- The paper introduces a novel ASN framework that creates a generalized, task-agnostic skill embedding space using adversarial loss and metric learning.
- The methodology leverages a GAN-like encoder-discriminator setup to extract and differentiate skill representations from multi-view videos.
- Experimental results show improved policy performance and transferable skill learning in complex tasks such as multi-object manipulation using PPO.
Adversarial Skill Networks: Unsupervised Robot Skill Learning from Video
Adversarial Skill Networks (ASN) introduce a novel method for learning task-agnostic, transferable skill embeddings from unlabeled multi-view videos, targeting applications in unsupervised robot skill acquisition. The framework leverages the comprehensive power of adversarial networks combined with metric learning to facilitate the representation, discovery, and reuse of skills in a reinforcement learning (RL) context without relying on task-specific reward functions.
Methodology
Skill Embedding Space
ASNs use an adversarial loss framework to create a generalized skill embedding space. The adversarial component leverages a two-network setup: an encoder extracts skill representations from video frames, while a discriminator aims to distinguish the task origin of these skills based on learned embeddings. Both networks operate in a manner similar to GANs—maximizing and minimizing entropy, respectively—to foster a robust and versatile embedding space that is indifferent to specific task identifiers.
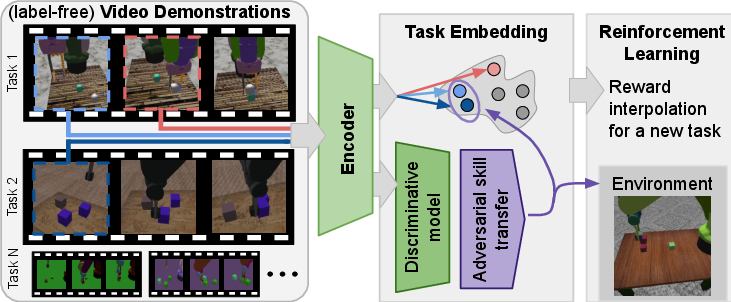
Figure 1: Given the demonstration of a new task as input, Adversarial Skill Networks yield a distance measure in skill-embedding space which can be used as the reward signal for a reinforcement learning agent for multiple tasks.
Metric Learning and Adversarial Loss
The approach combines innovative metric learning with lifted structure losses, leveraging temporal video coherence to refine state representation effectively. Temporal framing of videos into sequential skills, set apart by time delays, is used to construct a skill embedding where simultaneous states are pulled together, and temporally distant states are pushed apart, improving general task representation.
Network Architecture and Training
The encoder architecture, inspired by TCN structures, utilizes pre-trained ImageNet weights followed by convolutional layers, a spatial softmax layer, and a fully connected layer to derive lower-dimensioned embeddings. The discriminator comprises fully connected layers that produce a probabilistic distribution over potential task origins.
A critical design consideration is the use of KL-divergence to maintain embedding coherence when considering higher temporal strides, ensuring that macro-action representations are distinct yet adaptable across task scenarios.
Experimental Evaluation
Qualitative and Quantitative Testing
ASN's embedding models were rigorously tested across simulated and real-world datasets involving complex tasks, including multi-object stacking and manipulation. Evaluations relied on alignment loss metrics to assess skill coherence in embedding spaces, highlighting ASN's superior transfer learning capability compared to baselines such as TCNs.








Figure 2: Real block tasks
Policy Learning
The ASN framework's efficacy in skill transferability was further evidenced in continuous policy learning scenarios, leveraging learned embeddings as a reward proxy in PPO environments. ASN models successfully interpolated learned skills to achieve strong policy performance in novel tasks requiring unseen skill compositions.
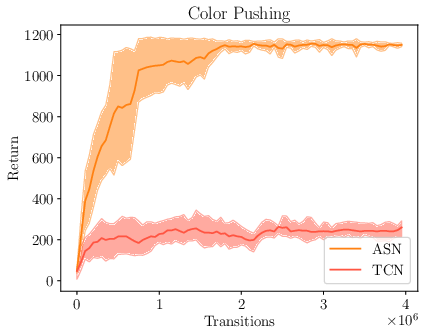
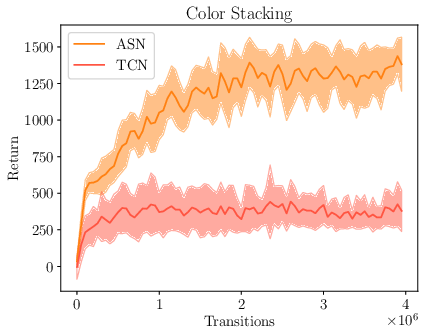
Figure 3: Results for training a continuous control policy with PPO on the unseen Color Pushing and Color Stacking tasks with the learned reward function. The plot shows mean and standard deviation over five training runs.
Conclusion
Adversarial Skill Networks provide a robust, unsupervised framework for learning and reusing generalized skill representations across varied tasks without requiring explicit reward designs. This method presents significant implications for extending RL and imitation learning towards real-world applications with minimal supervision, opening new avenues for scalable and adaptive robotic learning systems. Future work could explore ASN applications within sim-to-real settings and dynamically complex environments that require a higher degree of skill interpolation.