Property Graph Schema Optimization for Domain-Specific Knowledge Graphs
Abstract: Enterprises are creating domain-specific knowledge graphs by curating and integrating their business data from multiple sources. The data in these knowledge graphs can be described using ontologies, which provide a semantic abstraction to define the content in terms of the entities and the relationships of the domain. The rich semantic relationships in an ontology contain a variety of opportunities to reduce edge traversals and consequently improve the graph query performance. Although there has been a lot of effort to build systems that enable efficient querying over knowledge graphs, the problem of schema optimization for query performance has been largely ignored in the graph setting. In this work, we show that graph schema design has significant impact on query performance, and then propose optimization algorithms that exploit the opportunities from the domain ontology to generate efficient property graph schemas. To the best of our knowledge, we are the first to present an ontology-driven approach for property graph schema optimization. We conduct empirical evaluations with two real-world knowledge graphs from medical and financial domains. The results show that the schemas produced by the optimization algorithms achieve up to 2 orders of magnitude speed-up compared to the baseline approach.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper is about making “knowledge graphs” much faster to search. A knowledge graph is like a big map of facts: circles (called nodes) are things like drugs or diseases, and arrows (called edges) show how they are connected, like “treats” or “causes.” The authors show that how you design the “blueprint” for this graph (the schema) can make searches way faster, and they present smart ways to redesign that blueprint using the rules of the domain (an ontology) as a guide.
The main questions the paper asks
- Does the way we design the graph’s blueprint (schema) change how fast we can answer questions?
- How can we use the domain’s ontology (the official list of types of things and how they relate) to design a better schema?
- Can we reduce the number of “hops” through the graph (like taking shortcuts) to speed up queries?
- How do we balance speed gains with extra memory cost when we copy or combine data?
- Can we build practical algorithms that pick the best schema automatically, and do they work on real medical and financial data?
How they approached the problem
Think of a city map:
- Places are nodes (e.g., Drug, Disease).
- Roads connecting places are edges (e.g., “Drug treats Disease”).
- A “schema” is the plan that says which kinds of places exist and how they can connect.
- A “query” is a trip plan, like “find all foods that interact with this drug.”
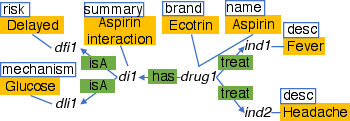
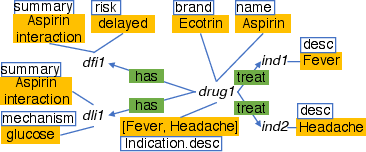
The time it takes to answer a query often depends on how many roads you must travel (edge traversals). Fewer roads = faster answers. The authors design rules that reorganize the map to add shortcuts or combine places—without changing the meaning of the information.
They propose five simple, powerful rules:
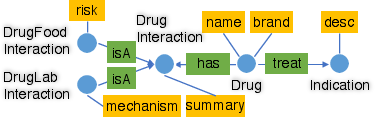
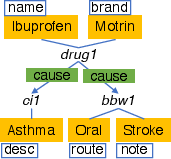
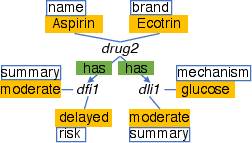
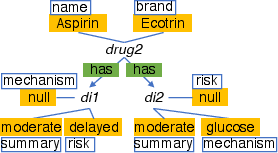
- Union rule: If there’s a “group” node that only represents “members” (like a hub that just gathers two types), connect the members directly to neighbors to skip the hub. It’s like closing a central roundabout and adding direct streets.
- Inheritance rule: For parent/child types (like Vehicle → Car), sometimes copy shared info down or up so you don’t need to take an extra hop to the parent or child. Like labeling both “Vehicle” and “Car” parking spots with the same rules when it helps.
- One-to-one rule: If two types always match one-to-one, merge them into a single node type. Like combining two rooms that always go together into one room.
- One-to-many rule: If one thing connects to many other things (like a Drug → many Indications), copy key lists (like a list of indications) into the “one” side so counting or checking them is instant, with no travel. Like keeping a checklist on the fridge instead of walking to every room.
