- The paper introduces a meta-learning framework, ML³, that automatically learns a parametric loss function to guide model optimization across various tasks.
- It employs nested optimization loops where the inner loop trains the model using the learned loss and the outer loop refines the loss function based on task performance.
- Experiments show that the learned meta-loss improves convergence speed and robustness in complex optimization settings, benefiting both supervised and reinforcement learning scenarios.
"Meta-Learning via Learned Loss" explores a framework that automates the learning of loss functions intended to optimize models over multiple tasks. This framework, referred to as ML3, leverages meta-learning to develop parametric loss functions that generalize across various tasks and architectures. The proposed methodology attempts to optimize models more efficiently by using learned loss signals rather than traditional hand-crafted losses.
Learning Framework and Approach
The core idea of the paper is to learn a parametric loss function, or meta-loss, which generalizes across training contexts or tasks and assists in optimizing the parameters of another model, referred to as the optimizee. The framework consists of nested optimization loops:
- Inner Loop: It trains the model (optimizee) using gradient descent with the learned meta-loss as the gradient signal.
- Outer Loop: It refines the parameters of the meta-loss by utilizing a task-specific loss that assesses the performance of the optimizee trained in the inner loop.
The paper demonstrates that these learned loss functions can better shape the loss landscapes when compared to task-specific losses, enhancing convergence speed and robustness across diverse tasks. The framework is adaptable enough to include additional guidance during meta-training, like expert demonstrations or exploratory signals for RL tasks, which do not need to be supplied during meta-testing.
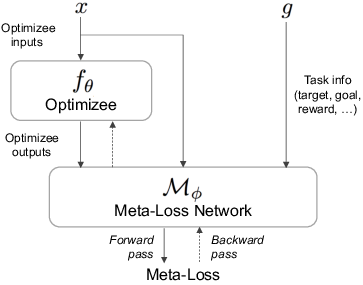
Figure 1: Framework overview: The learned meta-loss is used as a learning signal to optimize the optimizee fθ, which can be a regressor, a classifier, or a control policy.
Implementation in Supervised and Reinforcement Learning
The framework is applied to both supervised learning and reinforcement learning (RL) scenarios.
Supervised Learning
In supervised settings, the task is to learn a loss function Mϕ for regression and classification problems. The aim is to encode strategies into a single meta-loss that is more effective than the ground truth or task-specific losses alone. The methodology enables efficient optimization through improved loss landscapes.
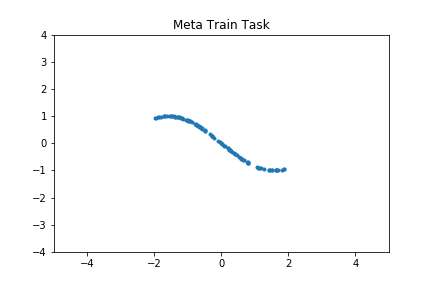
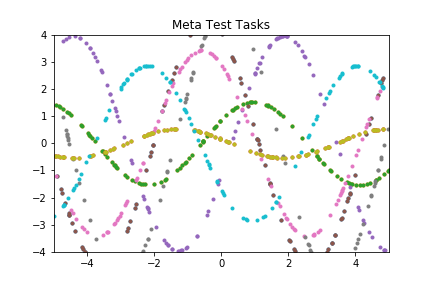



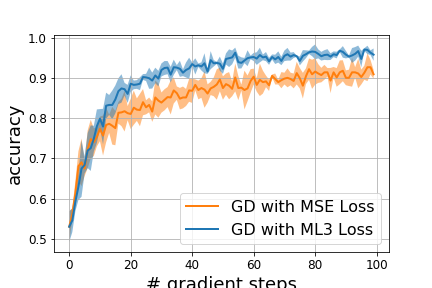
Figure 2: Meta-learning for regression (top) and binary classification (bottom) tasks. (a) meta-train task, (b) meta-test tasks, (c) performance of the meta-network on the meta-train task as a function of (outer) meta-train iterations in blue, as compared to SGD using the task-loss directly in orange, (d) average performance of meta-loss on meta-test tasks as a function of the number of gradient update steps.
Reinforcement Learning
For RL, the meta-loss framework adapts to model-free and model-based paradigms, illustrated through tasks such as ReacherGoal and AntGoal environments. In these contexts, the meta-loss effectively guides policy learning, yet retains generality to work across diverse challenges encountered at test time.
Model-based Reinforcement Learning: Integration with a dynamics model allows for effective policy optimization in simulators, requiring the learned model's predictions only during meta-train time, simplifying test-time requirements.
Model-free Reinforcement Learning: Enhancement of sample efficiency by leveraging the meta-loss to facilitate task learning, reducing the reliance on computationally heavy methods like PPO during test phases.
Experiments and Evaluations
The experiments demonstrate that learned meta-loss functions can surpass standard task losses in terms of training efficiency and final performance. The authors provide results indicating significant improvements in model training speed and flexibility across various domains, including regression, classification, model-based, and model-free reinforcement learning scenarios.
Shaping Loss Landscapes
By strategically incorporating additional information at meta-train time, the paper illustrates improvements in the convergence of non-convex problems, evident in applications like inverse dynamics learning in robot arms where using a shaped meta-loss resulted in higher sample efficiency.
The framework's flexibility in integrating supplementary information allows it to exploit expert demonstrations for enhanced learning from demonstrations, yielding improved task generalization capability without the need to present such information during testing phases.
Conclusion
The paper presents a generic framework that advances the efficiency of training paradigms by automating the learning of adaptable, generalizable loss functions. It emphasizes the potential of ML3 to address bottlenecks in traditional model training methods, opening avenues for exploration and application across numerous machine learning fields such as robotics and AI-driven control systems. Future undertakings might investigate adaptive combinations of multiple learned loss functions, fostering broader applicability and capability in addressing complex real-world tasks.

