- The paper introduces low rank matrix factorization in Transformer models to fuse multimodal signals efficiently, reducing computational complexity.
- It proposes two architectures, LMF-MulT and Fusion-Based-CM-Attn-MulT, which use modality-specific and cross-modal attention mechanisms.
- Experimental evaluation on CMU-MOSEI, CMU-MOSI, and IEMOCAP shows comparable performance with significantly lower parameters and training time.
Introduction
The paper "Low Rank Fusion based Transformers for Multimodal Sequences" introduces novel architectures leveraging Transformer models with a focus on reducing complexity via low-rank matrix factorization. The primary goal is to enhance the computational efficacy of multimodal sequence processing in the domain of sentiment and emotion recognition. The core innovation is the employment of Low Rank Matrix Factorization (LMF) to realize a systematic fusion of multimodal signals while minimizing parameter requirements of the Transformer architecture. This approach is inspired by prior work (2007.02038) that explored multimodal signal interaction, emphasizing the cost-effectiveness of managing unimodal, bimodal, and trimodal interactions in emotion understanding tasks.
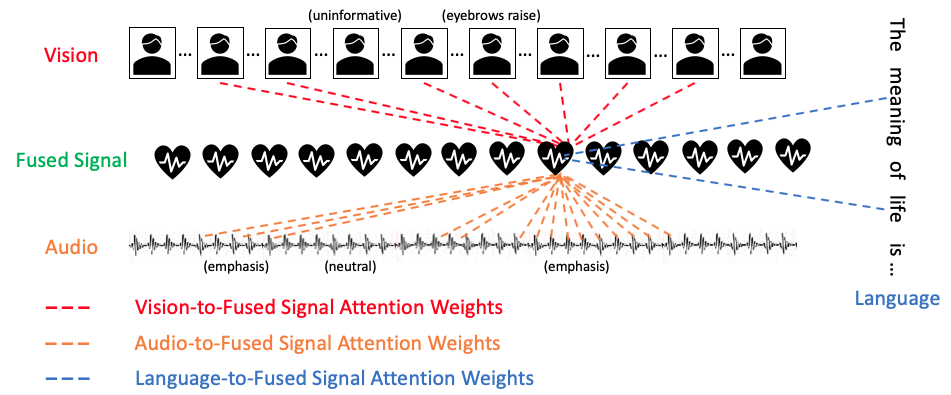
Figure 1: Modality-specific Fused Attention.
Model Overview
Low Rank Fusion
Low Rank Matrix Factorization (LMF) in this paper is utilized to decompose tensor representations effectively, capturing interactions between different modalities without the need for computationally expensive outer product operations. By using modality-specific embeddings and appended features, LMF provides a compressed representation suitable for multimodal processing. This method is particularly significant for large feature spaces where traditional Cartesian product methods are impractical due to prohibitive resource demands.
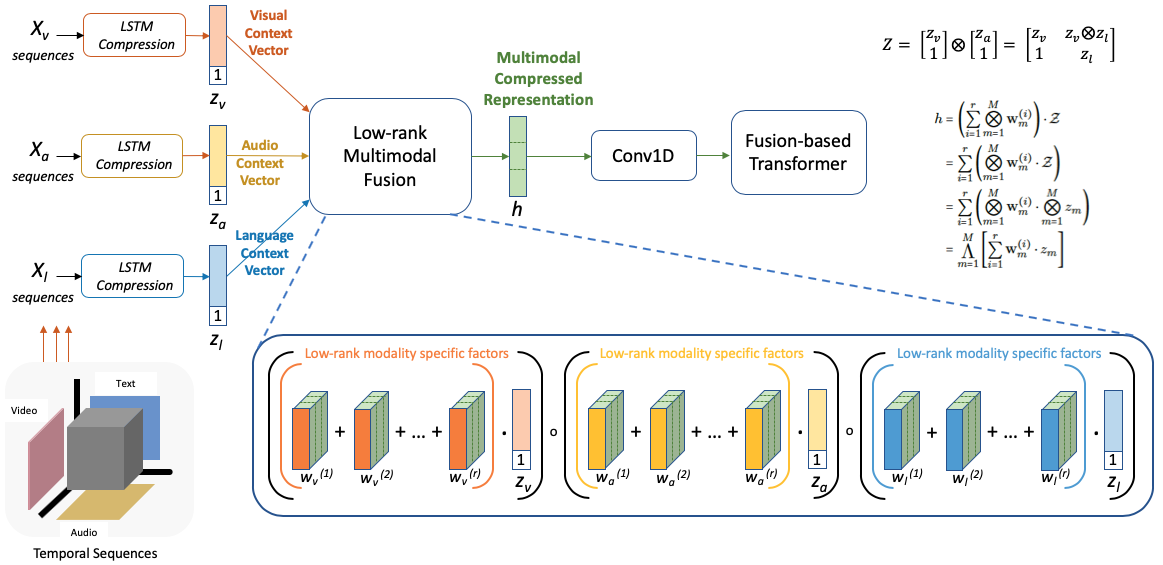
Figure 2: Low Rank Matrix Factorization.
