- The paper introduces a reinforcement learning architecture that treats task selection as an MDP to optimize competency across interdependent tasks.
- The approach integrates a dual-layer system with a goal selector and actor-critic networks, outperforming previous models in simulated iCub experiments.
- Results indicate that competence-based intrinsic motivation effectively drives learning efficiency in complex robotic task hierarchies.
Autonomous Open-Ended Learning of Interdependent Tasks
Introduction
The paper "Autonomous Open-Ended Learning of Interdependent Tasks" (1905.02690) addresses a significant challenge in robotic learning: enabling artificial agents to autonomously acquire a diverse array of skills necessary for behavioral adaptability in complex environments. While the autonomous learning of multiple tasks can be approached with various machine learning strategies, intrinsic motivations (IMs) have emerged as a crucial factor in driving self-governed exploration and skill acquisition. Intrinsic motivations provide task-agnostic reinforcement signals essential for guiding the development of competence across tasks.
The paper specifically deals with the issue of interdependent tasks in robotic settings, where mastering certain tasks might be contingent upon the successful execution of prerequisite tasks. Traditional hierarchical reinforcement learning approaches, although relevant, often do not fully embrace the autonomy required for such settings, especially when operating in non-discrete domains or relying on predefined external instructions. To overcome these limitations, the authors propose a system where task selection is treated as a Markov Decision Process (MDP), allowing for the strategic planning of skill acquisition to optimize overall competency development.
Approach
The authors present a reinforcement learning (RL) architecture designed for robot control that effectively learns multiple interdependent tasks through the framework of an MDP. The key innovation lies in treating task selection as an MDP, framing it as an optimization problem aimed at maximizing competence across goals rather than focusing solely on extrinsic rewards. This approach leverages a competence-based intrinsic motivation function, guiding the agent to allocate its learning resources to tasks promising the greatest competence gain.
The paper outlines a dual-layer system consisting of a goal selector and multiple task-specific actor-critic networks. The goal selector evaluates current and potential goal states and chooses tasks based on current competence improvement. This selection process is modeled as a multi-armed bandit problem with a focus on competence improvement, adapting to contextual cues.
Experimental Setup
The authors demonstrate their framework on a robotic platform using a simulated iCub robot. The iCub must learn to interact with objects in an environment where task feasibility depends on current environmental conditions or the successful completion of precursor tasks. The research incorporates two primary experimental settings:
- Contextual Bandit Setting: The robot must activate specific tasks contingent upon environmental features.

Figure 1: The simulated iCub robot in our experimental setup: when a sphere is touched (given its preconditions) it ``lights up'', changing its colour to green.
- MDP Setting with Interdependent Tasks: Tasks are interrelated such that completing one task is required before others can be attempted.
Results
The comparative analysis involves evaluating three systems: GRAIL (Goal-Related Autonomous Intrinsic Learning), C-GRAIL (Contextual-GRAIL), and M-GRAIL (Markovian-GRAIL). In the first experimental scenario evaluating task performance based on environmental states, C-GRAIL outperforms GRAIL due to its contextual awareness, successfully adapting task choices to environmental variability.
