- The paper demonstrates that gradient flow dynamics in sparse networks, rather than initialization alone, are crucial for the success of Lottery Ticket-based pruning.
- It shows that dynamic mask-update methods like RigL enhance gradient propagation and favorably adjust the Hessian spectrum compared to static pruning techniques.
- Empirical results using ResNet-50 and LeNet5 confirm that gradient-aware mask selection leads to improved convergence rates and overall training efficiency.
Gradient Flow in Sparse Neural Networks and How Lottery Tickets Win
Introduction
The paper "Gradient Flow in Sparse Neural Networks and How Lottery Tickets Win" (2010.03533) investigates the dynamics of gradient propagation in sparse neural networks, focusing on the mechanisms underlying the success of Lottery Ticket-based pruning methods. The central thesis is that the ability of sparse subnetworks to train efficiently is determined not only by the initial weight configuration but critically by how gradients propagate through the network during training. The work positions itself as an empirical and theoretical analysis linking gradient flow, mask updating strategies, and training dynamics in settings that emphasize efficiency and scalable learning.
Background on Sparse Neural Networks
Sparse neural networks are created by pruning connections in dense networks, either before or during training, to reduce model size and computational cost. There are numerous pruning strategies, two of which are prominent: static mask pruning and dynamic mask pruning. The Lottery Ticket Hypothesis (LTH) asserts that within a random dense network, there exists a 'winning ticket'—a sparse subnetwork with a specific initialization—that, when trained in isolation, can match or surpass the performance of the original dense model. This hypothesis has driven significant work on understanding mask selection, initialization, and training, but the role of gradient dynamics remains less explored.
Analysis of Gradient Flow in Sparse Networks
The paper provides a detailed analysis of gradient flow across various sparsification paradigms. Using a set of experiments and spectral analysis, it demonstrates that gradient starvation—a phenomenon where certain subnetworks receive disproportionately low gradient magnitudes—can substantially limit the ability of a pruned network to learn. The authors highlight that not all pruning configurations are equally amenable to efficient gradient propagation, and that the topology induced by the sparse mask affects both the spectrum of the Hessian and the distribution of gradient magnitudes within the network.
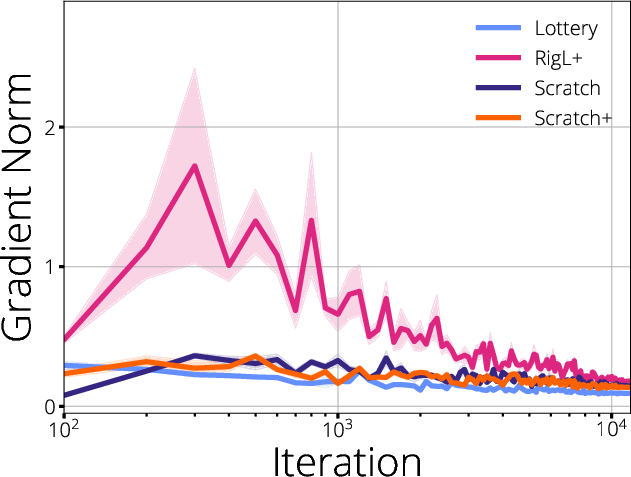
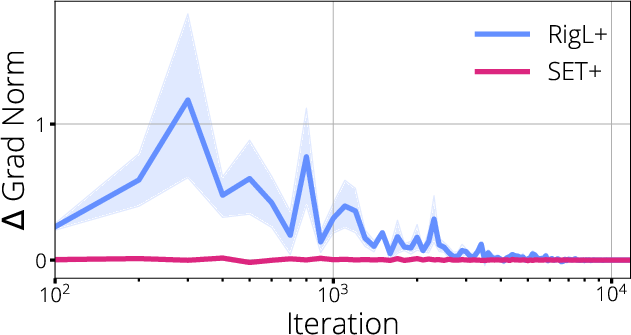
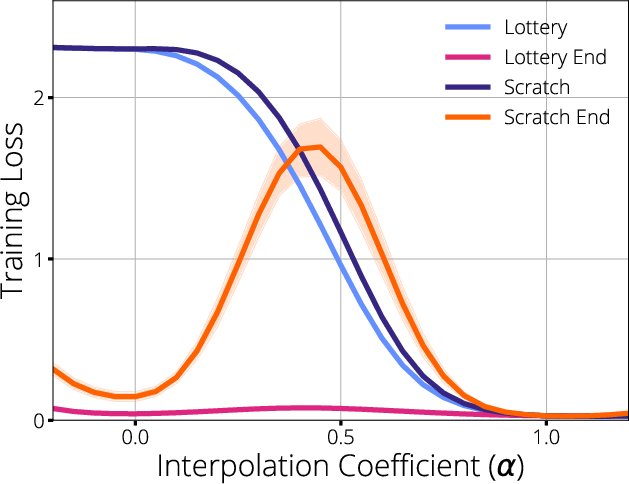
Figure 1: Visualization of gradient flow during training, revealing starvation regions and disrupted propagation in sparse networks.
