- The paper introduces a Bayesian selective fusion method that dynamically selects informative reference images for improved visual place recognition in varying conditions.
- The method employs a novel training-free likelihood function to incorporate uncertainty and outperforms traditional fusion techniques, as validated on benchmark datasets.
- The approach enhances autonomous localization by integrating probabilistic inference with sequence matching to adapt to dynamic visual environments.
Intelligent Reference Curation for Visual Place Recognition via Bayesian Selective Fusion
Abstract
Visual Place Recognition (VPR) is a crucial problem in robotics, centered around identifying locations from images despite significant visual changes due to time, season, or weather. Traditional methods involve matching query images with reference images from maps or databases, leveraging deep-learnt descriptors, sequence matching, and fusion techniques. This paper presents a novel Bayesian Selective Fusion approach that dynamically selects and fuses informative reference images to enhance place matching accuracy for given query images. The method employs probabilistic fusion, incorporating uncertainties via a new training-free likelihood function. Demonstrated on challenging datasets, this approach not only surpasses alternative fusion methods but also performs effectively under scenarios typically requiring unfair prior knowledge. Notably, it operates training-free and complements existing methods like sequence matching, making it ideal for long-term robot autonomy in dynamic environments.
Introduction
Visual Place Recognition (VPR) enables mobile robot localization by matching query images with pre-stored reference images. Recent decades have seen advances in techniques for this, such as deep-learnt image descriptors and sequence matching, leading to robust comparison methodologies. Despite these advancements, accurately curating representative reference images for VPR remains challenging, particularly when reference images fail to capture varied appearance due to changing environmental conditions.
This paper proposes Bayesian Selective Fusion, an approach that actively selects the most informative reference images based on dynamic visual conditions to ensure effective place recognition. This is achieved through novel probabilistic tools that integrate uncertainty evaluation without the need for extensive training. Experimental results demonstrate the method's superiority over traditional fusion techniques in scenarios typically handled by highly curated reference sets.
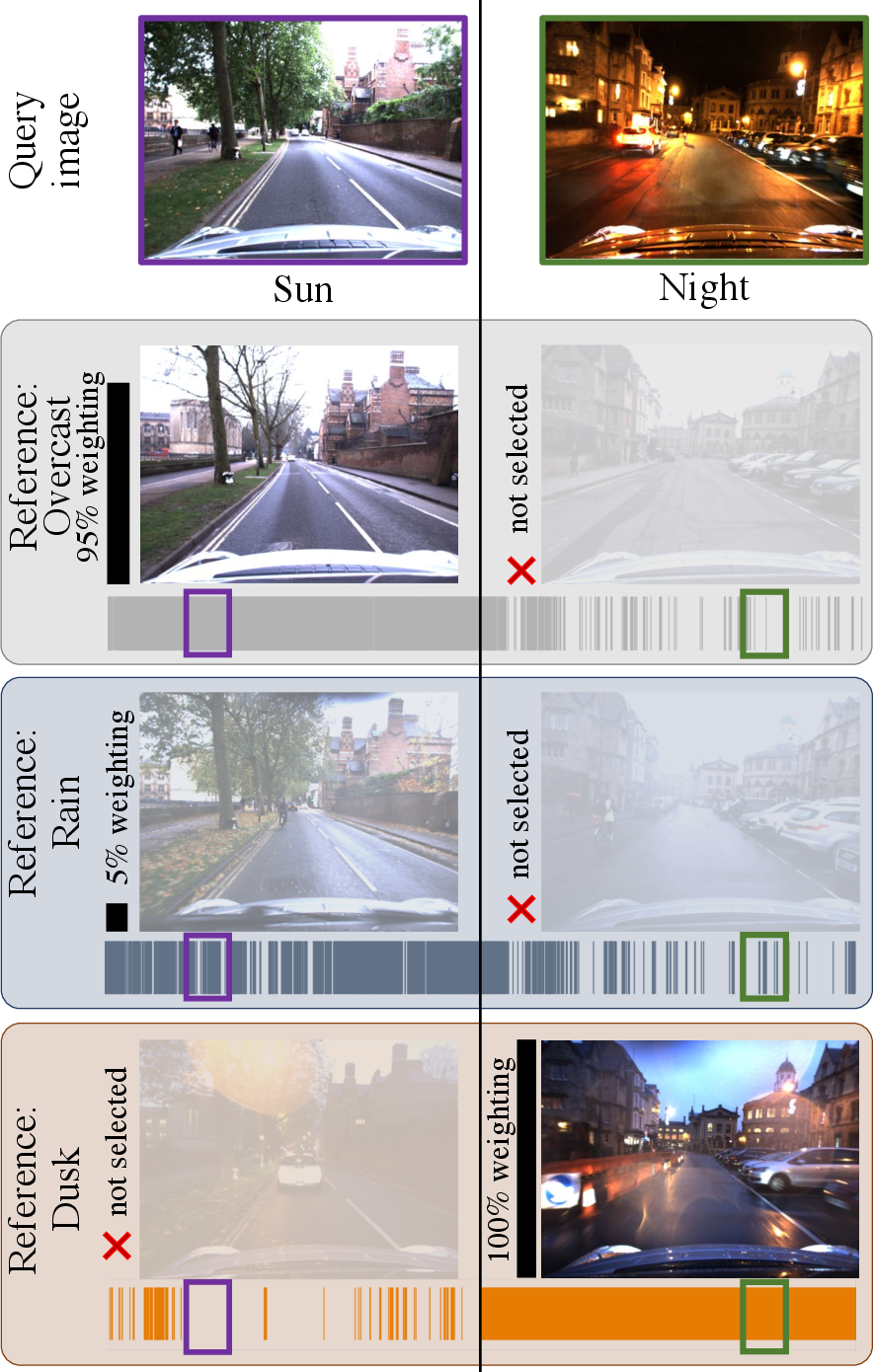
Figure 1: Given a query image, Bayesian Selective Fusion selects and fuses informative reference images to find the best place match.
Methodology
VPR processes involve computing descriptor distances between query images and multiple stored references for accurate place identification. Conventional methods operate on the minimum-value principle, favoring the reference yielding minimal descriptor distance. Such strategies fail under conditions where diverse environmental factors impact image similarity. The minimum ensemble distance approach fuses reference information across several sets, adapting place matching via an averaging mechanism.
