- The paper introduces active inference as a free energy minimization framework for optimal decision-making without explicit reward signals.
- It details a discrete-state formulation with matrix equations and simulations in the FrozenLake environment, showcasing rapid adaptation and robust behavior.
- It contrasts probabilistic preference learning in active inference with reward-based reinforcement learning, highlighting strengths in epistemic exploration and dynamic adaptation.
Introduction and Theoretical Foundations
The paper presents a rigorous exposition of active inference as a first-principles framework for autonomous agents operating in dynamic, non-stationary environments. The central theoretical construct is the free energy principle, which posits that agents minimize expected free energy to achieve Bayes-optimal behavior. This is operationalized via a generative model that encodes probabilistic beliefs over hidden states and outcomes, enabling agents to infer latent causes of observations and plan future actions.
Active inference is contrasted with reinforcement learning (RL), particularly in its treatment of reward and exploration. RL is defined by the reward hypothesis, where agent behavior is shaped by maximizing expected cumulative reward. In contrast, active inference treats reward as a special case of preferred outcomes, encoded as prior preferences in the generative model. This distinction leads to several key differences: active inference does not require explicit reward signals, supports epistemic exploration as a natural consequence of belief updating, and enables agents to learn their own preferences over outcomes.
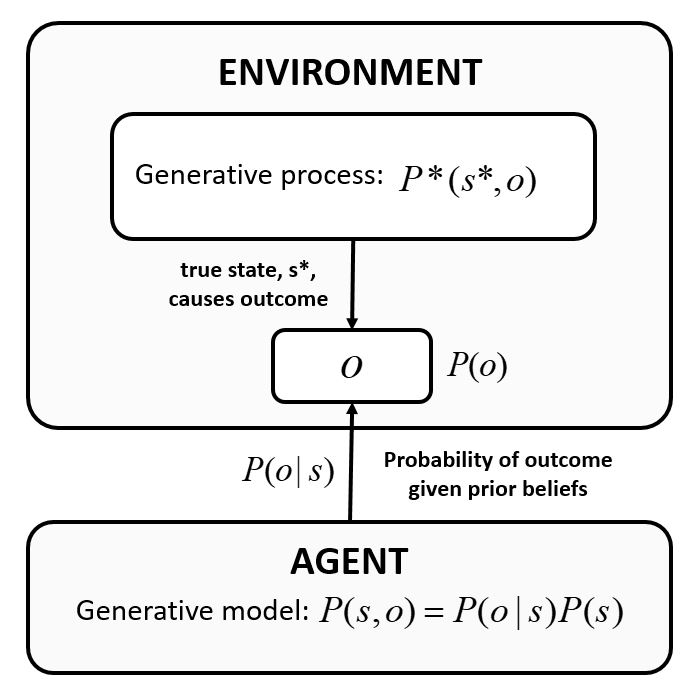
Figure 1: Graphical representation of the generative process and internal generative model, highlighting the shared outcomes between process and model.
The generative model is formalized as a POMDP, with the agent maintaining beliefs over hidden states s and outcomes o. The variational free energy F serves as an upper bound on surprise, and its minimization aligns the agent's beliefs with observed data. Expected free energy G extends this to future trajectories, decomposing into epistemic (information gain) and extrinsic (preference matching) components. Policy selection is performed via a softmax over negative expected free energy, integrating both exploration and exploitation imperatives.
Discrete-State Active Inference: Implementation and Optimization
The discrete-state formulation is detailed with explicit matrix equations for variational and expected free energy. The agent's generative model comprises:
- Hidden states: location and context (goal/hole positions)
- Actions: discrete movement directions
- Outcomes: grid position and score modalities
- Transition and likelihood matrices: encoding allowable moves and observation mappings
Optimization proceeds via gradient descent on free energy, updating beliefs about hidden states, policies, and precision parameters. The mean-field approximation is employed for tractable inference, and policy search is exhaustive but pruned via likelihood thresholds. Temporal discounting emerges naturally from the generative model's precision parameters, obviating the need for ad hoc temperature hyperparameters.
