- The paper demonstrates the integration of a dense retriever with a seq2seq generator to enhance factual accuracy.
- It presents two RAG formulations (RAG-Sequence and RAG-Token) that balance consistency and flexibility in language generation.
- RAG models achieve state-of-the-art results on open-domain QA benchmarks, outperforming traditional extractive methods.
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
The paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" investigates the limitations of large pre-trained LLMs in accessing and manipulating knowledge, especially for tasks requiring intensive knowledge. It introduces Retrieval-Augmented Generation (RAG), which combines pre-trained parametric and non-parametric memory for enhanced language generation capabilities.
Introduction and Approach
Large neural LLMs, despite achieving state-of-the-art results on many NLP tasks, have constraints such as limited ability to expand or revise memory and issues with knowledge provenance. RAG addresses these challenges by integrating a retrieval mechanism with a sequence-to-sequence (seq2seq) generation model. The non-parametric component acts as a dense vector index of Wikipedia, accessed via a pre-trained neural retriever (DPR). The seq2seq generator, specifically BART, then uses these retrieved passages as latent variables in a probabilistic model to generate highly factual, diverse, and specific language.
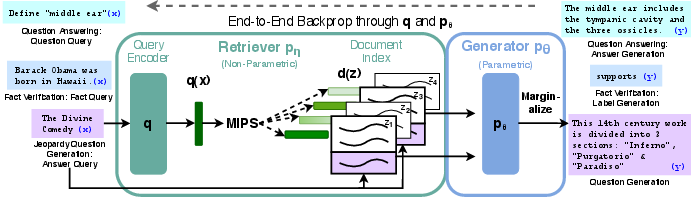
Figure 1: Overview of our approach. We combine a pre-trained retriever~(Query Encoder + Document Index) with a pre-trained seq2seq model (Generator) and fine-tune end-to-end. For query x, we use Maximum Inner Product Search (MIPS) to find the top-K documents zi. For final prediction y, we treat z as a latent variable and marginalize over seq2seq predictions given different documents.
Models and Methods
RAG explores two primary formulations: RAG-Sequence and RAG-Token. RAG-Sequence maintains consistency by using the same retrieved document for generating the entire output sequence, while RAG-Token allows flexibility by permitting different documents for each token prediction. This methodology innovatively addresses the complexity of handling retrieval in generation tasks.
The retriever is based on a bi-encoder architecture from DPR, utilizing BERT\textsubscript{BASE} for producing dense document and query representations. The Maximum Inner Product Search (MIPS) aids in retrieving the relevant documents in sub-linear time.
The generator leverages BART-large, a pre-trained encoder-decoder transformer that models knowledge-intensive tasks by interpolating the input with the retrieved content.
Experimental Results
RAG models achieved state-of-the-art performance on open-domain QA tasks such as Natural Questions, WebQuestions, and TriviaQA, surpassing both parametric-only and task-specific architectures. RAG models demonstrated enhanced performance in language generation tasks, providing more factual, specific, and diverse responses than BART baselines.
(Table 1)
Table 1: Open-domain QA performance metrics, highlighting RAG-Sequence's state-of-the-art results.
In error analysis, it was noted that even when no appropriate documents were retrieved, RAG models could generate correct answers, a significant advancement over extractive models restricted to verbatim extraction from text.
Implications and Future Work
The research presented in this paper highlights the advantages of combining parametric and non-parametric memories in NLP models, demonstrating their applicability across various domains such as QA and generation tasks without relying on task-specific architectures. The findings open avenues for further refinement of hybrid models and exploration of new pre-training objectives that could pre-train both components jointly.
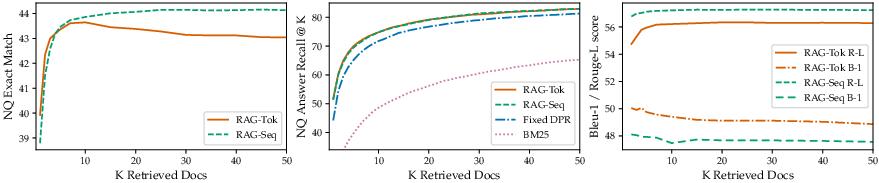
Figure 2: NQ performance as more documents are retrieved, illustrating the model's ability to improve accuracy with increased document retrieval.
Future work may include developing methods that optimize the interplay between these two memory types to further enhance performance on tasks where pre-trained, end-to-end learning offers significant potential.
Conclusion
The paper makes a compelling case for the efficacy of retrieval-augmented generation models in improving linguistic tasks by endowing models with access to external, contextually relevant knowledge. The ability to update non-parametric memory dynamically without retraining signifies a considerable advancement for adaptable and interpretable AI systems, enabling them to perform more robustly in dynamically changing real-world environments.

