations to reduce memory usage in deep networks.
- It leverages 0-1 integer programming to optimize execution schedules, achieving a 3x reduction in memory usage with only a 9-16% increase in computational overhead.
- Experimental results on architectures like ResNet-50 and VGG-16 highlight significant memory savings and practical applicability for training larger models under constrained resources.
Memory Optimization for Deep Networks
This paper, titled "Memory Optimization for Deep Networks," addresses the growing challenge of memory bottlenecks in training deep neural networks due to the slow rate of increase in GPU memory compared to computational advancements. It introduces Memory Optimized Network Training (MONeT), a framework designed to minimize the memory footprint and computational overhead of deep networks by optimizing both global checkpointing schedules and local operator implementations.
Framework Overview
MONeT effectively combines global techniques, like automated checkpointing, with local techniques involving memory-efficient implementations of individual operators. The core idea relies on a theoretical analysis that provides tight bounds on memory consumption for the forward and backward passes, enabling joint optimization of a network's execution plan under a predefined memory budget. Memory bounds are linearized, allowing implementation selection and checkpointing to be expressed as a 0-1 integer program, solvable using standard solvers.
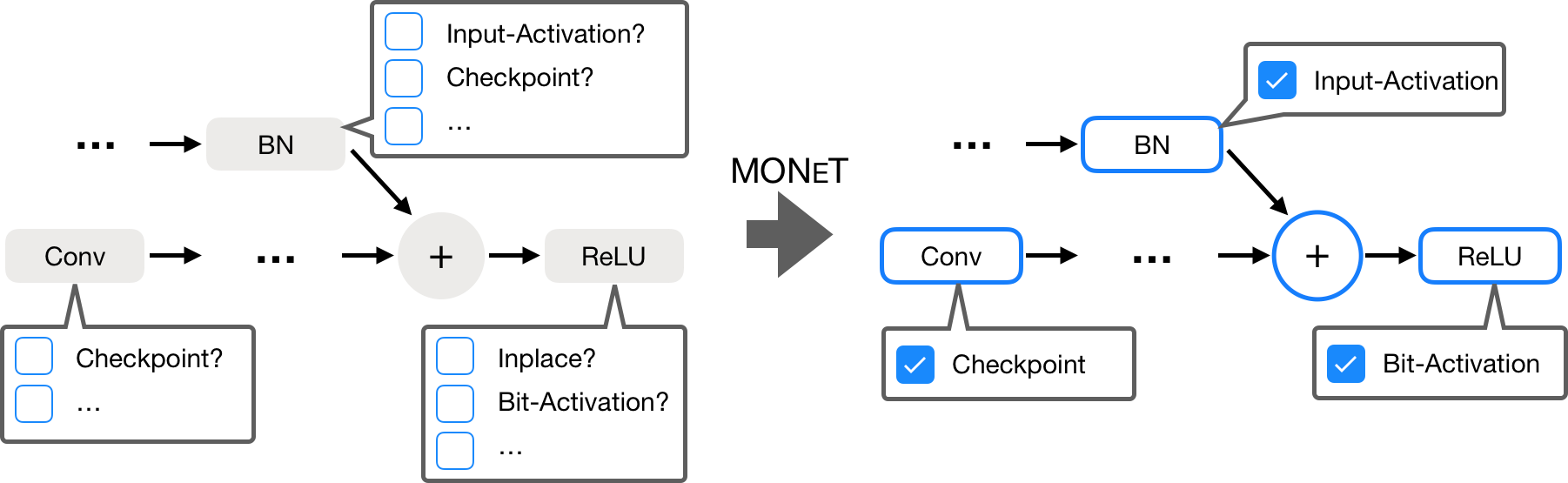
Figure 1: Memory Optimized Network Training (MONeT), an automatic framework that minimizes the memory footprint of deep networks by jointly optimizing global and local techniques.
Implementation Strategies
MONeT's practical application involves several key components:
- Forward and Backward Passes: Algorithms are detailed to include aggressive memory management, freeing unused tensors, and allowing for customized checkpointing schedules. The solution accounts for each operator's workspace memory and execution time, optimizing schedules accordingly.
- Operator Selection: Each operator in the framework can be implemented in various ways, each with different memory and computational trade-offs. MONeT intelligently selects the optimal implementation to minimize peak memory usage.
- Solving with Integer Programming: The challenge of solving the memory optimization problem is addressed via linear programming techniques, leveraging Gurobi, a modern solver, to handle the integer constraints efficiently.
- Handling Constraints: Constraints dictate operational dependencies and resource allocations, ensuring no violations occur during schedule execution. This involves sophisticated logic to guarantee that recomputed and stored tensors are used efficiently without exceeding memory capacity.
Experimental Results
The framework achieves significant memory savings across various common network architectures, such as ResNet-50, VGG-16, and GoogleNet, under different memory constraints. MONeT provides substantial improvements over previous frameworks like Checkmate and Gist, reducing the memory requirement by 3x while maintaining only a 9-16% increase in computational overhead compared to raw PyTorch execution.
- Memory Efficiency: MONeT consistently reduces memory usage by large factors compared to PyTorch, Checkmate, and Gist. It achieves this by intelligently balancing the trade-offs between different operator implementations and checkpointing strategies.
- Computational Overhead: Though memory optimized, MONeT incurs minor overheads, demonstrating the balance between memory savings and computational efficiency.
- Solver Performance: The optimization solver reaches close-to-optimal solutions significantly faster than alternatives, partly owing to its more efficient compact formulation of the computational graph.
Conclusion
MONeT stands out as an effective tool for managing memory constraints in deep learning models, facilitating the training of larger architectures without additional hardware resources. It combines theoretical advancements with practical applications, making it a valuable asset for researchers and practitioners aiming to optimize model training under strict memory budgets. Looking forward, MONeT demonstrates potential as a foundational technique for future adaptive and resource-aware AI systems. This lays grounds for exploring extensions that may involve dynamic scheduling adaptations in response to real-time resource monitoring and management in distributed training environments.

