- The paper presents a novel AMS pre-training strategy that aligns, masks, and selects concepts to create a multi-choice QA dataset from ConceptNet.
- The AMS method significantly boosts commonsense reasoning, with BERT_CS_large achieving 5.5% and 3.3% improvements on CSQA and WSC respectively.
- The approach maintains robust general language performance while suggesting that multi-choice QA pre-training outperforms traditional masked language modeling.
Align, Mask and Select: Incorporating Commonsense Knowledge into LLMs
The paper "Align, Mask and Select: A Simple Method for Incorporating Commonsense Knowledge into Language Representation Models" (1908.06725) introduces a pre-training methodology to inject commonsense knowledge into language representation models, specifically BERT. The approach centers around an "align, mask, and select" (AMS) method for automated construction of a multiple-choice question answering dataset derived from ConceptNet and a large text corpus. This pre-training strategy aims to enhance commonsense reasoning capabilities without compromising the general language understanding abilities of the model.
Methodology: Align, Mask, and Select (AMS)
The AMS method is designed to create a multi-choice question answering dataset from a commonsense knowledge graph (KG) and a large text corpus. The process involves three key steps, as illustrated in Table 1:
- Align: Align triples of (concept1, relation, concept2) in the filtered triple set to the English Wikipedia dataset to extract sentences containing the two concepts.
- Mask: Replace either concept1 or concept2 in a sentence with a special token [QW], thus transforming the sentence into a question where the masked concept is the correct answer.
- Select: Generate distractor answer choices by identifying concepts that share the same relation with the unmasked concept in ConceptNet.
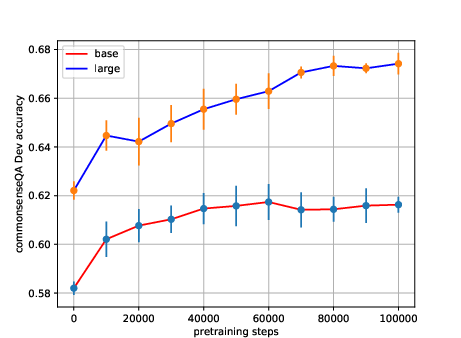
Figure 1: BERT_CSbase and BERT_CSlarge accuracy on the CSQA development set against the number of pre-training steps.
The paper filters ConceptNet triples to retain only those relevant to commonsense reasoning. The triples are filtered based on the following criteria: the concepts must be English words, the relations should not be too general ("RelatedTo" or "IsA"), and the concepts should meet length and edit distance requirements. The final dataset, denoted as DAMS, comprises 16,324,846 multi-choice QA samples.
Pre-training and Fine-tuning
The BERT_CS models, both base and large, are initialized with pre-trained weights from Google's BERT models and then further pre-trained on the generated DAMS dataset using a multi-choice QA task. The objective function used during pre-training is:
L=−logp(ci∣s)
${\rm p}(c_i|s) = \frac{\rm exp}(\mathbf{w}^{T}\mathbf{c}_{i})}{\sum_{k=1}^{N}{\rm exp}(\mathbf{w}^{T}\mathbf{c}_{k})}$
where ci is the correct answer, w represents parameters in the softmax layer, N is the number of candidates, and ci represents the vector representation of the [CLS] token.
Following pre-training, the BERT_CS models are fine-tuned on downstream NLP tasks, with a particular focus on commonsense reasoning benchmarks.
Experimental Results
The paper evaluates the proposed approach on two commonsense reasoning benchmarks, CommonsenseQA (CSQA) and Winograd Schema Challenge (WSC), as well as the GLUE benchmark for general language understanding. The results indicate that BERT_CS models achieve significant improvements on CSQA and WSC compared to baseline BERT models and previous state-of-the-art models. Specifically, BERT_CSlarge achieved a 5.5% absolute gain over the baseline BERTlarge model on the CSQA test set. On the WSC dataset, BERT_CSlarge achieved a 3.3% absolute improvement over previous state-of-the-art results. Furthermore, the BERT_CS models maintain comparable performance on the GLUE benchmark, demonstrating that the proposed pre-training approach does not degrade the general language representation capabilities of the models.
Ablation Studies and Analysis
The paper includes ablation studies to analyze the impact of different data creation approaches and pre-training tasks. Key findings from the ablation studies include:
- Pre-training on ConceptNet benefits the CSQA task, even when using triples as input instead of sentences.
- Constructing natural language sentences as input for pre-training BERT performs better on the CSQA task than pre-training using triples.
- Using a more difficult dataset with carefully selected distractors improves performance.
- The multi-choice QA task works better than the masked language modeling (MLM) task for the target multi-choice QA task.
Error analysis on the WSC dataset reveals that BERT_CSlarge is less influenced by proximity and more focused on semantics compared to BERTlarge.
Implications and Future Directions
This research has several implications for the field of NLP. The AMS method provides a way to incorporate structured knowledge from KGs into unstructured LLMs in an automated fashion. The approach improves the commonsense reasoning capabilities of LLMs, a long-standing challenge in AI. The finding that a multi-choice QA task is more effective than MLM for pre-training on commonsense knowledge suggests new avenues for exploration in pre-training strategies. Future work may focus on scaling the approach to larger KGs and LLMs, as well as exploring different pre-training tasks and fine-tuning strategies. Additionally, incorporating commonsense knowledge into models such as XLNet and RoBERTa is a promising direction for future research.
Conclusion
The paper "Align, Mask and Select: A Simple Method for Incorporating Commonsense Knowledge into Language Representation Models" (1908.06725) presents a practical and effective approach for incorporating commonsense knowledge into language representation models. By pre-training BERT models on a multi-choice QA dataset constructed using the AMS method, the authors demonstrate significant improvements on commonsense reasoning tasks while maintaining performance on general language understanding tasks. The ablation studies provide valuable insights into the design of pre-training strategies for commonsense reasoning, and the error analysis sheds light on the strengths and limitations of the proposed approach. This research contributes to the growing body of work on knowledge-enhanced LLMs and opens up new avenues for future research in this area.