- The paper introduces a novel generalized deformable convolution method (GDConv) that overcomes conventional kernel rigidity to handle complex spatio-temporal motion.
- It integrates key modules such as the Source Extraction Module, Context Extraction Module, and Generalized Deformable Convolution Modules to enhance accuracy and efficiency in synthesizing intermediate frames.
- Experiments demonstrate improved video frame interpolation quality by leveraging adaptive spatio-temporal sampling and diverse numerical interpolation techniques.
The paper "Video Frame Interpolation via Generalized Deformable Convolution" (2008.10680) introduces a novel approach to video frame interpolation (VFI) leveraging generalized deformable convolution (GDConv). This advanced convolution technique aims to overcome the limitations inherent in traditional flow-based and kernel-based video frame interpolation (VFI) methods, offering a more robust solution for handling complex motion scenarios in video sequences.
Introduction
Recent advancements in hardware capabilities and the availability of large-scale image and video datasets have significantly advanced the field of computer vision, including VFI. VFI involves creating intermediate frames from adjacent frames, preserving the spatial and temporal consistency. Existing methods largely fall into two categories: flow-based and kernel-based approaches. Flow-based methods often suffer from inaccuracies in flow map estimation owing to oversimplified motion models. This issue persists despite the utilization of more sophisticated approaches like quadratic motion models, which attempt to capture latent motion information. Kernel-based methods, despite circumventing flow map estimation, often face limitations due to the rigidity in kernel shape, which restricts their capacity to handle diverse motion patterns.