The authors propose two models: LMF-MulT and Fusion-Based-CM-Attn-MulT. Both models integrate the LMF strategy within Transformer frameworks but differ in their attention mechanisms. In LMF-MulT, a fused multimodal signal is subjected to attention from individual modalities. Conversely, Fusion-Based-CM-Attn-MulT flips this approach, incorporating cross-modal attention to enrich the fused signal using inputs from unimodal sequences. These configurations aim to reduce over-parameterization common in current Transformer-based multimodal systems.
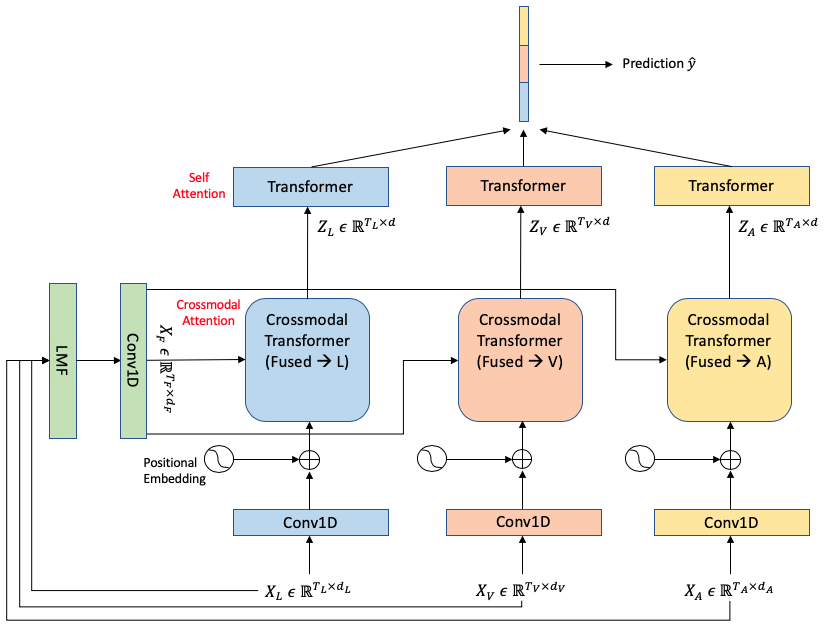
Figure 3: Fused Cross-modal Transformer.
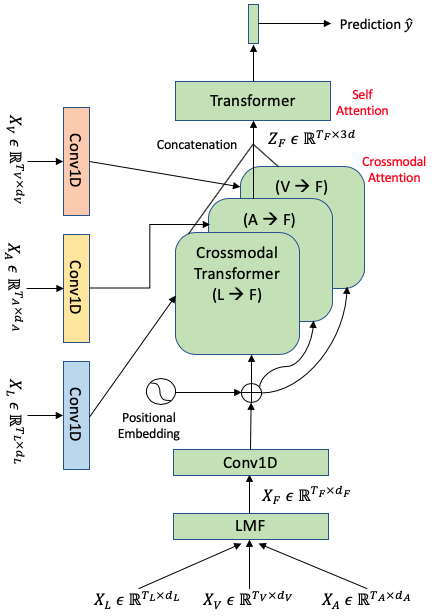
Figure 4: Low Rank Fusion Transformer.
Experimental Evaluation
The paper presents experimental results on benchmark datasets such as CMU-MOSEI, CMU-MOSI, and IEMOCAP, focusing on sentiment and emotion recognition tasks. The proposed models were compared to the traditional Multimodal Transformer approach. Results indicate that while performance metrics (accuracy, F1-score) of the proposed models are comparable to the benchmarks, they demonstrate a significant reduction in parameters and training time.
Both aligned and unaligned data scenarios were considered, showcasing the robustness of the proposed architectures in non-sequential multimodal contexts. Despite some fidelity lost in specific settings, the implications of reduced computational overhead and faster training cycles present compelling benefits for deploying multimodal models in resource-constrained environments.
Conclusion
This paper contributes to the multimodal processing landscape by introducing efficient, scalable models capable of handling complex signal interactions with lower computational cost. The use of low-rank fusion within Transformer architectures is poised to influence how multimodal data is processed, offering pathways to deploy these models in practice, particularly where resource constraints are a key consideration.
Further development and optimizations like richer feature extraction and sequence processing could extend these models' usability to broader applications in emotional AI ecosystems. The experimental results provide a foundation for future research aiming to balance complexity, performance, and resource consumption in multimodal machine learning.
In summary, this work provides an insightful approach to addressing the challenges of multimodal sequence representation and paves the way for practical implementations with optimized computational benefits.

