- The paper introduces a novel Experience Replay Optimization (ERO) framework that learns an adaptive replay policy for selecting valuable transitions.
- It employs a dual-policy update mechanism using policy gradients to enhance sample efficiency and stabilize off-policy reinforcement learning.
- Experimental evaluations on continuous control tasks demonstrate ERO's superior performance compared to traditional and TD error-based replay strategies.
Experience Replay Optimization: A Detailed Analysis
This essay examines the "Experience Replay Optimization" as proposed by Daochen Zha, Kwei-Herng Lai, Kaixiong Zhou, and Xia Hu. The paper introduces a novel experience replay optimization (ERO) framework, which enhances the effectiveness of off-policy reinforcement learning (RL) algorithms by optimizing the experience replay process.
Introduction to Experience Replay Optimization
Traditional experience replay mechanisms in reinforcement learning help stabilize the learning process by breaking temporal correlations. However, existing replay strategies, predominantly uniform sampling or rule-based approaches such as prioritizing experiences by temporal difference (TD) errors, are deemed sub-optimal. The proposed solution, ERO, addresses this limitation by formulating experience replay as a learning problem. ERO maintains two policies: the agent policy and an additional replay policy, with the latter responsible for selecting valuable experiences from the buffer to maximize cumulative rewards.
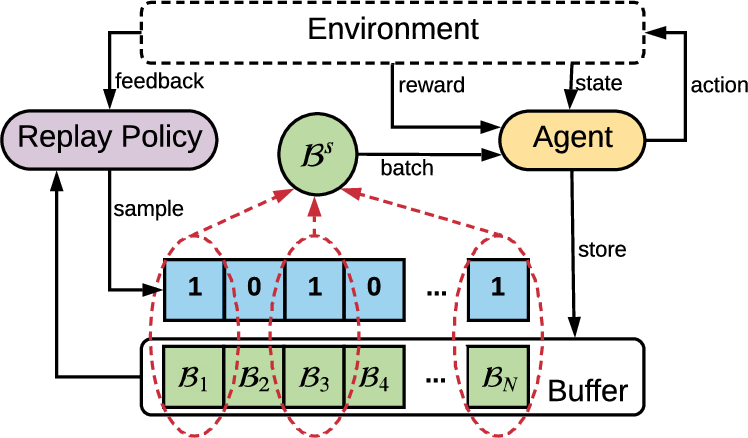
Figure 1: An overview of experience replay optimization (ERO). The reinforcement learning agent interacts with the environment and stores the transition into the buffer. In training, the replay policy generates a vector to sample a subset of transitions Bs from the buffer, where $1$ indicates that the corresponding transition is selected. The sampled transitions are then used to update the agent.
Methodology
ERO implements a dual-policy update method: the agent policy is trained to maximize cumulative rewards, while the replay policy learns to sample transitions that augment agent policy improvement. The replay policy, formulated as a function of transition features, outputs a priority score guiding the sampling from replay buffer (Figure 1).
Sampling with Replay Policy
The replay policy computes a priority vector for transitions, subsequently generating a binary vector indicating the selected transitions (1 for selected) used during training. This approach targets transitions that provide maximum utility based on recent agent performance feedback.
Training with Policy Gradient
The replay policy leverages a policy gradient approach, utilizing REINFORCE to adjust based on replay-reward calculated from the difference in agent performance before and after a replay update. This enables adaptive learning from the environment's responses, shaping future sampling decisions.
Integration with Off-Policy Algorithms
As an illustrative integration, ERO is applied to the Deep Deterministic Policy Gradient (DDPG) algorithm. The adaptation involves utilizing the replay policy to refine which transitions DDPG trains on, thereby enhancing sample efficiency and learning stability.
Experimental Evaluation
The ERO framework was empirically tested on a suite of continuous control tasks within OpenAI Gym, revealing superior performance compared to both vanilla DDPG and other rule-based prioritized experience replay methods.