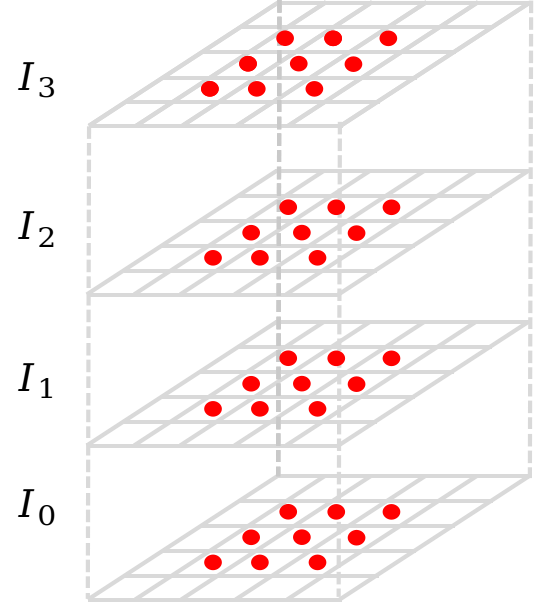
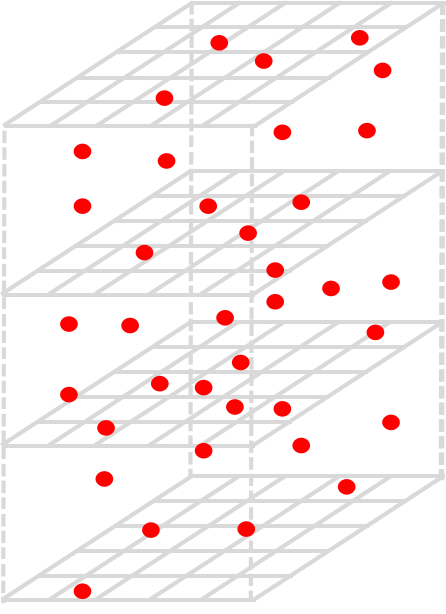
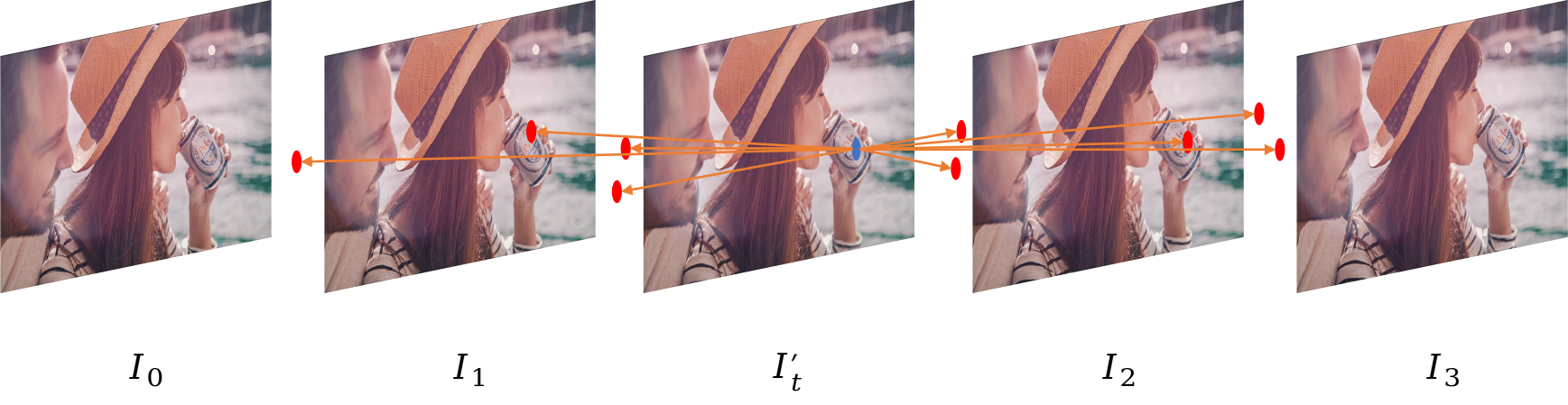
Figure 1: Illustration of a) conventional convolution with 3×3×4=36 sampling points, (b) GDConv with the same number of sampling points, and (c) visualization of interpolating one frame with GDConv.
The proposed method introduces the Generalized Deformable Convolution Network (GDConvNet), which efficiently utilizes generalized deformable convolution (GDConv) for VFI. GDConv overcomes the rigidity of kernel shape found in conventional convolution methods by allowing flexible spatio-temporal sampling point selection. Consequently, it provides freedom in choosing sampling points across the spatio-temporal domain.
Figure 1: Illustration of (a) conventional convolution with 3 \times 3 \times 4 =36 sampling points, (b) GDConv with the same number of sampling points, and (c) visualization of interpolating one frame with GDConv.
The architecture of GDConvNet integrates key modules, including the Source Extraction Module (SEM), Context Extraction Module (CEM), and two Generalized Deformable Convolution Modules (GDCM). The architecture is efficient in generating intermediate video frames, as shown in Figure 2, which depicts the architecture of GDConvNet for the synthesis of an intermediate frame from a given video clip of sequential source frames.
Figure 3: Illustration of the architecture of GDConvNet with T=3. Here I0,⋯,I3 are input frames, C0,⋯,C3 are respective context maps, and modulation terms are represented by △mn, facilitating adaptive parameterization.
GDConv, illustrated in Fig.~\ref{fig:convolution}, introduces an innovative approach that permits the selection of sampling points across both the spatial and temporal domains, thereby enhancing its ability to handle variable motion ranges and patterns.
