- The paper demonstrates that TPUs excel in throughput for CNNs while GPUs offer flexibility for fully connected models, each showing distinct performance benefits.
- The study utilizes the parameterized ParaDnn suite and roofline analysis to reveal how model hyperparameters and memory bandwidth constraints affect FLOPS utilization.
- The research highlights that software stack updates and optimized data infeed can significantly boost performance, balancing multi-chip communication overhead.
The paper "Benchmarking TPU, GPU, and CPU Platforms for Deep Learning" (1907.10701) provides a comprehensive analysis of the performance characteristics of three major hardware platforms used for training deep learning models: Google's Tensor Processing Units (TPUs), NVIDIA's Graphics Processing Units (GPUs), and Intel's Central Processing Units (CPUs). Using the ParaDnn benchmark suite, the research evaluates the strengths and weaknesses of each platform across different types of neural networks.
ParaDnn Benchmark Suite
Description
ParaDnn is a parameterized benchmark suite that generates a wide range of deep learning models, including fully connected (FC), convolutional (CNN), and recurrent (RNN) neural networks. This suite allows for systematic benchmarking across several orders of magnitude of model parameter sizes, enabling a detailed analysis of how different hardware configurations handle diverse network architectures.
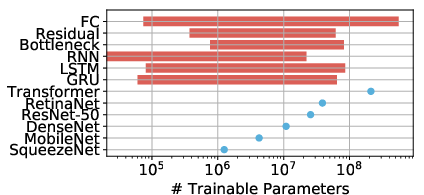
Figure 1: The numbers of trainable parameters for all workloads in this paper. Those from ParaDnn range from 10k to nearly a billion parameters, which is larger the range of real workload sizes, shown as dots.
FLOPS Utilization
The study first analyzes the floating point operations per second (FLOPS) utilization across platforms. The ParaDnn suite enables the visualization of how model hyperparameters influence FLOPS utilization on TPUs. Notably, TPUs effectively exploit parallelism from batch size and model width but underutilize the parallelism from model depth.
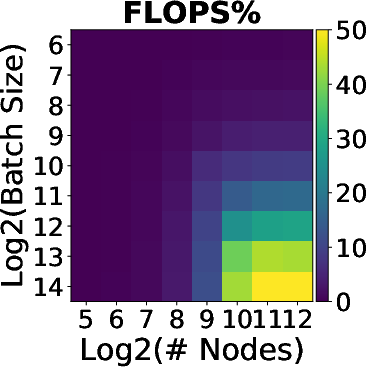
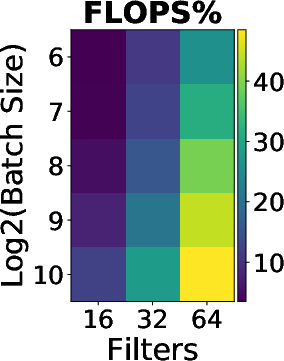
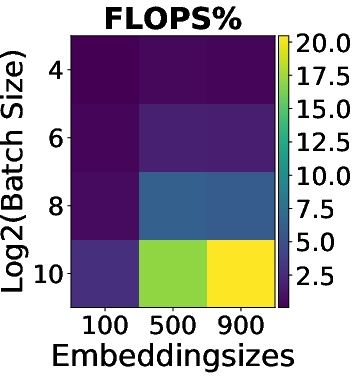
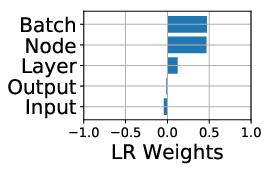
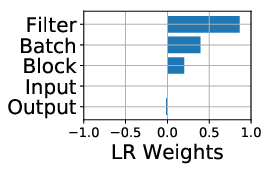
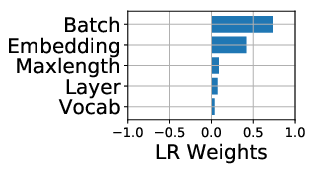
Figure 2: FLOPS utilization and its correlation with hyperparameters. (a)--(c) show FLOPS utilization of parameterized models. (d)--(f) quantify effects of model hyperparameters on FLOPS utilization, using linear regression weights.
Roofline Analysis
A Roofline model analysis demonstrates that while TPUs show significant computational capabilities, memory bandwidth bottlenecks persist, especially for operations outside of matrix multiplication. Despite this, models like Transformer and ResNet-50 achieve substantial FLOPS utilization when data-feeding issues are mitigated.
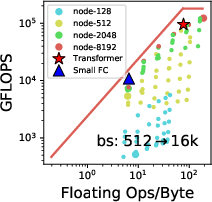
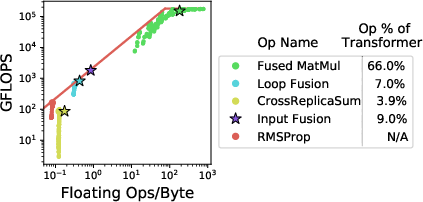
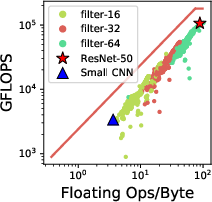
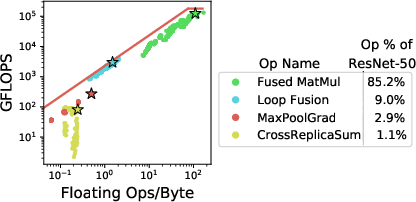
Figure 3: Rooflines for FC and CNN on TPU. Workloads with matrix multiply (MatMul) operations are compute-bound. Even compute-bound workloads like Transformer and ResNet-50 have more than 10\% memory-bound operations. (a) and (c) show rooflines of parameterized and real-world models. (b) and (d) show the operation breakdown.
