- The paper demonstrates that larger Transformer models, notably T5-11B, can store extensive factual knowledge using a closed-book QA approach.
- It employs salient span masking during pre-training to enhance the model's capability in retrieving factual information from its parameters.
- Results reveal that increased parameter size enables closed-book models to rival open-book systems, though challenges in scalability and interpretability remain.
How Much Knowledge Can LLMs Store?
Introduction and Approach
The paper, "How Much Knowledge Can You Pack Into the Parameters of a LLM?", explores the capability of LLMs, specifically Transformer-based models like T5, to store and retrieve knowledge without external context. The authors fine-tune pre-trained models to answer questions based solely on knowledge stored in their parameters, thus introducing a task referred to as "closed-book question answering" (CBQA).
Central to this exploration is the hypothesis that larger models with more parameters can store more knowledge, thereby improving performance in knowledge-retrieval tasks, especially open-domain question answering (ODQA). The study employs the T5 (Text-to-Text Transfer Transformer) model, fine-tuning different-sized variants to observe how performance scales with augmented parameter capacity. For practical utility, these models are evaluated against traditional open-domain systems reliant on external data sources.
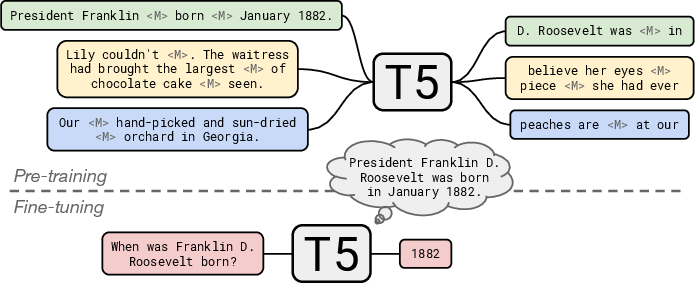
Figure 1: T5 is pre-trained to fill in dropped-out spans of text from documents, simulating a CBQA setting.
Experimental Design
The experiments utilize prominent ODQA datasets including Natural Questions, WebQuestions, and TriviaQA. Each dataset challenges the model to produce answers without access to the supporting documents typically provided. Models used in this study range from T5-Base (220 million parameters) to T5-11B (11 billion parameters), evidencing how performance scales with size.
The paper also explores the impact of continuing pre-training with salient span masking (SSM), enhancing the model's ability to handle knowledge-intensive tasks. This pre-training step involves masking named entities and dates, aiming to force the model to encode factual knowledge effectively.
Results and Analysis
The research findings illustrate that model performance increases with size, with the largest model (T5-11B) delivering competitive results against existing ODQA systems that use external knowledge sources.
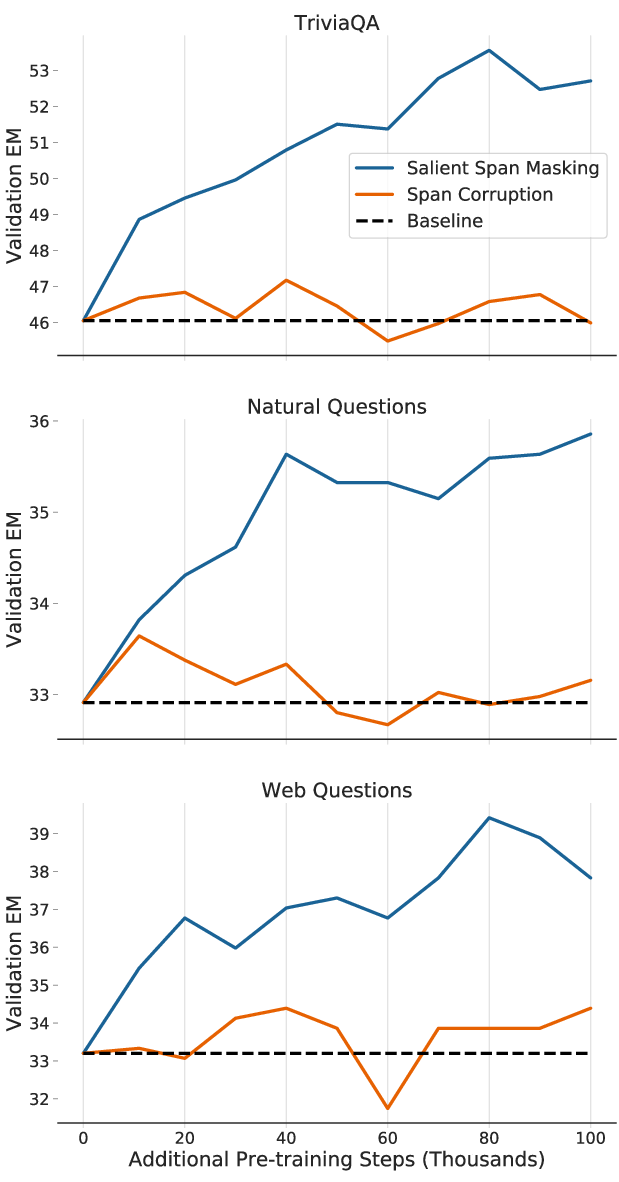
Figure 2: Comparing SSM and span corruption (SC) shows SSM's superior pre-training impact on QA tasks.
Table results from various datasets corroborate the hypothesis that larger models extract and internalize more factual knowledge. The SSM pre-training significantly improved scores across all tasks, particularly boosting T5-11B's competitive edge. Even more remarkable, T5-11B achieved state-of-the-art on the WebQuestions benchmark.
These results invite a reevaluation of QA methodologies, suggesting closed-book approaches can, with sufficient scale, rival or surpass open-book systems in efficiency by eliminating the resource-heavy steps of knowledge retrieval and document context processing.
Human Evaluation and Challenges
The methodology incorporated human evaluation to account for false negatives attributed to phrasing discrepancies and incomplete annotations. This highlighted a discrepancy between automated evaluation metrics and practical performance, suggesting a 57.8 recalibrated validation score with human insights considered.
Despite robust results, reliance on extensive parameter allocation poses scalability challenges, particularly in resource-constrained environments. Interpretability of CBQA models remains a pertinent issue; unlike open-book systems, they do not offer transparency into why specific answers are generated, often "hallucinating" facts when lacking certainty.
Conclusion
This paper presents compelling evidence that large-scale LLMs hold vast potential as standalone knowledge bases. While the findings present scalability challenges and questions around knowledge continuity and modification post-training, they carve a path for refining LM architectures to incorporate efficient CBQA capabilities. Future investigations might address interpretability and the possible fusion of open-book and closed-book systems to leverage their respective strengths, ensuring models not only retrieve but also reason with knowledge intuitively.

