- The paper introduces intrinsic probing using a decomposable multivariate Gaussian probe for analyzing how linguistic properties are encoded in specific embedding dimensions.
- It employs a greedy log-likelihood based selection method to identify focal dimensions in BERT and fastText, demonstrating that fastText encodes fewer dimensions with high efficacy.
- Experiments across 36 languages confirm that intrinsic probing reveals cross-linguistic morphosyntactic patterns, enhancing our understanding of neural network interpretability.
Intrinsic Probing through Dimension Selection
The paper "Intrinsic Probing through Dimension Selection" presents a novel approach for exploring how linguistic structures are embedded within neural network representations. This research introduces the concept of intrinsic probing, distinct from the conventional extrinsic probing, focusing on the structure of information in word embeddings rather than mere extractability. It proposes a decomposable multivariate Gaussian probe, facilitating a detailed understanding of the localization and dispersion of linguistic features in word embeddings like BERT and fastText across multiple languages.
Introduction to Intrinsic Probing
Intrinsic probing is designed to investigate not just whether linguistic features can be predicted from embeddings, but how these features are encoded within specific dimensions. This approach can potentially offer insights into which particular neurons or dimensions contribute to encoding linguistic structures. By employing a decomposable Gaussian probe, this method allows for efficient scanning of multiple dimensions concurrently, overcoming the computation-heavy limitations of previous probing techniques.
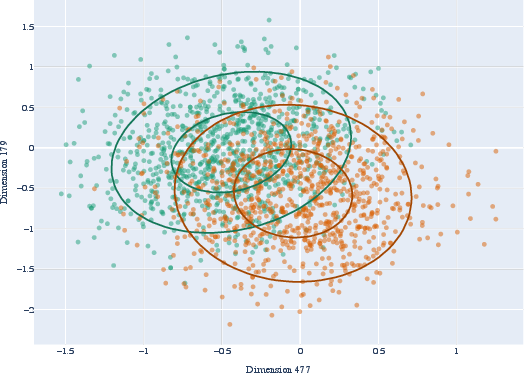
Figure 1: Scatter plot of the two most informative BERT dimensions for English present and past tense.
Recent advancements in neural embeddings have vastly improved NLP tasks, reinforcing the need to clarify the encoded linguistic structures within these embeddings. The goal is to determine if these structures are concentrated in a few dimensions (focal) or spread across many (dispersed).
Technical Framework
The core of the paper is the multivariate Gaussian-based dimension selection framework. This framework involves a probabilistic model that leverages the Gaussian distribution's properties to probe embeddings efficiently.
Decomposable Gaussian Probe
The Gaussian distribution's natural decomposability makes it suitable for intrinsic probing, allowing a single trained model to probe various subsets of dimensions without retraining. This decomposability is paramount given the high dimensionality of models like BERT, which encompasses 768 dimensions.
Given the task involves identifying dimensions relevant to morphosyntactic properties, the probe evaluates the likelihood of word representations corresponding to specific linguistic features under different dimensional subsettings.
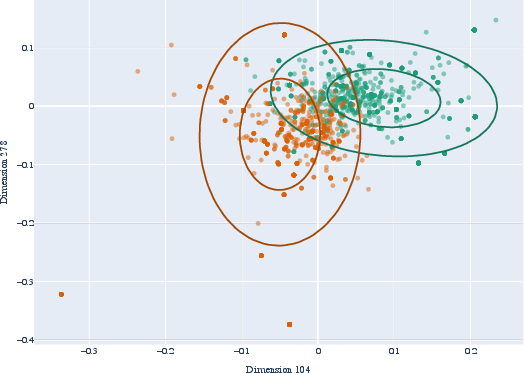
Figure 2: Scatter graph of two most informative fastText (above) and BERT (below) dimensions for English present and past tense.
Dimension Selection Strategy
The authors employ a greedy selection metric based on log-likelihood to choose dimensions with the most significant contribution to predicting linguistic properties. The approach counters potential overfitting by evaluating subsets of dimensions, ensuring robustness in identifying informative neurons.
Experimental Setup
Experiments span 36 languages using both fastText and BERT embeddings. The study evaluates various morphosyntactic attributes, including number, gender, tense, and case, marking an extensive cross-linguistic assessment of focal vs. dispersed encoding in embeddings.
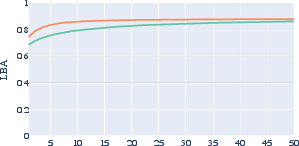
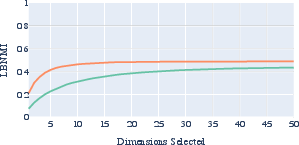
Figure 3: The average lower-bound accuracy (LBA) and lower-bound normalized mutual information (LBNMI) across all evaluated attributes and languages for fastText and BERT.
Gaussian-inverse-Wishart priors are used to estimate parameters within the Bayesian framework, which aids in handling data with fewer dimensions than samples, preventing degeneracy in the Gaussian estimates.
Results
The results indicate that fastText generally concentrates linguistic information in fewer dimensions compared to BERT, suggesting a higher degree of focal encoding in fastText embeddings. fastText's performance stabilizes around 10 dimensions, while BERT requires approximately 35 for similar efficacy.
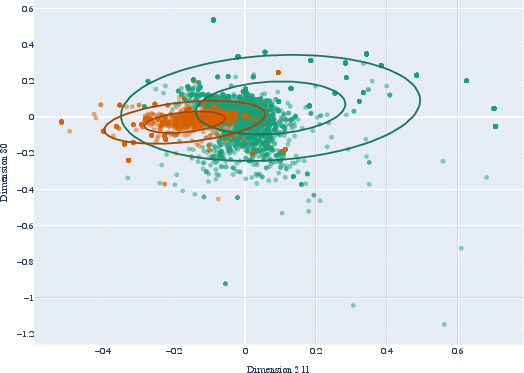
Figure 4: Two fastText dimensions informative for Portuguese number, not jointly Gaussian.
Limitations and Future Work
The assumption of Gaussian distribution in embeddings poses limitations, as embeddings may not naturally follow this distribution, affecting the mutual information bounds. Future improvements could involve using more sophisticated models of embeddings' distributions to refine the probing framework.
The research emphasizes the importance of understanding intrinsic structure in embeddings, paving the way for enhanced model interpretability and linguistic analysis. Future work may extend these probing techniques to other linguistic or neural tasks, refining and expanding the toolkit available for analyzing neural network representation internals.
Conclusion
The decomposable intrinsic probing framework provides a robust, scalable method to analyze the internal structure of NLP embeddings. By highlighting how morphosyntactic properties manifest across languages and models, this study offers valuable insights into the mechanics of word embeddings and lays the groundwork for future exploratory studies in neural network interpretability and linguistic representation.