- The paper provides a comprehensive analysis of semantic similarity techniques by categorizing knowledge-based, corpus-based, and neural methods.
- It details methodologies like edge-counting, information content, and modern embeddings such as BERT, highlighting their performance metrics.
- It concludes that hybrid approaches, which merge complementary strengths from various methods, offer robust solutions for NLP challenges.
Evolution of Semantic Similarity -- A Survey
Semantic similarity in NLP tasks is pivotal in unlocking functionalities ranging from information retrieval and text classification to machine translation and question answering. The paper "Evolution of Semantic Similarity – A Survey" provides a robust analysis of methodologies developed over decades, categorically diving into knowledge-based, corpus-based, deep neural network-based, and hybrid methods.
Introduction to Semantic Similarity
Semantic Textual Similarity (STS) assesses the semantic closeness between text blocks crucial for applications like text summarization and essay evaluation. Initial attempts relied on lexical measures such as BoW and TF-IDF, which lacked semantic depth. The paper emphasizes the distinction between semantic similarity and relatedness, with similarity being a subset of relatedness. Semantic distance often serves as the inversely proportional measure to these relationships.
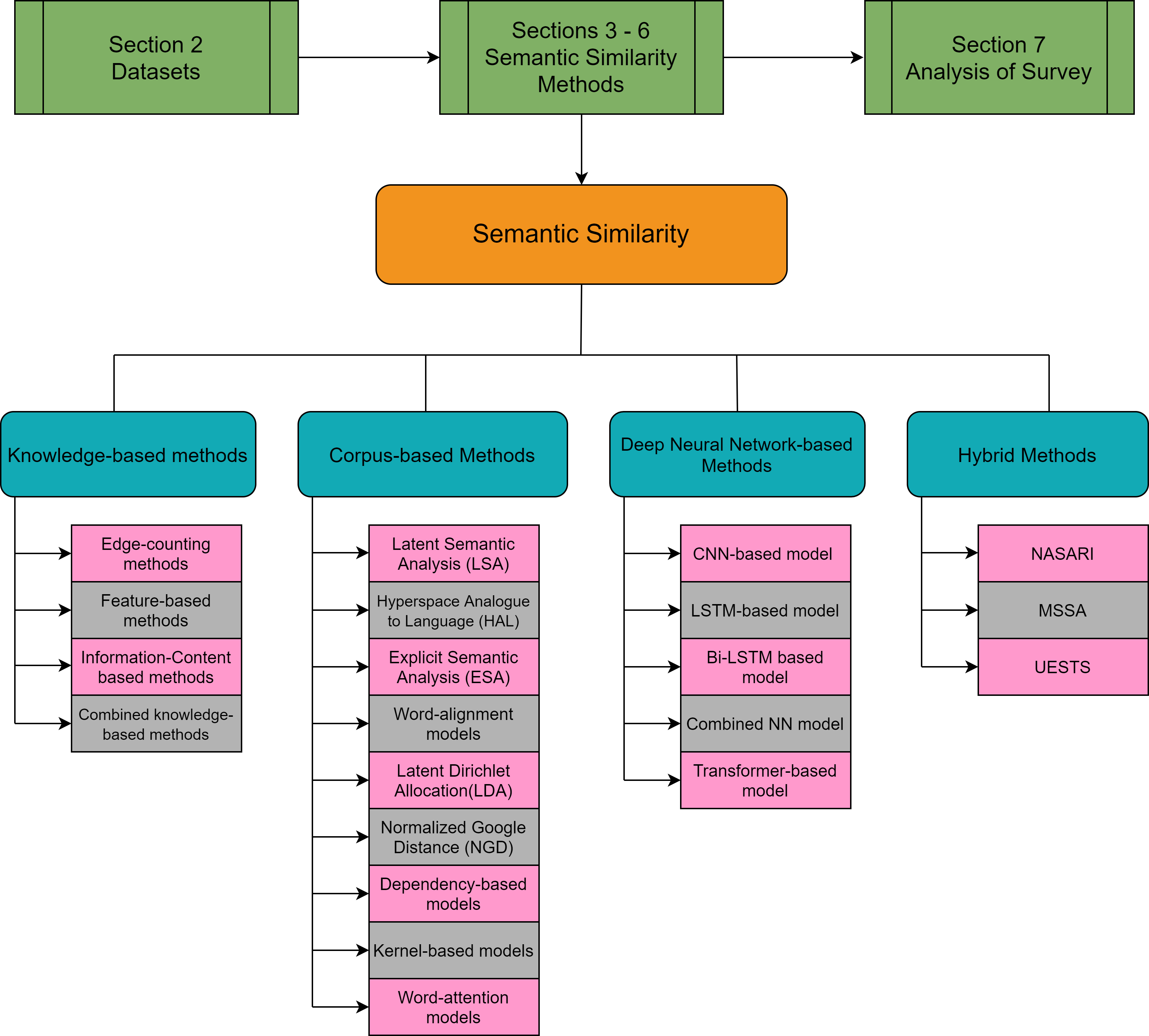
Figure 1: Survey Architecture.