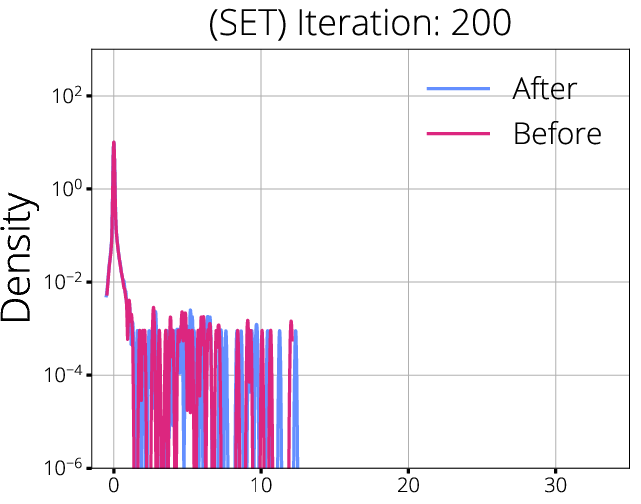
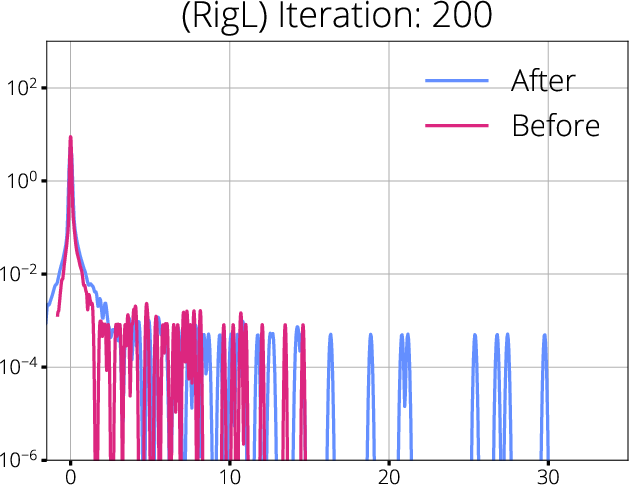
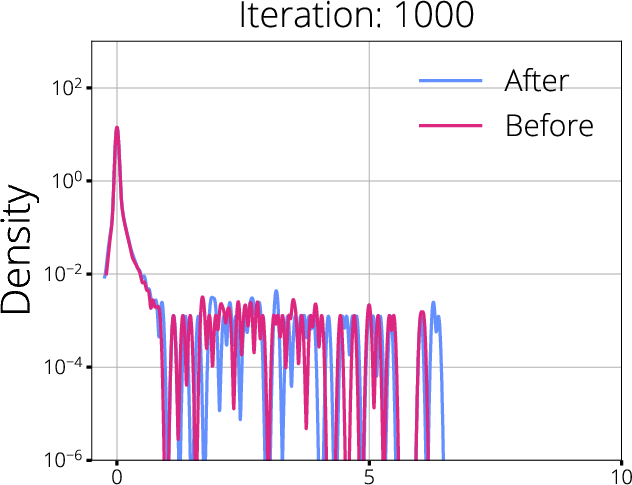
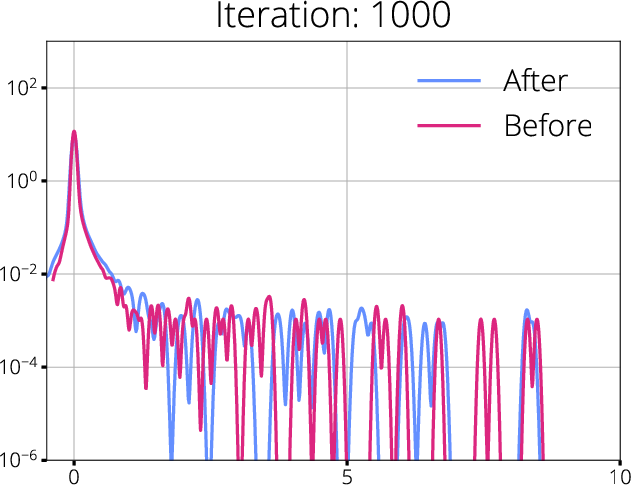
Figure 2: Hessian spectra before and after mask updates for SET and RigL; spectral shifts are indicative of better gradient propagation with dynamic mask updates.
