- The paper presents DZip, a novel lossless compression algorithm that employs a dual-model neural network approach for improved prediction accuracy.
- It uses a bootstrap model with semi-adaptive training paired with an adaptive supporter model, achieving notable size reductions over traditional compressors.
- The approach demonstrates enhanced computational efficiency and adaptability across data types, paving the way for further neural network optimizations in data compression.
DZip: Improved General-Purpose Lossless Compression with Neural Network Modeling
Introduction
The paper "DZip: improved general-purpose lossless compression based on novel neural network modeling" (1911.03572) introduces DZip, a compressor leveraging neural networks for lossless data compression. Due to the exponential growth of diverse data types, efficient compression methods are critical for reducing storage and transmission costs. DZip notably employs a hybrid architecture combining adaptive and semi-adaptive training approaches to achieve high compression rates without requiring external training data.
Methodology
DZip utilizes a neural network-based framework for the predictive modeling of sequential data. The design comprises two primary components: a bootstrap model and a supporter model, operating within an adaptive-semi-adaptive hybrid scheme.
In this paradigm, the bootstrap model is trained semi-adaptively across multiple passes of the input sequence, and its parameters are preserved within the compressed output. The supporter model enhances this setup using adaptive training initiated with random weights, combined with the bootstrap model's output for refined probability predictions. This dual-model configuration strategically balances compression efficacy against computational demands by minimizing model storage requirements while maximizing prediction accuracy.
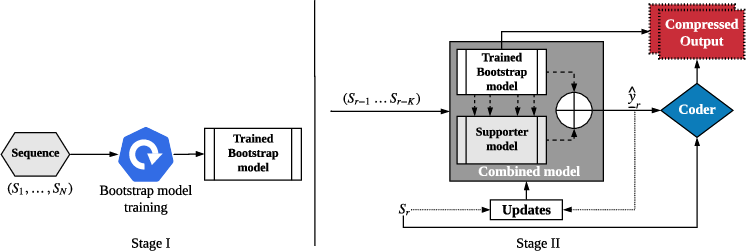
Figure 1: DZip compression overview outlining the hybrid model architecture combining bootstrap and supporter models for effective compression.
Compression Effectiveness
DZip demonstrates significantly higher compression ratios over traditional algorithms such as Gzip and 7zip, with a 29% and 12% average size reduction respectively. It also competes favorably with established NN-based compressors like CMIX and LSTM-Compress. On synthetic datasets, DZip approaches theoretical entropy limits, exemplifying its ability to learn and leverage long-term sequence dependencies.
Operational Dynamics
The bootstrap and supporter model architecture allows for adaptability across diverse data types without pre-existing training datasets. The use of a compressed model file with arithmetic coding enables DZip to harness the prediction+entropy coding framework optimally. Additionally, the substantial reduction in cross entropy loss correlates directly with improved compression rates above extant neural network models being notably several times quicker.
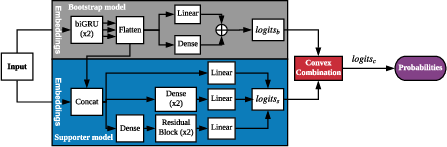
Figure 2: Architecture of DZip's combined model, integrating fully connected layers and concatenation blocks between bootstrap and supporter models.
Implications and Future Directions
The proposed use of neural networks opens new pathways for enhancing general-purpose compressors across different dataset characteristics without requiring customized models for distinct data types. This broad applicability signifies a substantial step toward integrating machine learning with conventional compression algorithms, facilitating expanded versatility and reduced operational complexities.
Looking forward, the incorporation of domain-specific knowledge and the further optimization of encoding/decoding speeds are prospective research avenues. Additionally, the advancement of training methodologies to utilize deep learning frameworks more broadly across hardware configurations could further augment the model's accessibility and practicality.
Conclusion
DZip significantly advances the capability of neural network models within general-purpose data compression, achieving competitive compression rates with remarkable computational efficiency. Although the current limitation lies in its encoding/decoding speed, the principled integration of semi-adaptive and adaptive models signifies ongoing potential for refinement and enhancement in compression technology. The research underscores an important stride in leveraging machine learning to meet expanding data compression demands effectively.