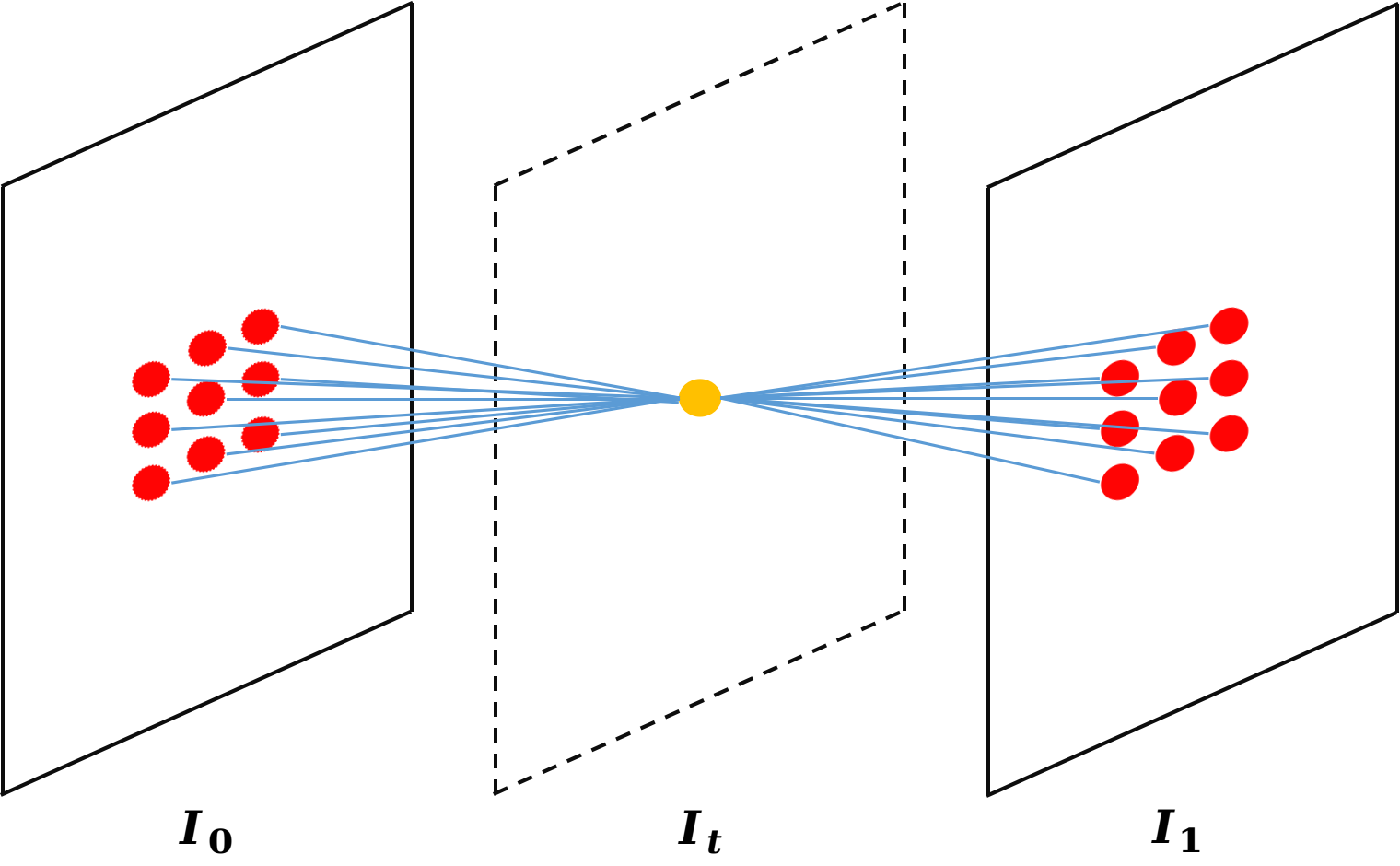
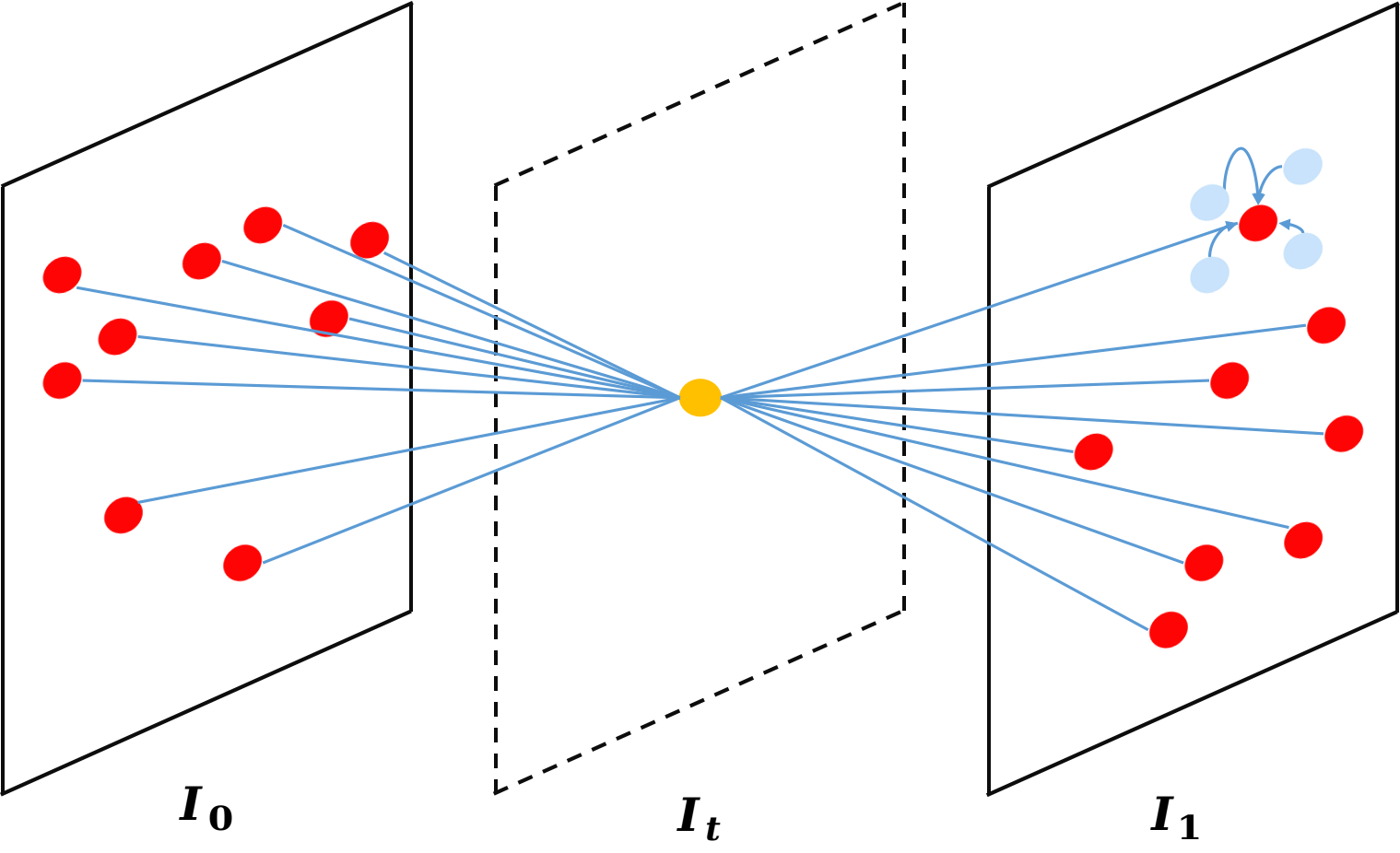

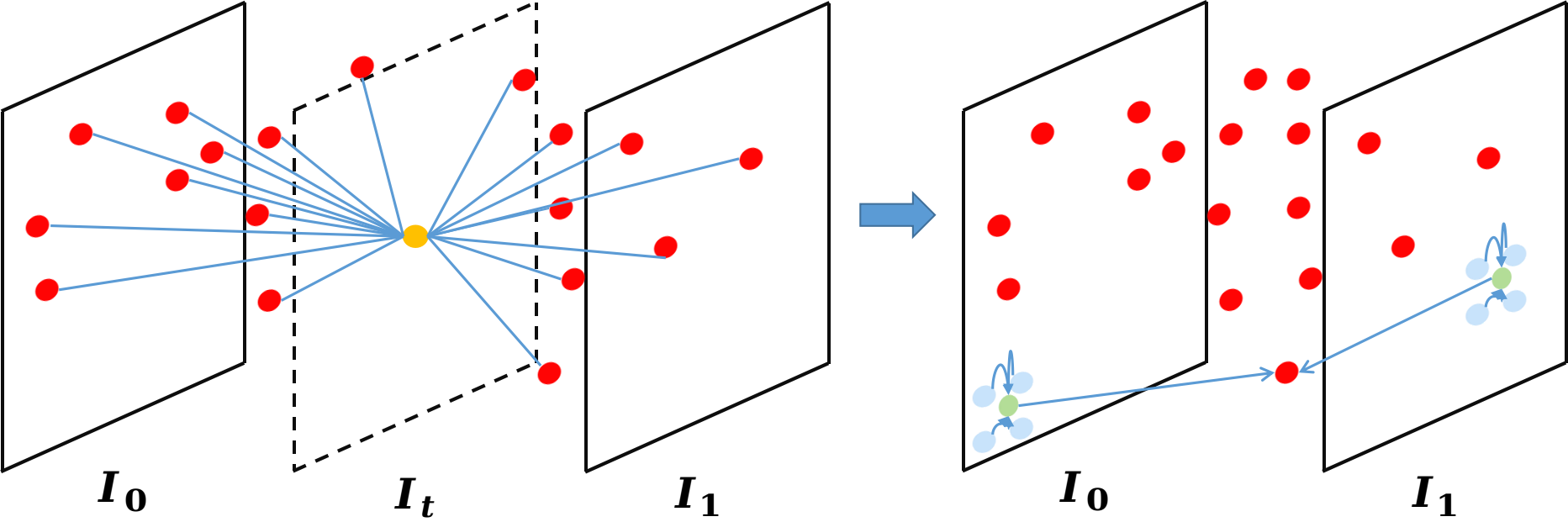
Figure 4: Illustration of (a) conventional convolution, (b) AdaCoF, (c) basic GDConv, (d) advanced GDConv with T=1, demonstrating superior sampling adaptability.
Unlike AdaCoF, which only addresses spatial adaptability via spatially-adaptive deformable convolution, GDConv extends this adaptability to the full spatio-temporal domain. This is achieved by allowing sampling points to reside continuously within space-time, without predefined constraints on kernel shape.
Figure 4: Illustration of sampling methodologies in different convolution mechanisms.
Sampling Points in Space-Time
GDConv associates each sampling point with temporal and spatial parameters. For a particular pixel in the intermediate frame to be synthesized, sampling points with adaptive positions in both space and time are selected for interpolation. This strategy permits handling complex inter-frame motions, including large, non-linear transformations, which are typically a challenge for other methods like AdaCoF.