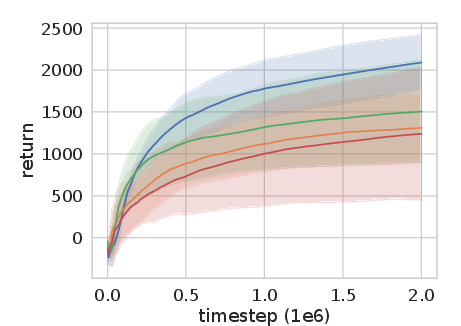
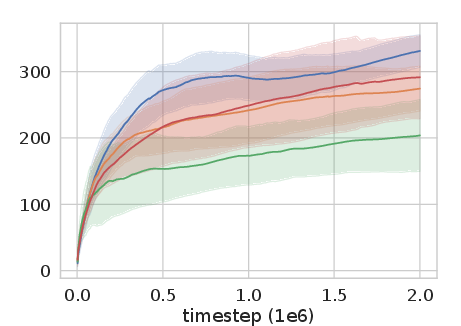
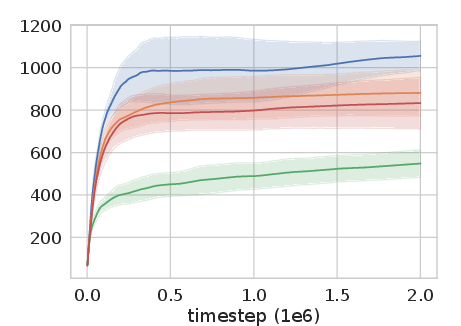
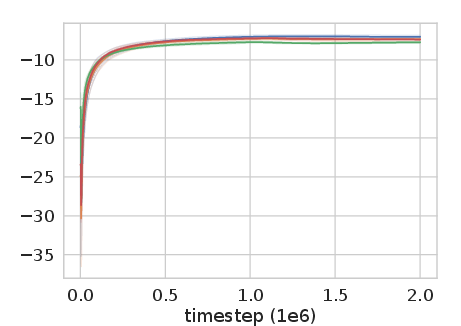
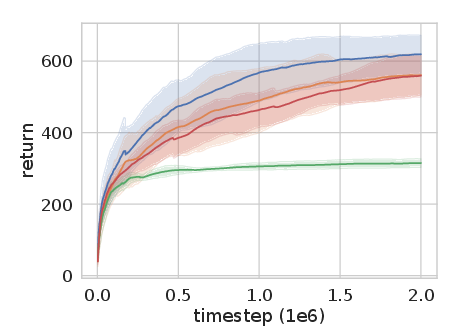
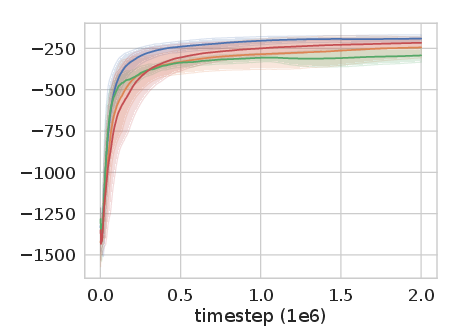
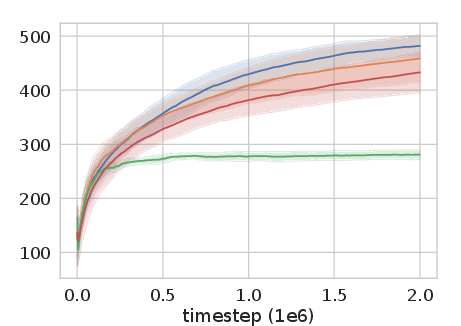
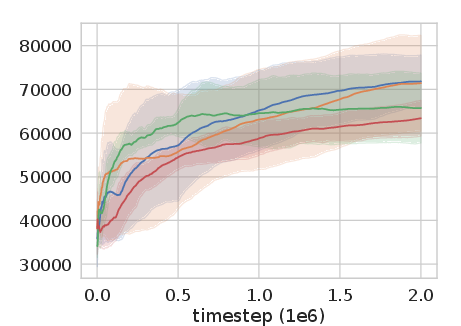
Figure 2: Experience Replay Optimization on HalfCheetah-v2 among other continuous control tasks shows significant improvement over baseline methods.
Empirical Analysis of Sampling Decisions
ERO demonstrated a predilection for transitions with lower TD errors yet higher recency, suggesting a refined approach to sampling that diverges from the traditional high-TD bias of other strategies.
Figure 3: The evolution of TD error, timestep difference, and reward of the transition over time shows distinctive preferences of ERO compared to rule-based strategies.
Implications and Future Directions
ERO's learning-based approach to experience replay paves the way for more contextually adaptable reinforcement learning systems, with potential extensions into buffer management strategies such as adaptive transition storage and replay volume configurations. Future studies could focus on broader integrations with other off-policy algorithms and applications within continual learning scenarios.
Conclusion
The Experience Replay Optimization framework offers a compelling advancement in the reinforcement learning domain, replacing static sampling strategies with an adaptive, learning-based mechanism that leverages environmental feedback. By tailoring replay strategies through a learned policy, ERO not only enhances current off-policy algorithm performance but also sets a precedent for future RL research in devising more sophisticated, task-adaptive replay dynamics.

