- The paper presents a novel dataset for document-level information extraction that leverages semi-automatic annotation with expert corrections to ensure high-quality data.
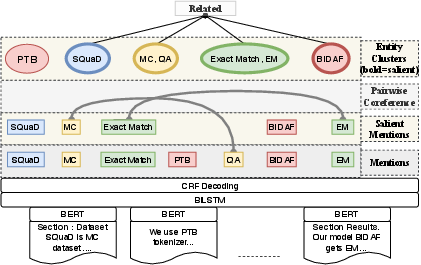
- It details a neural model combining SciBERT and BiLSTM to extract entities and relationships across entire scientific documents, addressing challenges in coreference and saliency detection.
- Experimental results show improved recall in document-level entity clustering while highlighting the need for enhanced methods to capture global context.
Introduction
"SciREX: A Challenge Dataset for Document-Level Information Extraction" introduces a dataset geared towards advancing document-level information extraction (IE) in the field of NLP. While traditional IE datasets focus on sentence or paragraph-level data, this work addresses the complex task of extracting coherent information from entire scientific documents, where relationships often extend beyond individual sentences or sections.
The SciREX dataset integrates multiple IE tasks, including salient entity identification and document-level N-ary relation extraction, drawing inputs from a range of ML scientific articles. This dataset also includes annotations that are enriched through a blend of automatic and manual techniques, leveraging established scientific resources.
Dataset Construction
One of the challenges in creating a document-level IE dataset is the extensive domain knowledge required to annotate content spanning full documents. SciREX circumvents this problem by adopting a semi-automatic annotation approach that blends automatic labeling with expert manual corrections. Initial automated labeling is carried out using a sequence labeling model trained on the SciERC dataset. Human annotators then correct these labels, ensuring high-quality data.
Papers with Code (PwC) serves as a distant supervision signal. PwC's annotations of result tuples (Dataset, Metric, Method, Task, Score) enable SciREX to leverage this information to enrich its dataset, even though exact mention locations of these tuples within documents are not originally provided.
Model Architecture
The baseline model employs a neural architecture that jointly addresses several tasks required for the end-to-end IE on full documents. A two-tier architecture is used where section-wise token embeddings are first obtained using SciBERT, followed by BiLSTM to incorporate document-level context.
Experimental Results
Performance is gauged on two fronts: component-wise and end-to-end outcomes. Component-wise testing uses ground truth inputs for each task to evaluate their standalone efficacy. The critical barrier identified is the difficulty in identifying salient clusters, essential for high fidelity in relation detection tasks.
The model demonstrates greater recall on document-level entity clustering tasks compared to sentence-level, showing its capacity for cross-contextual analysis. However, challenges are pronounced in tasks like identifying salient mentions, highlighting the need for models that better understand document-level context and relevance.
Implications and Future Directions
SciREX sets a platform for the development of sophisticated document-level IE models that must manage extended contexts and intricate entity relationships. Future work will need to address:
- Handling of large token sequences in transformers.
- Enhanced methods for document-centric saliency detection.
- Exploration of N-ary relation extraction methods to efficiently aggregate wider document contexts.
Conclusion
The introduction of SciREX represents a significant step towards comprehensive document-level information extraction. While the baseline model provides a strong foundation, several challenges remain in achieving robust end-to-end document-level IE. The dataset promises to push boundaries in IE research, especially in terms of handling complex relationships and salient information spanning entire documents.