- The paper introduces curriculum learning to adaptively select pseudo-labeled samples, mitigating concept drift in semi-supervised settings.
- It resets model parameters at each self-training cycle, preventing error accumulation from previous iterations.
- Empirical results on CIFAR-10 and ImageNet confirm that the approach achieves competitive accuracy even with distribution mismatches.
Curriculum Labeling Algorithm for Semi-Supervised Learning
Introduction
In the paper titled "Curriculum Labeling: Revisiting Pseudo-Labeling for Semi-Supervised Learning" (2001.06001), the authors explore and refine the technique of pseudo-labeling within the semi-supervised learning (SSL) paradigm. SSL leverages unlabeled data alongside limited labeled data to train models more effectively, an approach critical in scenarios where labeled datasets are expensive or scarce. Pseudo-labeling uses models trained on labeled data to assign labels to unlabeled samples, iteratively refining these pseudo-labels through a self-training cycle. This method, once overshadowed by consistency-based regularization techniques, has been revitalized by integrating curriculum learning principles and addressing the issue of concept drift.
The authors introduce two main contributions that enhance pseudo-labeling: the integration of curriculum learning to optimize the pacing of unlabeled sample inclusion, and the strategy of resetting model parameters before each self-training cycle. The paper presents empirical evidence of competitive results using this approach, achieving a test accuracy of 94.91% on CIFAR-10 with only $4,000$ labeled samples, suggesting an effective alternative to the dominant consistency regularization approaches.
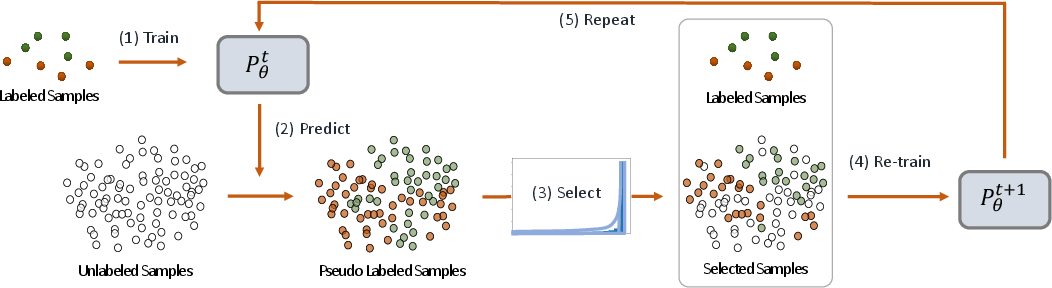
Figure 1: Curriculum Labeling (CL) algorithm. The model is trained on labeled samples. It predicts and assigns pseudo-labels to the unlabeled samples, selects a subset based on prediction score distribution, re-trains the model, and repeats until all samples are incorporated.
Methodology
The pseudo-labeling process revisited in this paper involves a cyclical model-training regime, wherein the model iteratively incorporates unlabeled samples into the training set by assigning them pseudo-labels. This process persists until all samples in the dataset are utilized (Figure 1). The core innovation of the paper lies in employing a self-paced curriculum that better manages the inclusion of unlabeled data, ensuring stable learning progression. This curriculum is executed via Extreme Value Theory (EVT) to discern the distribution tails of predicted scores, reducing the risk of concept drift—where evolving data unsettle learning patterns—and confirmation bias.
One significant methodological advance is initializing model parameters anew in each iteration, preventing the accumulation of errors entrenched during model finetuning. Algorithmically, pseudo-labeled samples are iteratively selected by percentile ranks rather than fixed thresholds, facilitating a dynamic adaptation to learning progress and data characteristics.
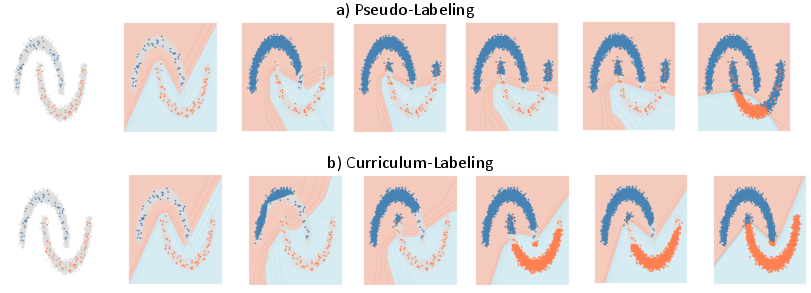
Figure 2: Comparison of regular pseudo-labeling~(PL) and pseudo-labeling with curriculum labeling~(CL) on the "two moons" synthetic dataset, showing superior CL decision boundaries.