Knowledge-Based Methods
Lexical Databases
- WordNet: Graph-based ontology utilizing synonym sets, or synsets, for semantic relation extraction.
- Wiktionary: Multilingual collection offering broad-coverage lexical information, though weaker taxonomically.
- Wikipedia: Widely leveraged for semantic analysis, providing both structured taxonomic data and corpus.
- BabelNet: A comprehensive hybrid resource fusing WordNet synsets with Wikipedia data.
Methods Employed
- Edge-Counting: Utilizes path lengths within taxonomy graphs; Wu and Palmer's measure integrated depth attributes.
- Feature-Based: Measures like Lesk exploit gloss overlaps to compute relatedness.
- Information Content (IC): Metrics like Resnik's rely on LCS informativeness for similarity scoring, with extensions by Lin and Jiang-Conrath considering word-specific details.
Corpus-Based Approaches
These revolve around the distributional hypothesis, harnessing word co-occurrence to derive semantic distance.
Word Embeddings
- Word2Vec: Offers high-quality word vectors via neural networks, featuring models like CBOW and Skip-gram.
- GloVe: Utilizes co-occurrence matrices for vector generation, aligning local context and global statistics.
- FastText: Focuses on character n-gram representations, elevating morphological and contextual specificity.
- BERT: Transformer-based embeddings achieving high STS benchmark scores via attention mechanisms.
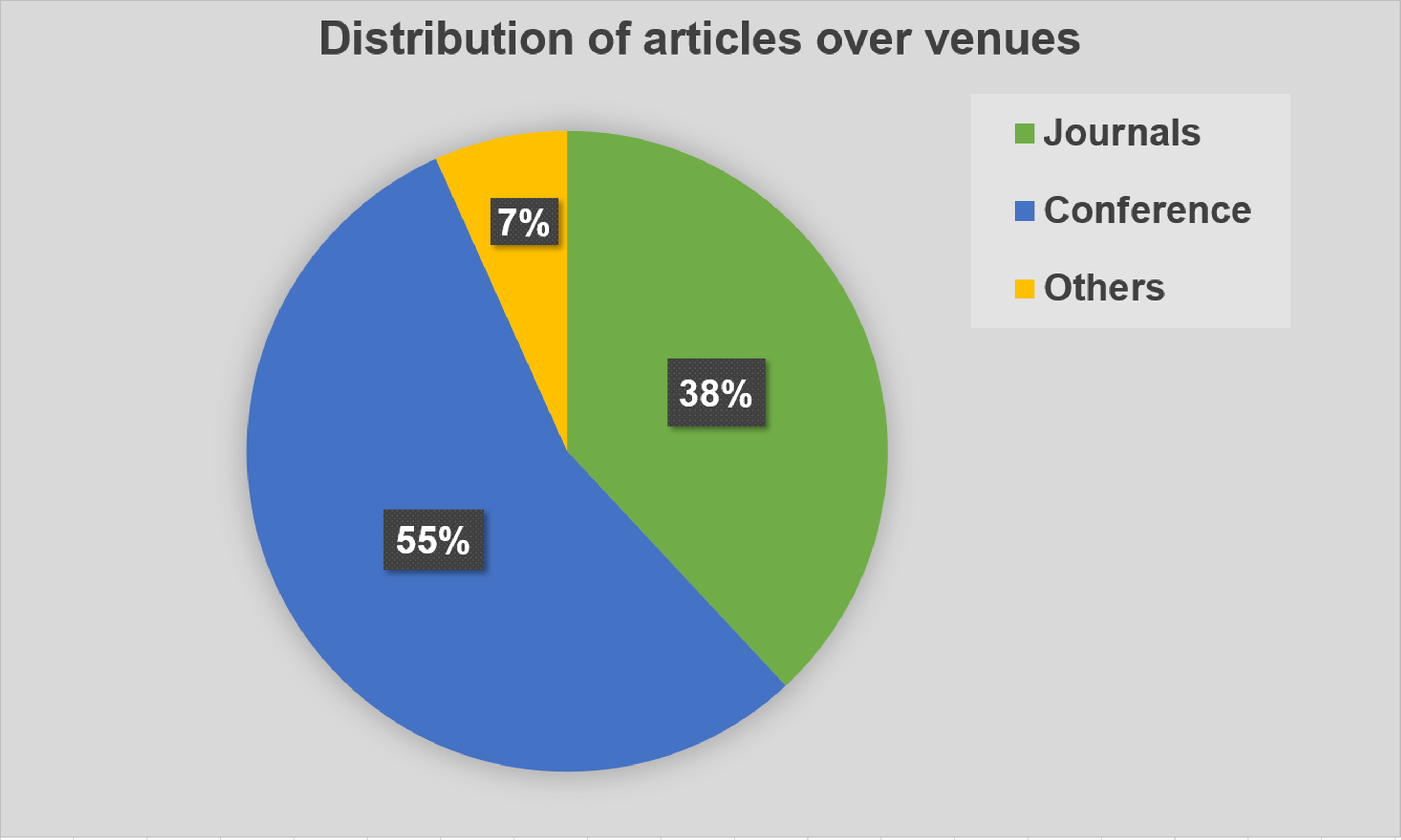
Figure 2: Distribution of articles over venues.
