- The paper demonstrates that Perturbed Masking extracts BERT's inherent linguistic representations without adding extra parameters.
- It utilizes impact matrices from token perturbation to uncover dependency and constituency structures in unsupervised parsing tasks.
- Findings show that BERT's emergent syntax improves downstream applications such as Aspect-Based Sentiment Classification.
Detailed Analysis of "Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT"
Introduction
The paper "Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT" addresses the challenges in probing pre-trained models like BERT for linguistic capabilities without introducing additional parameters that may obscure the true capabilities of the model. By removing the need for parameterized probes, the researchers focus on the linguistic structures inherently learned by BERT during its pre-training phase. This approach highlights a more intrinsic view of the syntactic properties captured by the BERT representations.
Parameter-free Probing with Perturbed Masking
The proposed method, Perturbed Masking, measures word interactions within a sequence by perturbing and masking tokens in BERT's input during the Masked Language Modeling (MLM) task. The method involves sequentially masking a token and observing the impact on the embeddings of other tokens. This strategy allows for constructing an impact matrix F that can be analyzed to infer syntactic structures without any external labeled data or additional parameters typically involved in probing classifiers.
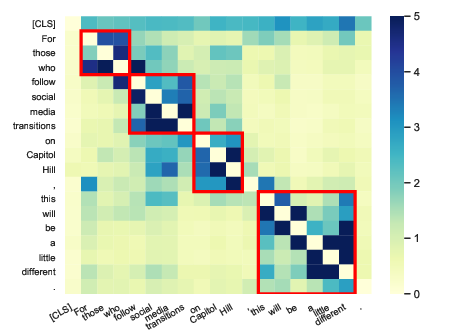
Figure 1: Heatmap of the impact matrix for the sentence "For those who follow social media transitions on Capitol Hill, this will be a little different."
The impact matrix is effectively a pairwise comparison of token influence, and visualizations of these matrices (as heatmaps) reveal syntactic relationships such as dependency and constituency patterns (Figure 1).
Syntactic and Constituency Probing
By treating the impact matrices derived from BERT as indicative of syntactic structure, the paper evaluates BERT’s ability to perform unsupervised parsing tasks. Two parsing methods are employed: dependency parsing using graph-based algorithms (capturing tree structures in sentences), and constituency parsing modeled as a recursive top-down process to separate sentence constituents.
Dependency Parsing
The Eisner and Chu-Liu/Edmonds algorithms are used to extract projective and non-projective dependency trees from sentences. The results show that perturbed masking allows BERT to outperform linguistically-uninformed baselines in recovering known dependency structures, although with limitations tied to annotation variance.
Constituency Parsing
A top-down parsing algorithm named MART (MAtRix-based Top-down parser) is proposed, which identifies potential constituency breaks using the impact matrices. This method is compared against existing unsupervised parsing techniques like ON-LSTM, revealing BERT's significant strengths in capturing higher-level syntactic units, particularly clause-level constructs.
Evaluation on Downstream Tasks
The study further explores the practical utility of BERT's internalized syntactic structure by evaluating its impact on Aspect-Based Sentiment Classification (ABSC). Trees extracted from BERT are compared with those from parser-designed schemas, highlighting that BERT's syntax understanding can sometimes better support downstream task performance. This underscores the validity of BERT's emergent linguistic structures, despite them not aligning perfectly with traditional syntactic formalism.
Conclusion
The study provides evidence that BERT encodes rich syntactic information which can be effectively extracted using the Perturbed Masking method. Although these embeddings do not always agree with linguist-designed syntaxes, they demonstrate empirical utility in enhancing complex NLP tasks. Future work in this area might explore extending the application of perturbed masking to other linguistic phenomena or refining the ability to derive specific syntactic insights directly from these matrices.