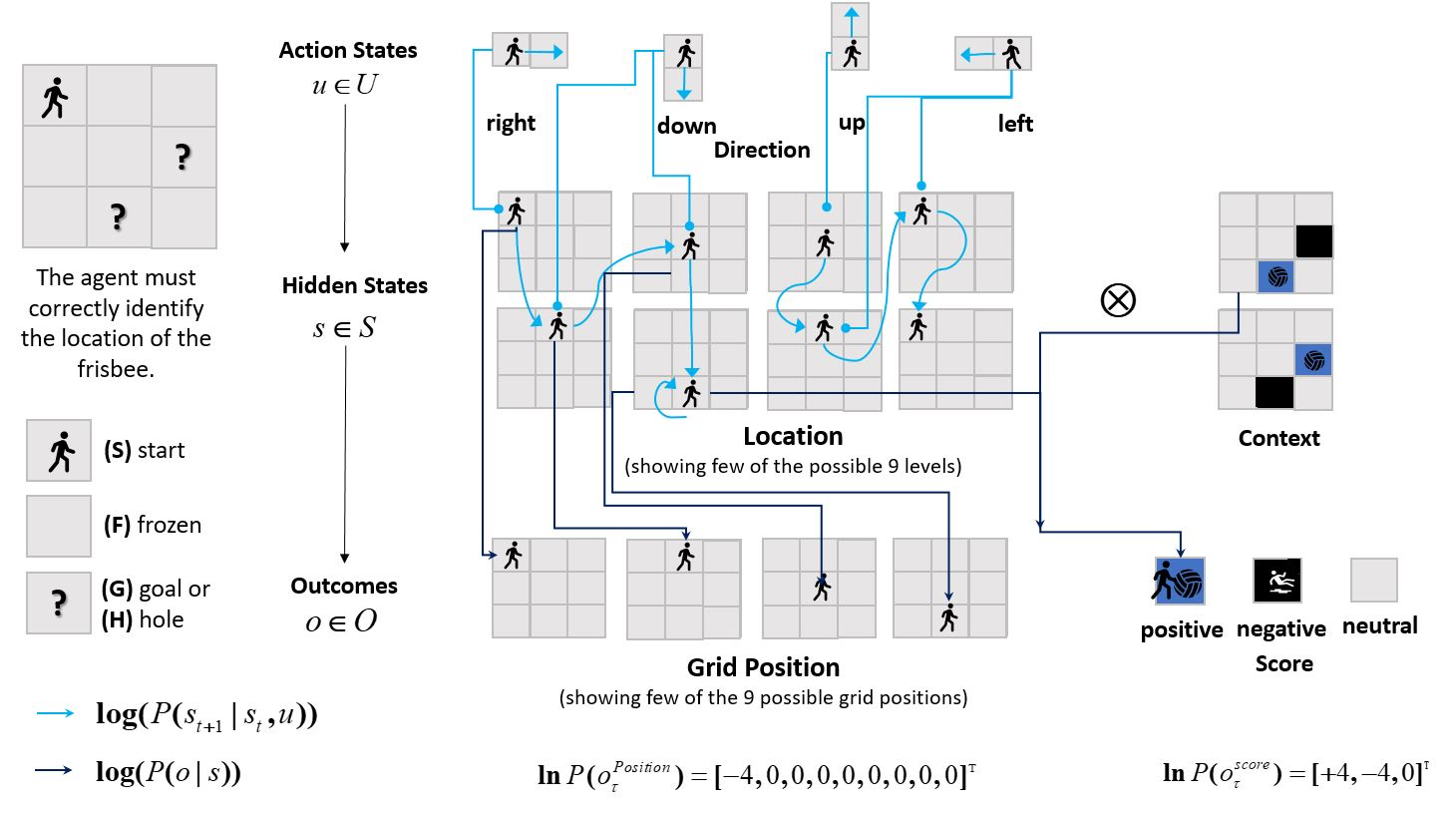
Figure 2: Graphical representation of the active inference generative model for the FrozenLake environment, illustrating action-state transitions, context factors, and outcome modalities.