This paper hypothesizes that reference set utility fluctuates with environmental changes, warranting a dynamic selection approach. By integrating Bayesian principles, it refines utility evaluation and incorporates uncertainty management, ensuring robust place recognition across dynamic visual conditions.
Reference Set Selection and Bayesian Fusion
The proposed method selects reference sets dynamically by assessing descriptor distances relative to a strategic subset. Reference set incorporation follows Bayesian fusion tactics, where the likelihood of distances informs place recognition. Bayesian inference ensures a probabilistic fusion model, enhancing VPR accuracy by integrating data uncertainty without intensive training phases.
In practical terms, our approach utilizes the independence of descriptor distances for computationally efficient likelihood evaluation. This results in scalable application across diverse datasets, outperforming exhaustive fusion methods that indiscriminately amalgamate all references.
Experimental Evaluation
Dataset Description
Tests were conducted on benchmark Nordland and Oxford RobotCar datasets, representing varied environmental conditions across seasons and times. Images were converted to NetVLAD descriptors, channeling state-of-the-art practices to evaluate performance under challenging visual transitions.
Precision-Recall (PR) curves were employed as primary evaluation metrics, with focus on maximizing accurate place recognitions. Bayesian Selective Fusion showed significant improvement over traditional fusion methods, especially under complex visual transitions.
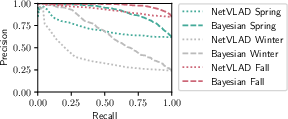
Figure 2: Precision-recall of single-reference (no fusion) Baseline and proposed Bayesian methods on a Nordland Summer query traversal.
Results
Bayesian Selective Fusion consistently outperformed state-of-the-art methods on diverse query traversals, indicating superior reference image utility identification and uncertainty management. From Oxford RobotCar to Nordland datasets, the method excelled despite variations in lighting and environmental obscurity.
With its capacity to integrate sequence matching and other descriptor alternatives, such as DenseVLAD, the approach maintains high adaptability and reliable performance across multiple applications.
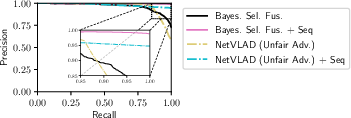
Figure 3: Precision-recall of methods with and without sequence matching on randomized query images from Sun and Night traversals from the Oxford RobotCar dataset.
Conclusion
Bayesian Selective Fusion provides a pragmatic solution to reference image selection in VPR, optimizing the fusion of informative sets through Bayesian data principles while mitigating unnecessary fusion that can result in degraded performance. It promises substantial improvements in visual localization accuracy, particularly crucial for autonomous systems operating in highly dynamic environments. Future research could explore more adaptive sampling and storage optimization to further enhance VPR efficacy in real-world deployments.