Other Models
Deep Neural Network-Based Methods
The survey showcases advanced architectures leveraging LSTM, Bi-LSTM, CNN, and recursive models. These surpass many traditional approaches, with transformer models like BERT pioneering current advancements. Additionally, integration of word attention mechanisms becomes critical, collectively enhancing feature significance in vectors.
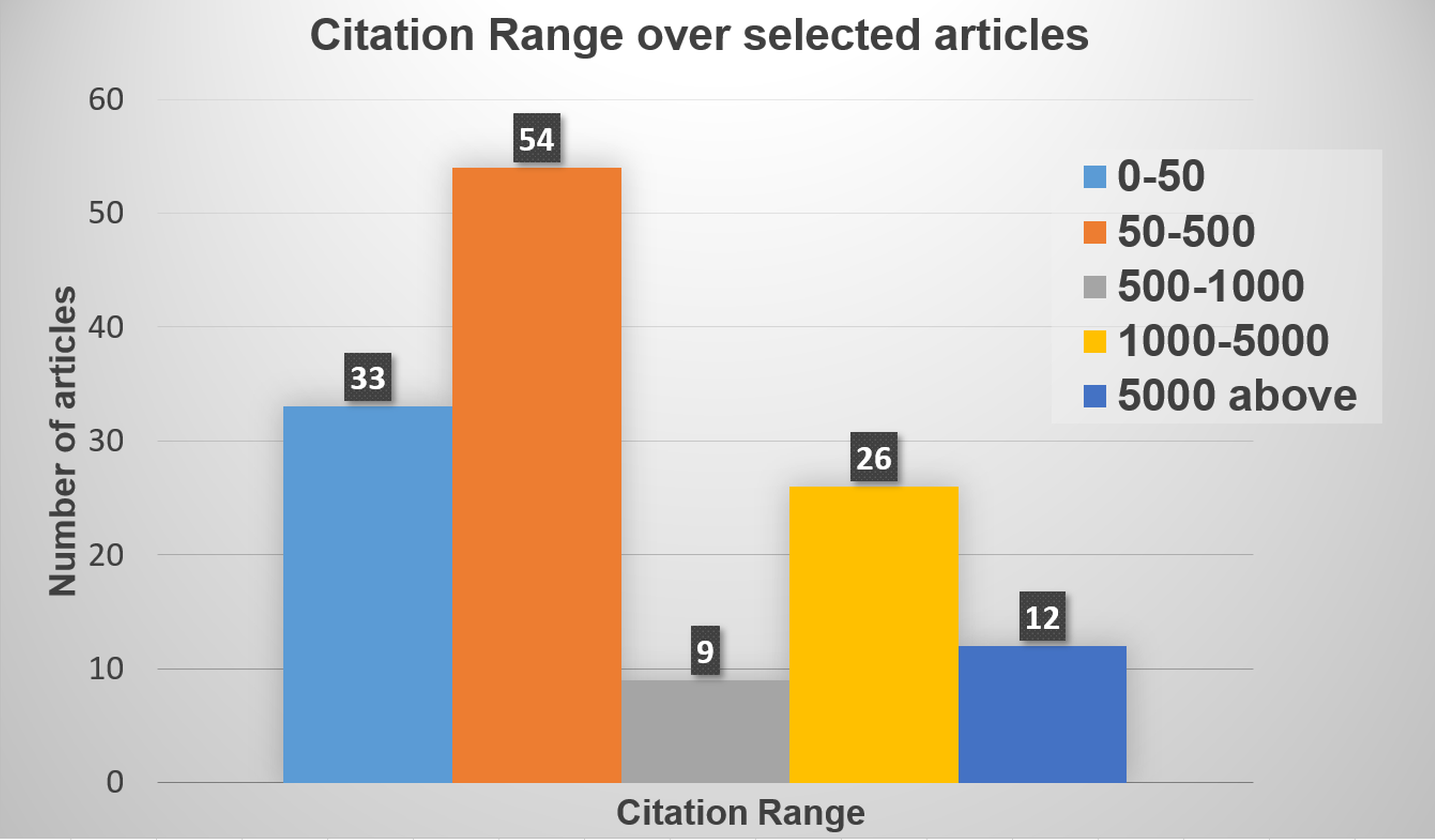

Figure 3: Distribution of citation range over the articles.
Hybrid Methods
Hybrid models exploit strengths across categories. Techniques such as NASARI integrate corpus statistics with structured knowledge sources like BabelNet, while MSSA focuses on refining multi-sense embeddings using WordNet synsets. Ensemble models, highlighted by works like UESTS, aggregate probabilistic measures and embedding-based techniques for improved semantic similarity scoring.
Conclusion
The survey suggests that while individual methods bring unique advantages, hybrid approaches offer the most robust solutions by integrating complementary strengths. With the landscape leaning on efficient embeddings and transformer models, future research could focus on computational optimization and cross-domain applicability. The paper serves as a comprehensive resource for researchers aiming to advance the field of semantic similarity in NLP.