- The paper introduces AMPERE, a newly annotated dataset of 14.2K peer reviews from top ML and NLP conferences for detailed argument mining analysis.
- It employs joint segmentation and classification techniques using models like BiLSTM-CRF with ELMo to identify proposition types and reveal venue-specific trends.
- The study highlights domain challenges in argument mining for peer reviews, providing insights to improve the quality and structure of scientific evaluations.
Argument Mining for Understanding Peer Reviews
This essay examines "Argument Mining for Understanding Peer Reviews" (1903.10104). The research aims to facilitate the analysis of peer reviews by adopting an argument mining framework, focusing on the segmentation and classification of argumentative propositions. The work introduces AMPERE, a newly annotated dataset, and evaluates existing models on it, unveiling the nuanced structural and content-based aspects of peer reviews across diverse academic venues.
Introduction
Peer reviews are integral to the scientific review process, providing critical evaluations and suggestions for research enhancement. This paper deploys an argument mining approach to scrutinize peer reviews' content and structure systematically. The argument mining framework categorizes propositions into types like Evaluation, Request, Fact, Reference, and Quote. A new dataset, AMPERE, comprising 14.2K reviews from prominent ML and NLP conferences, underpins this study. Annotated propositions allow for comprehensive automatic segmentation and proposition type classification, paving the way for deeper analysis.
AMPERE Dataset
AMPERE, a meticulously annotated dataset, serves as the cornerstone of this study. It contains reviews from ICLR, UAI, ACL, and NeurIPS. These reviews are annotated with 10,386 propositions identified as Evaluation, Request, Fact, Reference, Quote, or Non-argumentative. AMPERE highlights significant diversity in proposition distribution across different venues, suggesting that particular conferences emphasize particular proposition types.
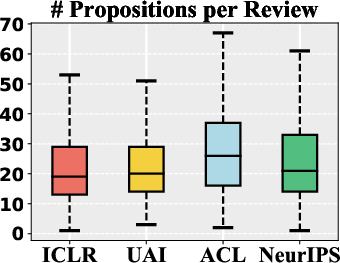
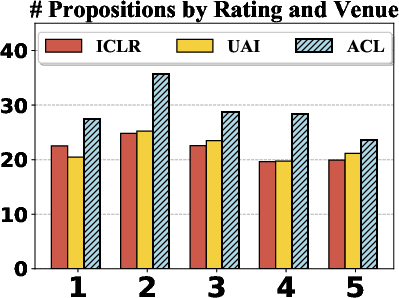
Figure 1: Proposition number in reviews. Differences among venues are all significant except UAI vs. ICLR and ACL vs. NeurIPS.
Segmentation and Classification Tasks
The paper's primary task is segmenting text into propositions and classifying these propositions. State-of-the-art models, including BiLSTM-CRF, show moderate success yet fall short compared to other domains like essays, indicating challenges unique to peer reviews. Evaluation and Fact emerge as the most frequent proposition types among reviews, while Requests show variance across venues, with ACL containing significantly more requests than others.
Venue-Based Analysis
The analysis reveals that ACL reviews typically include more propositions per review and contain more Requests and fewer Facts than their ML counterparts. Across ratings, extreme-rated reviews (strong reject or accept) are notably shorter and less prone to request propositions. This suggests that rating correlates with the rhetorical strategies reviewers employ, impacting how arguments are constructed and delivered.
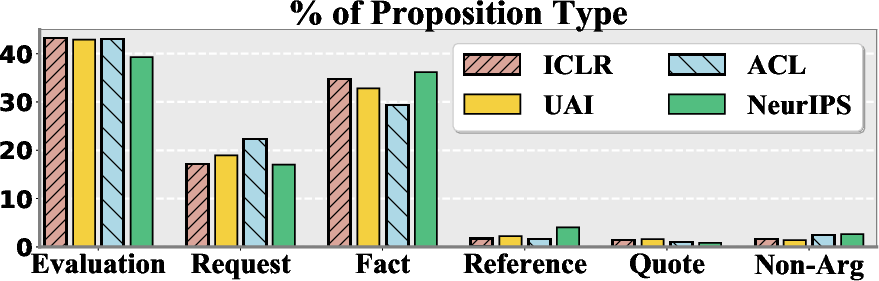
Figure 2: Distribution of proposition type per venue.
Results and Discussion
The research finds that, inherently, proposition segmentation within peer reviews is complex due to non-standard structure compared to other discourse types. Notably, 25% of sentences in peer reviews contain multiple propositions, a challenging scenario for existing models. Joint segmentation-classification models excel compared to non-joint methods, suggesting advantages in combined learning.
Implementation results demonstrated a decline in segmentation performance on AMPERE compared to datasets like essays, suggesting the need for novel arguments mining approaches in peer review contexts. Adopting enhanced baseline models (e.g., BiLSTM-CRF with ELMo embeddings) brought marginal improvements, underscoring the complexity and diversity in peer review argumentative structures.
Conclusion
This work showcases the potential of argument mining frameworks to analyze peer reviews, offering a comprehensive dataset and methodical insights into content and structure. The segmentation and classification reveal domain-specific challenges and opportunities, particularly highlighting distinct venue-based trends. The potential for deploying tailored argument mining techniques in peer review can foster more structured, constructive feedback, enhancing the scientific review process. Future directions can focus on refining models for better proposition segmentation and encompassing additional venues to verify patterns and extend applicability.

