- The paper introduces CAMNet, which integrates self-supervised learning with confidence-aware refinement and adversarial training to boost semantic matching accuracy.
- It employs a modular design with base correspondence, confidence estimation, and refinement networks that collectively improve keypoint matching in complex scenes.
- Experimental results reveal significant improvements in PCK scores on PF-WILLOW and PF-PASCAL, showcasing the framework’s robustness against background clutter and intra-class variations.
Confidence-aware Adversarial Learning for Self-supervised Semantic Matching
Introduction
The paper "Confidence-aware Adversarial Learning for Self-supervised Semantic Matching" addresses semantic matching, a core problem in computer vision involving aligning object instances within the same category. Existing methods face challenges such as background clutter, severe intra-class variation, and viewpoint changes. Traditional approaches require strong supervision via ground truth correspondences, which are costly and difficult to obtain on large datasets. The paper introduces a Confidence-Aware Semantic Matching Network (CAMNet) integrating self-supervised learning and adversarial learning techniques to enhance semantic matching accuracy.
Methodology
CAMNet comprises three key components: a Base Correspondence Network, a Confidence Estimation Network, and a Confidence-aware Refinement Network. The integration of these components allows for self-supervised adversarial learning of semantic matching.
Base Correspondence Network: This module generates an initial dense correspondence prediction from input images by computing a correlation map between feature maps of the images. The network is designed to predict an initial semantic flow between images using convolutional neural networks, notably leveraging ResNet-101 as a feature extractor.
Confidence Estimation Network: This component estimates the confidence of predictions, identifying correct correspondences in the initial dense prediction. It produces a pixel-wise confidence map, serving as a reliability guide for refining initial predictions.
Confidence-aware Refinement Network: This network refines initial flow predictions by using the confidence map to propagate reliable matching information. This refinement process mitigates errors in initial predictions and improves overall accuracy.
Additionally, an innovative adversarial training module enhances the semantic alignment by enforcing global consistency on predictions. This module uses a discriminator to distinguish between source images warped by ground-truth alignments and those by predicted alignments. The overall architecture and methodology are depicted in the corresponding figure.
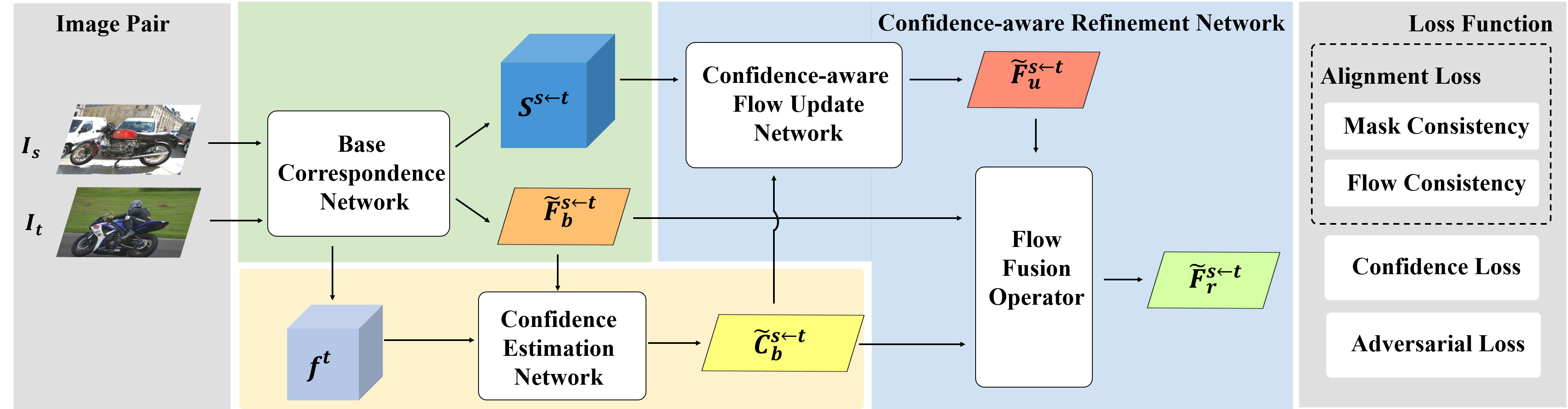
Figure 1: Overview of the Confidence-aware Semantic Matching Network.
Experimental Results
The paper evaluates CAMNet on two standard benchmarks: PF-WILLOW and PF-PASCAL. Results demonstrate superior performance over previous state-of-the-art methods, including those employing strong supervision. CAMNet exhibits improvements in keypoint matching precision, particularly in challenging conditions involving background clutter and intra-class variations.
In quantitative terms, CAMNet outperforms competing methods in PCK (Probability of Correct Keypoint) scores. On PF-WILLOW, it achieves scores of 46.4%, 74.6%, and 86.3% at thresholds of 0.05, 0.10, and 0.15, respectively. On PF-PASCAL, it achieves 54.9%, 83.5%, and 91.0% at the same thresholds, illustrating its robustness and effectiveness.

Figure 2: (a) Alignment examples on PF-WILLOW from our model. (b) Qualitative comparisons on PF-PASCAL. We show the ground truth and predicted keypoints in squares and dots respectively, with their distance in target images depicting the matching error.
Implications and Future Directions
The introduction of confidence-aware refinement and adversarial learning to self-supervised semantic matching presents a substantial advancement in handling matching ambiguities without extensive labeled data. The ability to generate confidence-informed correspondences autonomously can reduce the dependency on costly human annotations, thereby accelerating advancements in object recognition and related applications.
Future developments could explore the extension of this framework to more complex scenes involving dynamic objects and varying lighting conditions. Another promising avenue lies in enhancing the discrimination network to handle more intricate deformations and transformations, potentially through integration with other deep learning paradigms such as transformer architectures.
Conclusion
The paper presents a novel framework for self-supervised semantic matching by unifying confidence estimation and adversarial learning. CAMNet's ability to exploit confidence information and adversarial signals provides a significant edge over existing methods, as validated by its top performance on public benchmarks. This work paves the way for more efficient semantic correspondence systems that can operate with minimal human supervision and deliver high accuracy in diverse real-world environments.