- The paper introduces a framework that prioritizes sequences of transitions to propagate significant rewards backward, enhancing learning efficiency.
- It employs a decay mechanism with parameters ρ and η to maintain important information and prevent priority collapse.
- Empirical evaluations show PSER outperforms PER in Atari 2600 games, with marked improvements in convergence speed in 40 out of 60 games.
Prioritized Sequence Experience Replay
This paper introduces Prioritized Sequence Experience Replay (PSER), an advanced framework aimed at enhancing experience replay in reinforcement learning (RL) by prioritizing sequences of transitions rather than individual transitions. The focus is on improving efficiency and performance beyond what is achieved with existing Prioritized Experience Replay (PER) mechanisms. The proposed methodology demonstrates theoretical guarantees for faster convergence and empirical performance improvements in standard benchmarks such as the Atari 2600 suite.
Background and Motivation
RL algorithms like DQN leverage experience replay to stabilize training by breaking the correlation between sequential observations. While PER improves the efficiency of experience replay by favoring transitions with high temporal-difference (TD) errors, it does not account for the significance of entire transition sequences. PSER aims to address this limitation by propagating priorities backward within sequences, thereby enhancing the learning process by re-weighting transitions that lead up to significant states.
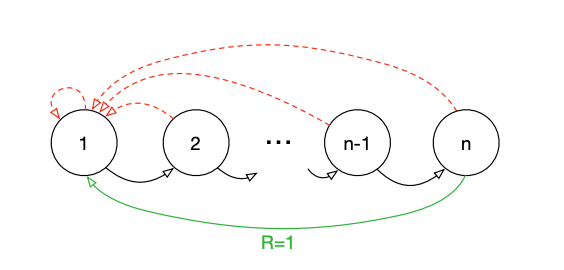
Figure 1: The Blind Cliffwalk environment. At each state, there are two actions available (correct and wrong). The agent learns to take the correct action to achieve the final reward.
Methodology
PSER modulates the transition priorities by decaying the priority of a novel transition to those preceding it in the trajectory, using a decay coefficient ρ. This framework involves a mechanism to prevent "priority collapse", whereby priorities rapidly revert to lower values. By introducing a retention parameter η, PSER maintains a portion of a transition's prior importance. Theoretical analysis indicates that this priority updating scheme ensures faster convergence than traditional PER, as evidenced in the Blind Cliffwalk environment.
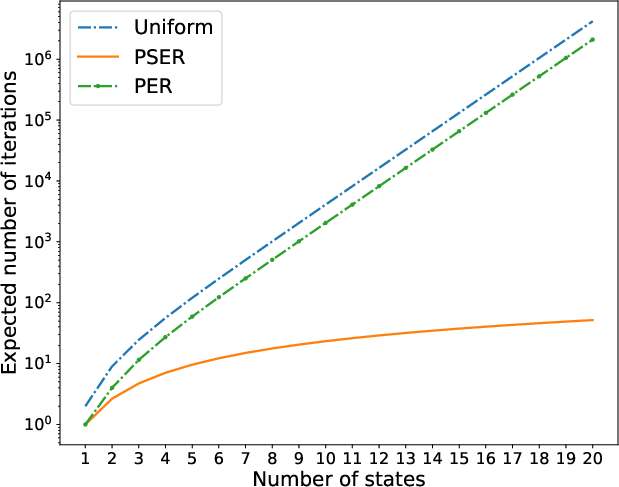
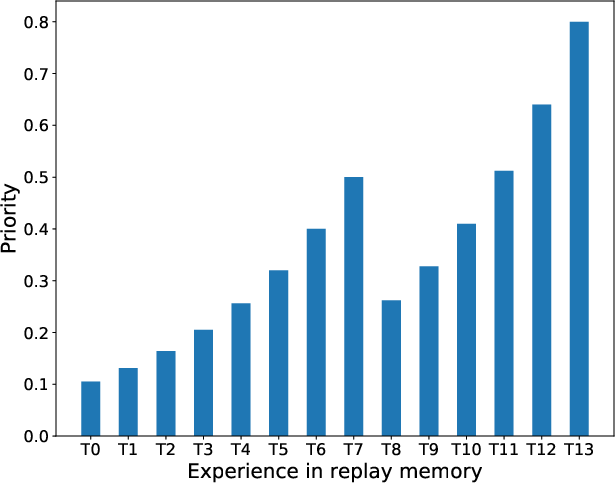
Figure 3: 16 states with all transitions initialized with max priority.
The PSER approach was integrated into DQN, offering an empirical evaluation against PER in a suite of 60 Atari 2600 games. The agents trained with PSER displayed superior learning efficiency and effectiveness across the suite, with significant improvements in 40 out of the 60 games.
Experimental Results
Experiments demonstrated that PSER not only outperforms PER in convergence speed within synthetic environments like Blind Cliffwalk but also delivers higher scores in the Atari 2600 benchmarks. Most notably, games with complex strategies or delayed rewards showed marked improvements, highlighting PSER's ability to exploit crucial transition sequences effectively.
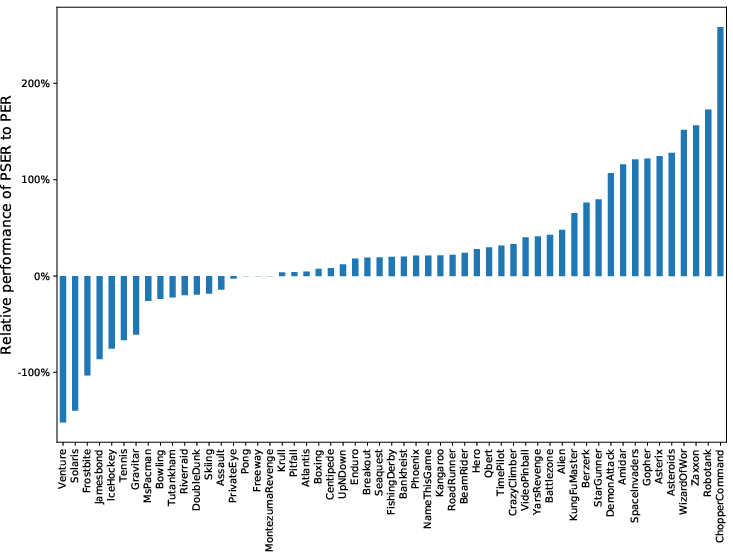
Figure 2: Relative performance of PSER to PER in Atari 2600 games, indicating the superiority of PSER in a majority of cases.
An ablation study further analyzed the impact of initial priority assignments and decay strategies (MAX vs. ADD) on PSER performance. Results underscored that the MAX strategy, where priorities are not allowed to decline below previously calculated decays, consistently provided better outcomes across varied game types.
Implications and Future Work
PSER enhances the experience replay mechanism crucial for RL agents operating under limited interaction budgets, such as robotics and resource-constrained environments where simulation may not be feasible. The introduction of sequence-based priority adjustments could yield rich dividends in real-world applications requiring nuanced decision-making based on historical context.
Future work involves integrating PSER with modernized RL architectures like Rainbow or AlphaZero to capture a broader range of RL problems. Additionally, adaptive decay mechanisms to fine-tune the decay window size W based on dynamic learning objectives or environmental complexity present a promising avenue for exploration.
Conclusion
The PSER framework significantly advances the efficiency and efficacy of experience replay in RL by prioritizing transition sequences, thus facilitating better information flow and learning. Its implementation within DQN has empirically demonstrated faster convergence and superior performance over standard benchmarks, marking a noteworthy step towards the next generation of RL systems that can learn robustly from sparse and complex reward structures.