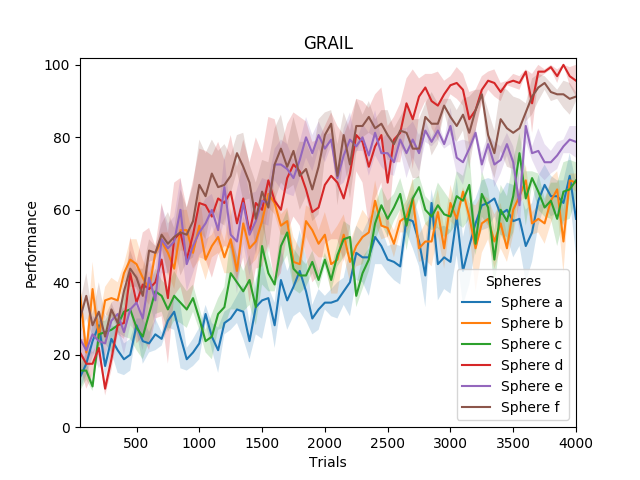
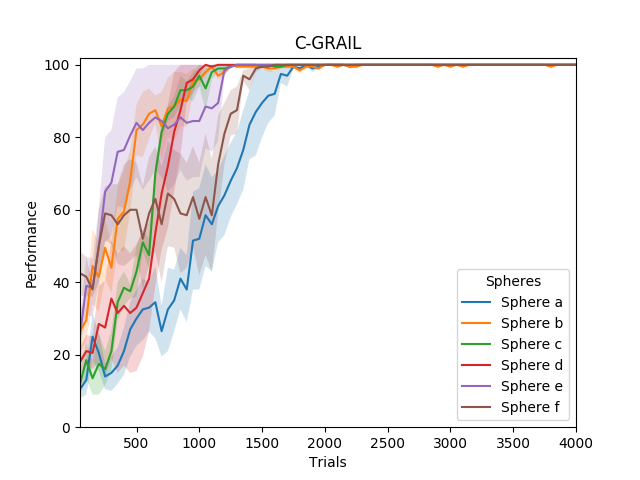
Figure 2: Performance of GRAIL and C-GRAIL in the first experiment.
In scenarios with interdependent tasks, M-GRAIL demonstrates superior learning efficiency and task execution. The M-GRAIL system capitalizes on Q-learning to propagate intrinsic motivations across goal hierarchies, facilitating the systematic fulfillment of required preconditions for complex goals more effectively than C-GRAIL, which occasionally fails due to random task selection as intrinsic motivations diminish.
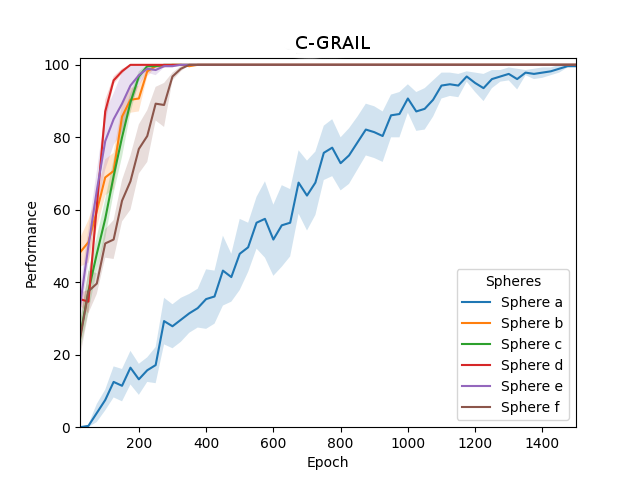
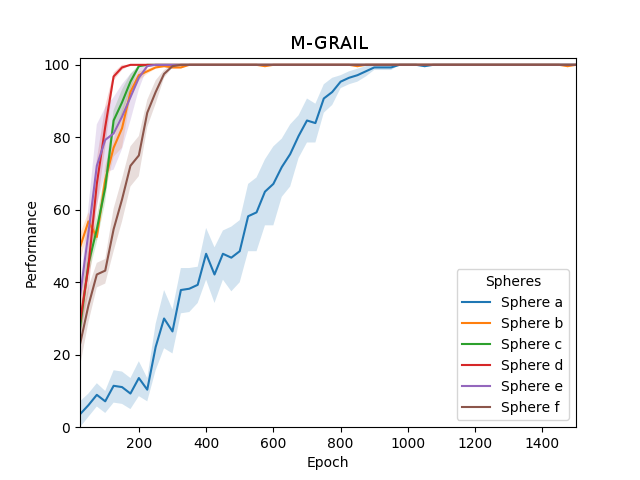
Figure 3: Performance of C-GRAIL and M-GRAIL over the 6 goals in the second experiment.
Conclusion
This paper contributes to the field of autonomous robotics by advancing a novel methodology for handling open-ended, interdependent task learning through intrinsic motivation-driven, hierarchical RL approaches. The proposed system shows promise for applications in autonomous systems requiring adaptive task acquisition in dynamic environments, highlighting the potential for further research in refining competence evaluation and goal selection mechanisms. Future advancements may involve further integration of adaptive learning strategies and more sophisticated competence metrics to enhance the robustness and versatility of autonomous robotic systems in real-world applications.

