- The paper presents a method to imitate black-box MT systems using query outputs, achieving imitation models with BLEU scores within 0.6 of the original systems.
- It demonstrates that gradient-based adversarial examples can transfer to production systems, triggering token flips and significant translation errors.
- It introduces a defense strategy via output modification, offering a practical trade-off that maintains translation quality while deterring imitation.
Imitation Attacks and Defenses for Black-box Machine Translation Systems
This essay explores the intricacies of imitating and attacking black-box machine translation (MT) systems, as explored by the authors. These systems, often accessible through APIs, are susceptible to misuse due to their value and the significant investment in their development. The study investigates both model stealing and adversarial attacks against these systems and proposes strategies to defend against such exploits.
Model Imitation: Strategy and Evaluation
The research outlined in the paper details a method to imitate MT models through access to their output translations. Utilizing a corpus of monolingual sentences, the authors queried a target black-box MT system and collected the generated translations. These pairs were then used to train imitation models, analogous to the process of knowledge distillation.
Notably, the paper demonstrates the high fidelity with which these imitation models replicate the behavior of the victim MT models. Even when using different architectures or out-of-domain data, the imitation models achieved BLEU scores within 0.6 of the target systems, such as those from Google and Bing.
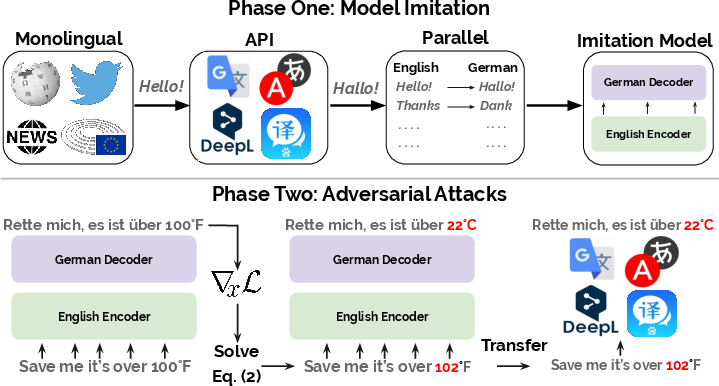
Figure 1: Imitating and attacking an English-to-German MT system; demonstrating model imitation and adversarial transfer to production systems.
Adversarial Attacks: Implementation and Implications
The paper describes the generation of adversarial examples using gradient-based methods with the imitation models. These adversarial inputs are crafted to transfer effectively to the original production systems. The attacks include targeted token flips and input perturbations resulting in erroneous translations, demonstrating significant susceptibility of state-of-the-art MT systems.
For instance, minor perturbations in input can lead production systems to alter meaning significantly, as demonstrated with specific target flips such as changing "22°C" to "72°F."
Defensive Measures: Strategies and Efficacy
To mitigate vulnerabilities exposed by imitation and adversarial attacks, the authors developed a defensive strategy that employs translation output modification. This approach aims to misdirect the training of potential imitation models by subtly altering output translations without heavily compromising the translation quality of the original system.
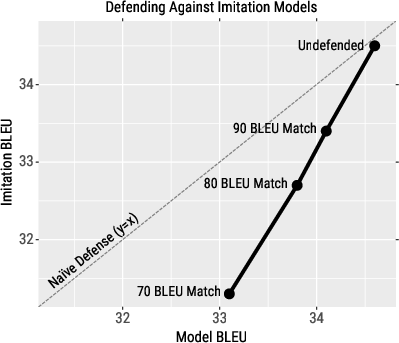
Figure 2: Defense mechanism performance showing BLEU trade-offs between victim and adversary's models.
By controlling the deviation in BLEU match thresholds, the defense effectively increases the difficulty of successfully training high-fidelity imitation models. This defensive strategy results in a smaller decrease in BLEU for the original system compared to the imitation models, offering a practical trade-off.
Conclusion
The paper underscores the practical threats posed by model stealing and adversarial attacks to commercially deployed MT systems. Through comprehensive experiments, the authors highlight the feasibility of such attacks and provide initial steps towards developing robust defenses. The research calls for ongoing work to enhance security mechanisms in NLP systems, ensuring that these critical tools remain secure against unauthorized exploitation.