Simulation Studies: FrozenLake Environment
The paper presents comprehensive simulations in a modified OpenAI Gym FrozenLake environment, comparing active inference agents to Q-learning and Bayesian model-based RL agents. The environment is structured as a 3×3 grid with absorbing goal and hole states, and agents must navigate to the goal while avoiding the hole.
Key implementation details for active inference agents include:
- Factorized hidden states (location ⊗ context)
- Identity mapping for grid position likelihood; context-dependent mapping for score
- Deep policy search over action sequences
- Prior preferences encoded as log-probabilities over outcomes
Reinforcement learning agents are implemented as:
- Q-learning with ϵ-greedy exploration (fixed and decaying ϵ)
- Bayesian RL with Thompson sampling, maintaining distributions over transition and reward models
Stationary and Non-Stationary Environments
In stationary environments, all agents (except the null active inference model) achieve high average scores, with active inference and Bayesian RL converging rapidly (<10 episodes) and maintaining tight confidence intervals. The null active inference agent, lacking prior preferences, exhibits purely exploratory behavior, ending in goal or hole states with equal probability.
In non-stationary environments (goal/hole locations swapped at intervals), active inference agents demonstrate rapid adaptation, recovering optimal performance after a single episode post-switch. Bayesian RL agents require more episodes to adapt due to accumulated pseudo-counts, while Q-learning agents adapt more quickly but with greater variance. The null active inference model remains unaffected by context switches, persisting in exploratory behavior.
Reward Shaping and Preference Learning
The paper investigates the equivalence and divergence between prior preferences in active inference and reward functions in RL via reward shaping experiments. When prior preferences are defined to match reward shaping, belief-based agents (active inference and Bayesian RL) exhibit nearly identical behaviors, learning Bayes-optimal policies as soon as positive reward is specified for the goal. Q-learning agents are more sensitive to reward shaping, with living costs inducing greedier policies.
In the absence of preferences/rewards, Q-learning agents default to deterministic circular policies with minimal exploration, while belief-based agents maintain exploration due to uniform probabilistic models. When only negative preferences/rewards are specified, all agents learn to avoid the hole but do not seek the goal, with belief-based agents assigning non-zero probability to both possible hole locations.
Active inference agents are shown to learn prior outcome preferences via Dirichlet hyperpriors, enabling time-dependent and context-sensitive preference formation. This capacity allows agents to develop niche behaviors (e.g., hole-seeking or goal-seeking) based on accumulated experience, a property not naturally supported in vanilla RL.
Implications, Limitations, and Future Directions
The paper provides strong numerical evidence for the adaptability and robustness of active inference agents in both stationary and non-stationary environments. The ability to perform reward-free learning and information-seeking behavior is highlighted as a fundamental property, with active inference subsuming RL as a special case when epistemic value is removed.
Theoretical implications include the dissolution of the reward tautology in RL, replacing it with prior beliefs over preferred outcomes. Practically, active inference offers a principled framework for decision-making under uncertainty, with natural exploration-exploitation trade-offs and online adaptation to environmental changes.
Limitations are acknowledged in the complexity of specifying appropriate generative models for real-world tasks. The extension to hierarchical, deep temporal, and continuous state-space models is discussed, with future work suggested in amortized inference, structural learning, and implicit generative models derived from empirical data.
Conclusion
The paper demystifies active inference by providing a discrete-state formulation, explicit behavioral comparisons to RL, and detailed simulation results. Active inference is shown to support Bayes-optimal behavior, natural epistemic exploration, and preference learning without explicit reward signals. The framework offers a unified approach to action and perception, with implications for robust agent design in dynamic environments. Future research should focus on scalable generative model specification and integration with deep learning architectures for complex real-world applications.