The analysis shows that dynamic sparse training methods, such as RigL, which periodically update the sparse mask based on gradient information, are able to maintain more robust gradient flow compared to static methods like SET. These approaches result in a more favorable Hessian spectrum—reducing degeneracy and increasing the effective rank—while minimizing regions of gradient starvation.
Lottery Ticket Success Mechanisms
The paper substantiates that the primary mechanism behind the Lottery Ticket Hypothesis is not solely the fortunate choice of initial weights, but the preservation and improvement of gradient flow in the subnetwork, particularly when mask selection is coupled with initialization. It is demonstrated that lottery tickets identified at initialization thrive because their connectivity facilitates superior gradient propagation throughout training, enabling faster and more stable convergence.
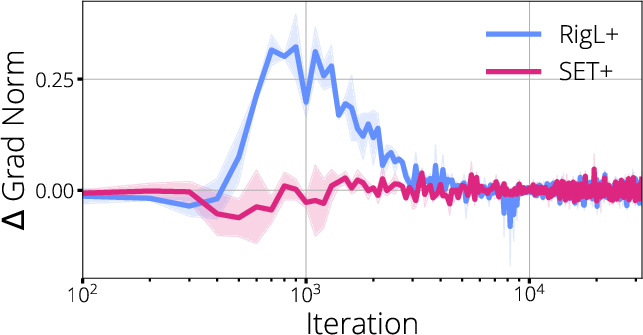
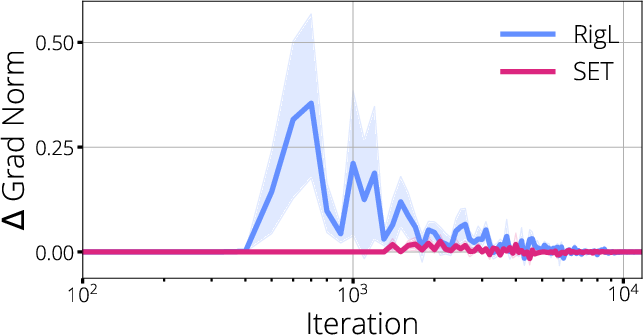
Figure 3: ResNet-50 results showcasing the impact of mask-update strategies on sparse model training dynamics.
The authors further validate these claims using ResNet-50 and LeNet5 architectures, revealing marked improvements in accuracy and convergence rates when masks are selected to maximize gradient localization and flow, as opposed to simply pruning based on magnitude or random heuristics.
