- The paper proposes an entity-centric retrieval framework that explicitly links evidence chains to improve multi-hop question answering.
- It employs a three-step pipeline—BM25 retrieval, entity linking, and BERT-based re-ranking—yielding a 26.5% boost in retrieval accuracy@10 and 18.4% in MAP.
- The approach generalizes to single-hop and zero-shot settings, enhancing end-to-end QA performance with its modular design.
Introduction and Motivation
Multi-hop question answering (QA) poses significant information retrieval (IR) challenges, as it requires not only locating multiple evidence-containing documents but also reasoning across them. Standard IR methods, such as BM25 or pseudo-relevance feedback (Prf), struggle to accurately retrieve all necessary supporting passages from massive corpora when the answer documents have minimal lexical overlap with the question (Figure 1).

Figure 1: Multi-hop questions require finding multiple evidence and the target document containing the answer has very little lexical overlap with the question.
The need for improved retrieval techniques is especially acute in datasets like HotpotQA, where single-hop queries achieve 53.7% retrieval accuracy using BM25, but multi-hop queries drop sharply to 25.9%. The authors hypothesize that building "hopiness" into the retriever—allowing explicit, multi-step transitions between documents via linked entities—is essential for high-recall, multi-hop evidence collection.
Methodology
The proposed retrieval framework introduces an entity-centric, multi-step approach, summarized in Figure 2. The main pipeline includes three components:
- Initial Paragraph Retrieval: A traditional IR model (e.g., BM25) retrieves candidate paragraphs using the raw query.
- Entity Linking: From each initially retrieved paragraph, all entity mentions are identified, using a custom alias table to map mentions to candidate Wikipedia paragraphs.
- BERT-based Re-ranking: For each chain of initial paragraphs plus linked entity paragraphs, a BERT encoder represents both, concatenates [CLS] token representations for the query-aware paragraphs, and scores evidence chains via a two-layer feed-forward network.
This enables chains of evidence to be scored jointly, accommodating both multi-hop and single-hop questions through explicit self-loops (see Figure 2).
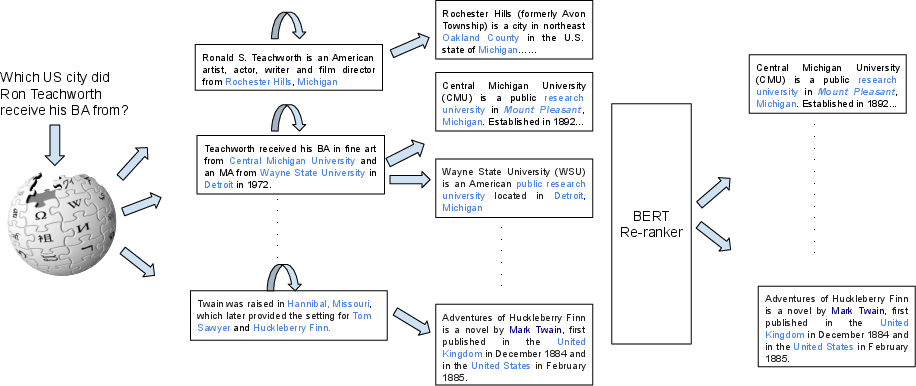
Figure 2: Overview of the entity-centric multi-step retrieval pipeline with joint entity linking and chain scoring, including self-loops for non-hop queries.
The training objective marks chains as positives if the final paragraph is an annotated supporting fact in HotpotQA; negatives are sampled otherwise. Chains are constructed up to length two, with a standard binary cross-entropy loss.
Experimental Results
Empirical evaluation on HotpotQA demonstrates the superiority of the proposed model over classical IR baselines and recent neural re-rankers. The key strong numerical result is an absolute increase of 26.5% in retrieval accuracy@10 and 18.4% in MAP compared to the BERT re-ranker baseline. Results for query expansion methods (Prf-tfidf, Prf-rm, Prf-task) underperform, emphasizing the necessity of explicit entity linkage rather than frequency-based expansion.
Ablation Studies
Ablation reveals that modeling document chains—rather than isolated entity paragraphs—dramatically improves retrieval performance, especially for queries requiring reasoning across bridge entities.
Applicability to Single-Hop Queries
The retrieval model's self-loop mechanism grants it robustness to single-hop queries. As empirical results indicate, performance does not degrade on such queries, confirming the model's practical utility beyond strictly multi-hop setups (Figure 3).
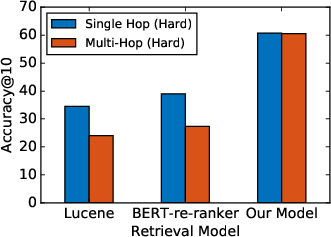
Figure 3: Retrieval model performance for both single-hop and multi-hop queries, enabled by self-loops in the evidence chain graph.
By providing the top-10 retrieved paragraphs to an unmodified QA reader, the answer F1 score increases by 10.59 points compared to the baseline. This demonstrates that improved retrieval translates to substantial gains for downstream QA—even with basic reader architectures.
Zero-Shot Generalization
On the Wikihop dataset, the trained entity-centric retriever outperforms both BM25 and BERT re-ranker in a zero-shot transfer setting. This suggests that the entity-centric chaining strategy generalizes across datasets without additional tuning.
Practical and Theoretical Implications
The entity-centric retrieval paradigm directly addresses the deficiencies of lexical-matching and frequency-based expansion for multi-hop QA. Integrating contextualized entity representations and joint scoring of paragraph chains exploits semantic bridges between evidence that standard retrieval ignores. Practically, the pipeline remains modular, allowing substitution of upstream IR or entity tagging systems.
The use of BERT embeddings places the approach in the family of neural IR models, further demonstrating the power of deep contextualized representations for complex downstream tasks. The model is not dependent on structured knowledge graphs, utilizing only textual entity descriptions, which enhances applicability.
From a theoretical perspective, explicit chain modeling extends prior IR work by formalizing retrieval as a graph traversal problem augmented by neural scoring functions. The framework suggests a direction for integrating latent knowledge graph construction into neural retrieval, leveraging contextual signals over explicit links.
Future Directions
Several promising avenues warrant exploration:
- Joint training of entity tagging and linking with the retrieval pipeline, increasing end-to-end coherence.
- Extending chain length beyond two hops for tasks requiring longer reasoning paths.
- Incorporating more advanced reader models to assess further downstream gains.
- Applying entity-centric chaining in other domains (scientific QA, open-domain dialog), exploring transferability and adaptations.
Conclusion
This work advances multi-hop QA with a multi-step, entity-centric retrieval approach, combining efficient entity linking and neural chain scoring. Its strong empirical improvements in both retrieval and QA accuracy, modular design, and generalization abilities underscore the importance of explicit entity-based chaining in designing high-performance open-domain QA systems.