Multi-Chip and Host-Device Balances
The communication overhead in multi-chip TPU systems can be substantial but is reduced with increased batch sizes. Moreover, balancing data infeed capabilities between the CPU host and TPU device is crucial, as data preparation can significantly affect overall training efficiency, especially when using reduced precision data types like bfloat16.
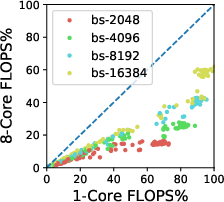
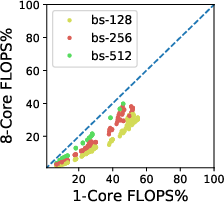
Figure 4: Communication overhead in a multi-chip system is non-negligible, but is reduced with large batch sizes.
The cross-platform analysis highlights distinct strengths for each hardware:
- TPU: Highly optimized for large batches and CNNs, showing the highest throughput among evaluated models.
- GPU: Offers better flexibility for irregular computations, supporting larger fully connected models thanks to its advanced memory system.
- CPU: Best programmability and memory capacity, allowing it to support the largest models, albeit at lower throughput.
The speedup analysis reveals TPUs consistently outperform GPUs and CPUs for certain models, although large fully connected models favor GPUs due to their superior memory bandwidth.
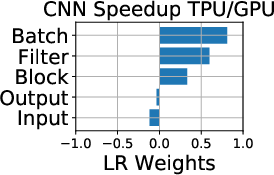
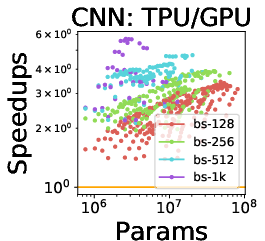
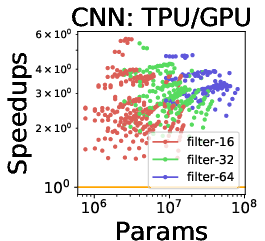
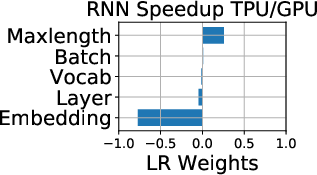
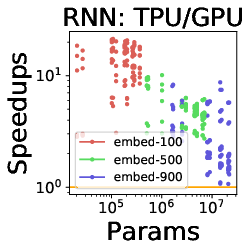
Figure 5: (a)--(c) TPU is a better choice than GPU for large CNNs, suggesting that TPU is highly-optimized for CNNs. (d)--(e) While TPU is a better choice for RNNs, it is not as flexible as GPU for embedding computations.
Software Stack Enhancements
The performance of TPUs and GPUs has significantly improved with recent updates in TensorFlow and CUDA. Software optimizations have yielded up to 9.7× performance improvements for RNNs, indicating that continuous software advancements play a critical role in leveraging the full potential of hardware capabilities.
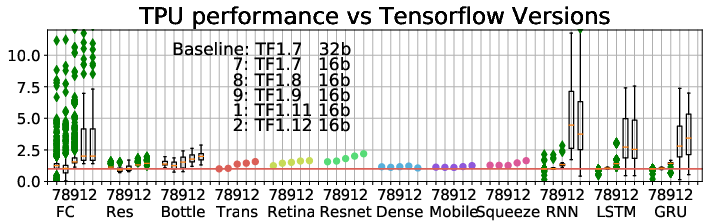
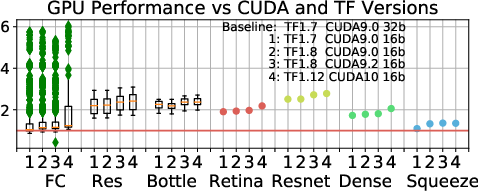
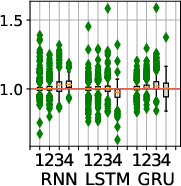
Figure 6: (a) TPU performance with TensorFlow updates. All ParaDnn models improve; Transformer, RetinaNet, and ResNet-50 improve steadily. (b) GPU speedups across versions of CUDA and TF. CUDA 9.2 improves CNNs more than other ParaDnn models, and ResNet-50 more than other real models. CUDA 10 does not improve RNNs or SqueezeNet.
Conclusion
The comprehensive benchmarking presented in the paper underscores the importance of domain-specific hardware and software design in deep learning model training. While TPUs showcase exceptional capability with certain workloads, GPUs and CPUs also maintain relevance across specific neural network types and sizes. Continued innovation in hardware specialization and software optimization remains vital for advancing training efficiency and accommodating the rapid evolution of deep neural networks.