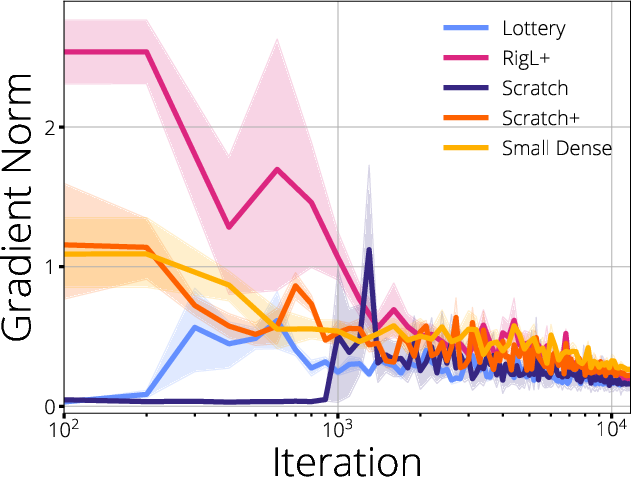
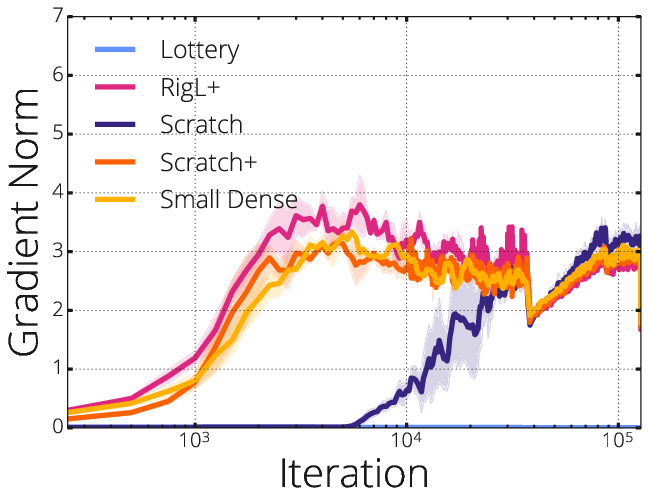
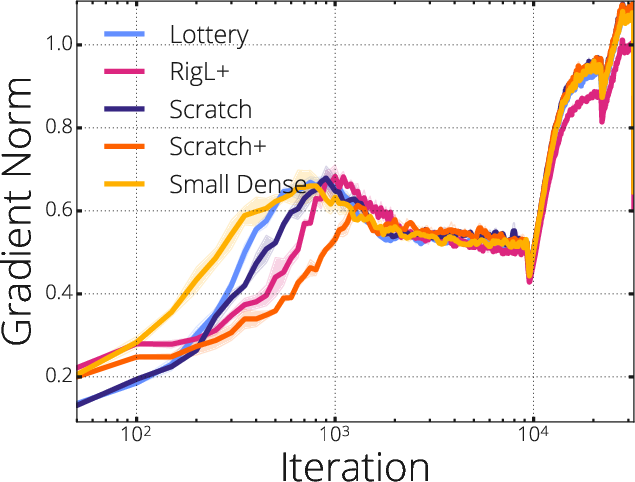
Figure 4: LeNet5 empirical outcomes under diverse pruning and mask-update schemes.
Practical and Theoretical Implications
The findings offer several practical insights:
- Dynamic Mask Updates: Dynamic mask-update schemes such as RigL empirically outperform static alternatives, maintaining better gradient flow and reducing starvation. This demonstrates the necessity of adaptive sparsity mechanisms for robust training.
- Gradient-Aware Mask Selection: Pruning strategies should not only target magnitude but should explicitly consider gradient distribution to optimize training.
- Hessian Spectral Analysis: Spectral features of the Hessian can serve as diagnostic tools for assessing mask quality and predicting sparse network trainability.
Theoretically, the results challenge the common notion that initialization is the dominant factor in subnetwork success, arguing that gradient propagation plays an equally, if not more, critical role. This paves the way for a deeper understanding of how sparse networks learn, and guides future efforts on optimizing mask selection for efficient training.
Speculations on Future AI Directions
The insights from this paper may guide future developments in efficient, scalable deep learning. Gradient flow-aware sparsification techniques could become mainstream, especially in massive models where computational resources are bottlenecked. The coupling of structural sparsity with dynamic mask updates informed by gradient diagnostics might lead to new architectures and training protocols that are both theoretically elegant and empirically superior.
It is plausible that future sparse-training algorithms will integrate spectral monitoring and gradient-based mask refinement as standard features. Additionally, the nuanced link between mask topology and optimization landscape may have implications for transfer learning, federated training, and edge deployments, where resource constraints are paramount.
Conclusion
This paper delivers a rigorous evaluation of gradient flow in sparse neural networks, demonstrating that the efficacy of Lottery Ticket-based subnetworks hinges on superior gradient propagation rather than initialization alone. The empirical results across multiple architectures and mask-update regimes provide strong evidence that dynamic, gradient-aware sparsification strategies are crucial for efficient sparse training. These findings have substantial implications for both theoretical understanding and practical deployment of scalable deep learning models.