- The paper presents a hierarchical reinforcement learning framework that decomposes complex quadruped locomotion tasks into high-level strategic decisions and low-level actuator commands.
- It employs neural network policies optimized via Augmented Random Search to efficiently tune distinct state representations and control frequencies.
- Experimental results in simulation and hardware demonstrate enhanced path-following performance and transferability over traditional flat policies.
Hierarchical Reinforcement Learning for Quadruped Locomotion
The paper "Hierarchical Reinforcement Learning for Quadruped Locomotion" presents a novel framework designed to tackle the complexity of quadruped robot locomotion through hierarchical reinforcement learning (HRL). This approach distinguishes itself by its ability to decompose intricate locomotion tasks into manageable sub-tasks, thus enabling efficient policy adaptation and deployment in both simulated and real environments.
Introduction and Motivation
Quadruped locomotion presents a multifaceted challenge due to the necessity of precise actuator control and leg coordination, particularly across varying terrains and tasks. This study proposes a hierarchical learning architecture that encapsulates high-level decision-making and low-level control, enabling the reuse of foundational movement skills and improving interpretability of decision-making processes.
The challenge traditionally associated with defining task-specific hierarchies is addressed by automatizing the decomposition process. This paper introduces a high-level policy that commands a low-level policy by issuing directives in a latent space while optimizing the execution timeframe for each task. This approach ensures the high-level policy operates on a reduced frequency, aligning with the lower-level policy's rapid command cycles.
Methodology
Hierarchical Policy Structure
The proposed architecture segregates tasks between a high-level policy, which determines strategic outcomes and latent commands, and a low-level policy that translates these commands into actuator-level actions (Figure 1). Each policy is represented by a neural network, which is trained end-to-end, thereby optimizing the system holistically across the task space.

Figure 1: Simulated task on the left and the robot performing a hierarchical policy learned in simulation.
Training Algorithm
The training paradigm is constructed around a Markov Decision Process (MDP) framework, utilizing Augmented Random Search (ARS) to optimize the reward functions inherent to both policy levels. This allows for the simultaneous tuning of high-level decision strategies and low-level execution nuances.
For the practical implementation, a distinction is drawn between the state representations accessible to each policy tier. The high-level policy, working with a less frequent update cycle, receives strategic environmental data, whereas the low-level policy rapidly processes sensory feedback to maintain actuator control.
Transfer and Adaptation
One of the approach's noteworthy aspects is the ability to transfer learned low-level policies across different task environments. By reusing low-level skills, the system can adapt efficiently to new challenges, evidenced by successful applications to varied path-following tasks in simulations and real-world scenarios.
Experimental Results
Simulation and Real-World Deployment
The HRL architecture was validated through a set of experiments focusing on path-following tasks using a simulated quadruped robot, the Minitaur. Results indicate that steering behaviors naturally emerge within the latent command space, facilitating adaptable and transferable locomotion strategies in complex trajectories (Figure 2).
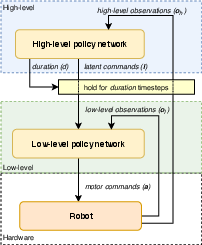
Figure 2: Robot path tracking in simulation. If the robot's center of mass exits the black area, the episode is terminated.
The application of hierarchical policies showcased improved learning rates and adaptability over baseline flat policies, and pre-defined hierarchical controllers, affirming the architecture's efficiency (Figure 3).
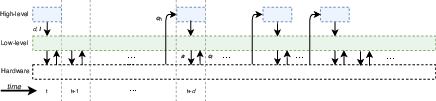
Figure 3: Learning curves for path 1. All policies are trained from scratch.
Hardware Validation
Real-world validation involved deploying the trained HRL policies to actual hardware, leveraging a motion capture system for position tracking and policy input. The results exhibited consistent path adherence and dynamic adjustments, thereby confirming the software-based simulation outcomes in tangible environments.
Conclusion
The research thoroughly demonstrates the efficacy of leveraging hierarchical reinforcement learning frameworks for quadruped locomotion. By introducing a latent command language and employing separate timescales for high and low-level executions, the approach significantly reduces computational burden and enhances adaptability, positioning it as a versatile tool for future robotic control applications.
Future work will likely explore extending this methodology to include more complex sensory inputs and integrate it into broader robotics systems, potentially tackling challenges involving dynamic environmental interactions and advanced motor tasks. The incorporation of visual and other sensory data could further enhance decision-making granularity and autonomy in sophisticated robotic systems.