Figure 4: Illustration of (a) conventional convolution, (b) AdaCoF, (c) basic GDConv, (d) advanced GDConv with T=1, demonstrating differences in pixel, sampling, and support points.
Numerical Interpolation Methods
The technique relies on a numerical interpolation function G, which determines the transfer of information from support points to sampling points within GDCM when sampling points don't align with integer-valued time frames. The choice of the interpolation strategy is significant, which influences the quality of VFI.




Figure 5: Visualization of failure cases.
Experiments illustrate the performance enhancements of applying different interpolation functions. From linear to 1D inverse distance weighted interpolation, to polynomial interpolation, each different method provided different quantitative results on datasets (Table 4 and Table 5). In particular, polynomial interpolation enhanced the quality of synthesized frames due to its ability to extrapolate beyond support point limits, as visualized in Fig. 11.
Implications and Future Work
The introduction of GDConv in VFI not only provides a new avenue for overcoming long-standing challenges in the field but also suggests potential applications in various video processing tasks. These may include advanced video super-resolution and image enhancement tasks that benefit from the flexible learning of motion trajectories inherent in GDConv.
In summary, the paper presents significant advancements in VFI by offering generalized deformable convolution, which unifies and enhances existing methodologies. Future research could explore the broader applicability of GDConv across other video-related domains, optimizing the interpolation functions, and integrating with cutting-edge deep learning frameworks for further improvements in computational efficiency and output accuracy.