- Many-to-many rule: Do the same “list-copying” in both directions when two types can connect to many of each other.
These tricks reduce hops and speed up queries. The trade-off: copying info takes more space. So the authors add planners that decide when the speedup is worth the space.
Two smart planners help pick the best schema under a memory budget:
- Concept-centric planner: Finds the most “important” types (concepts) first and optimizes around them. “Important” is measured with a popularity score like PageRank (similar to how Google ranks pages), adjusted for how often those types are used and how big they are. It then applies the rules until the memory budget is used up.
- Relation-centric planner: Scores each connection (relationship) by its benefit (how much it speeds common queries) versus its cost (extra memory). It then picks the best set of changes that fit the memory budget.
Both planners can use:
- Data stats: how many items of each type, how big properties are, how many links exist.
- Workload hints: which types and links people query most often.
What they found and why it matters
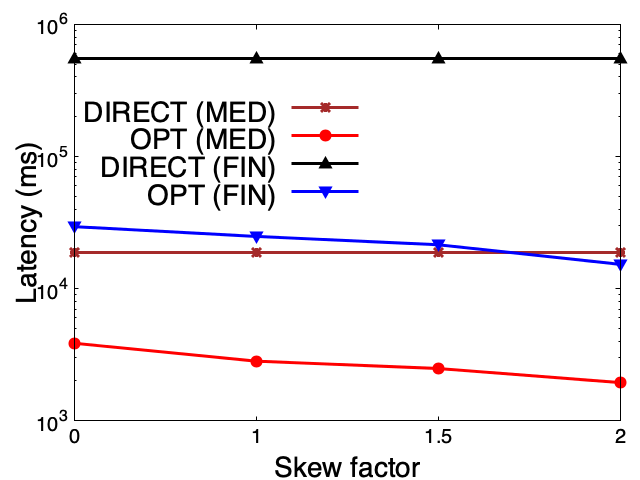
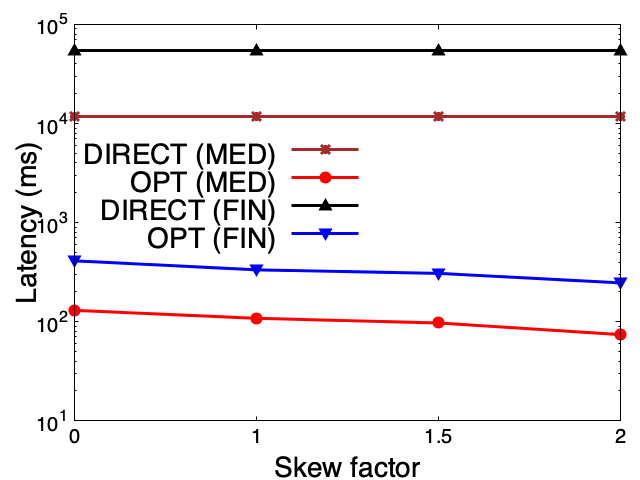
- Fewer hops make a huge difference. In one medical example, a pattern-matching query dropped from about 3245 ms to 23 ms—around 100 times faster—by removing an unnecessary middle node.
- Aggregation got faster too. Counting related items (like all indications for a drug) ran about 8 times faster by storing a ready-made list instead of walking to every connected node.
- These ideas worked on real medical and financial knowledge graphs, not just toy examples.
- Their approach is, to their knowledge, the first to use ontologies to automatically optimize property graph schemas.
- Importantly, they keep the meaning intact while changing the “shape” of the graph to match how it’s used.
What this could change in the real world
- Faster answers for apps like medical decision support, fraud detection, and customer service, where speed means better outcomes and experiences.
- Lower compute costs because queries do less work.
- A new mindset: schema design for graphs really matters, just like indexing does for databases.
- A practical toolkit: simple, explainable rules plus planners that respect a memory budget.
- Future directions: handle more complex ontology features, automatically adapt as data and workloads change, and plug into different graph systems.
In short: The paper shows that using domain knowledge to redesign the graph’s blueprint—by adding smart shortcuts and combining the right pieces—can make queries dramatically faster, often with small and controlled increases in storage.
Collections
Sign up for free to add this paper to one or more collections.