Empirical Results
Empirical validation of curriculum labeling confirms its resilience and competence compared to state-of-the-art SSL methods. The algorithm achieves near-parity performances on benchmark datasets like CIFAR-10 and demonstrates robustness on ImageNet, with accuracy figures closely trailing contemporary methods such as UDA. More notably, the methodology shines in challenging SSL settings where unlabeled samples do not conform to the distribution of labeled data, proving curriculum labeling's efficacy in realistic, distribution-mismatched training scenarios (Figure 3).
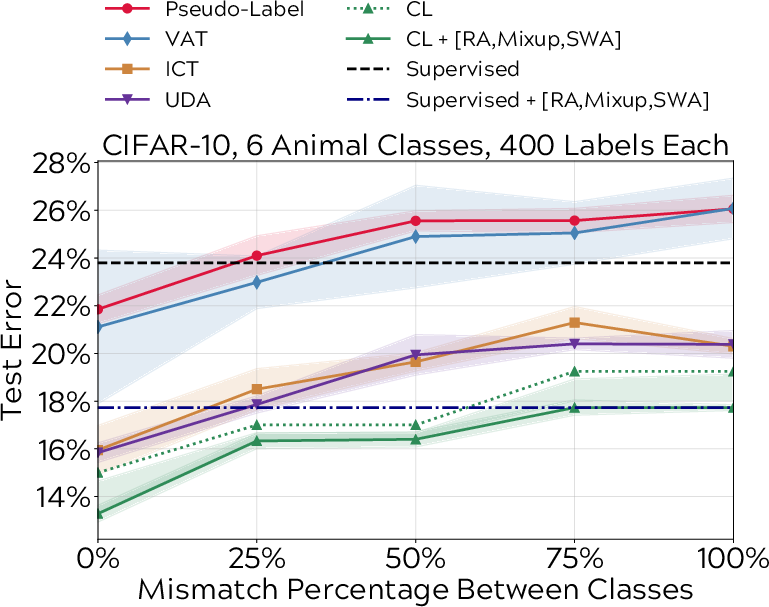
Figure 3: Test error comparison across CIFAR-10 classes with varying class overlap between labeled and unlabeled datasets, showcasing resilient performance of curriculum labeling under distribution mismatch.
Implications and Future Directions
The paper's findings have broad implications for SSL methodologies, suggesting that pseudo-labeling, if correctly tuned with a curriculum, can surpass traditional algorithmic approaches reliant purely on consistency regularization. It addresses vital challenges such as distribution mismatch and concept drift, paving the way for more versatile and robust models in real-world applications.
Future research might explore adaptive curricula for data stream scenarios and the exploration of curriculum impact for diverse neural network architectures, extending beyond vision tasks to LLMs and other domains grappling with limited labeled data availability. Further exploration into integrating more sophisticated self-paced learning metrics and dynamic parameter adjustment could amplify these baseline offerings, making SSL increasingly practical for extensive use cases.
Conclusion
This research demonstrates that pseudo-labeling, augmented through curriculum learning, is not only viable but preferable in certain SSL contexts, offering a competitive and practical solution for semi-supervised learning frameworks. This dual-focus on label distribution and model resilience against drift showcases curriculum labeling as a promising approach that broadens the applicability and effectiveness of SSL strategies.
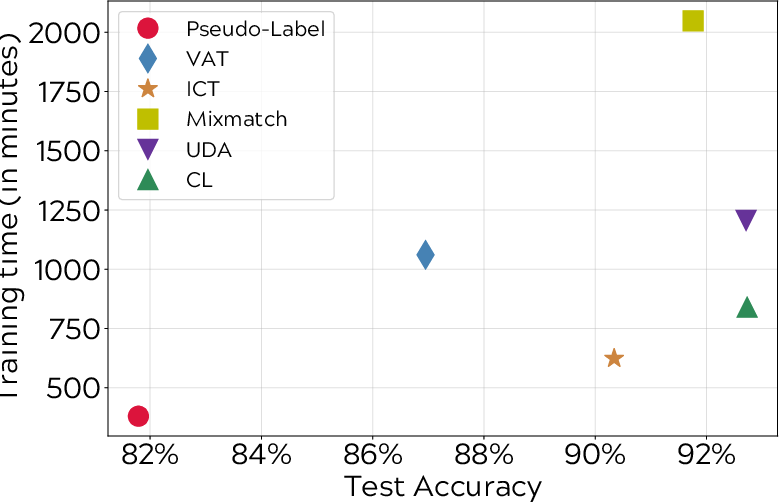
Figure 4: Time consumption versus test accuracy comparison on CIFAR-10, confirming efficiency and effectiveness balance achieved through curriculum labeling.