- The paper presents an empirical evaluation of various GPU interconnects, detailing their impact on latency and bandwidth in multi-GPU setups.
- The paper uses comprehensive microbenchmarking to reveal significant NUMA effects and performance enhancements using NVLink and NVSwitch.
- The paper underscores the need for advanced multi-GPU programming models to fully leverage modern interconnects in HPC and deep learning applications.
Evaluating Modern GPU Interconnects: PCIe, NVLink, NV-SLI, NVSwitch, and GPUDirect
Introduction
The proliferation of complex multi-GPU setups has been driven by the constantly growing computational needs in areas like deep learning and high-performance computing (HPC). This paper thoroughly investigates the characteristics and performance implications of several cutting-edge GPU interconnect technologies, including PCIe, NVLink-V1/V2, NV-SLI, and NVSwitch, as well as GPUDirect-enabled InfiniBand. The goal is to provide empirical insights that inform optimal GPU communication configurations, enhance application performance models, and support multi-GPU execution frameworks.
Modern GPU Interconnect Technologies
The investigation covers several types of GPU interconnects:
Figure 3: NVSwitch interconnect topology in DGX-2.
- GPUDirect: By enabling direct memory access between GPUs and peripherals like InfiniBand adapters, GPUDirect reduces latency and increases bandwidth efficiency for inter-node GPU communications.
GPU Interconnect Microbenchmarking
Comprehensive microbenchmarking was conducted to analyze latency, bandwidth, and NUMA effects across various intranode and internode communication patterns:
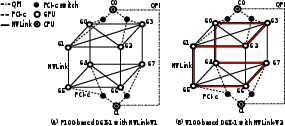
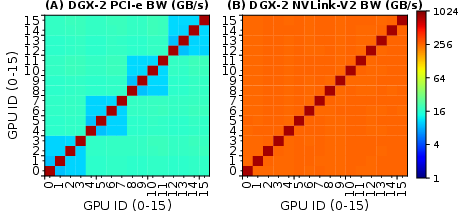
- Intra-node P2P Communication: Examined via PCIe, NVLink, NV-SLI, and NVSwitch, highlighting NUMA effects that arise from topology, connectivity, and routing. NVLink and NVSwitch generally demonstrated superior bandwidth capabilities compared to PCIe.
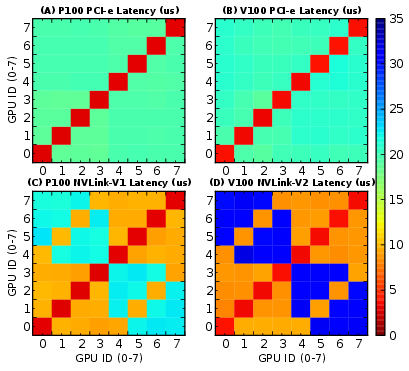
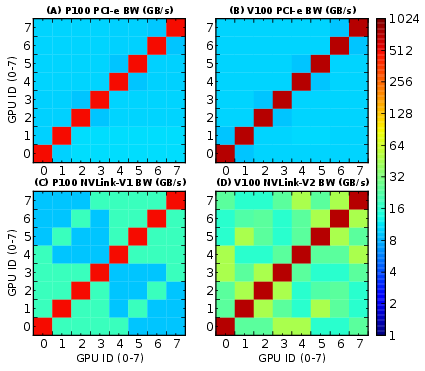
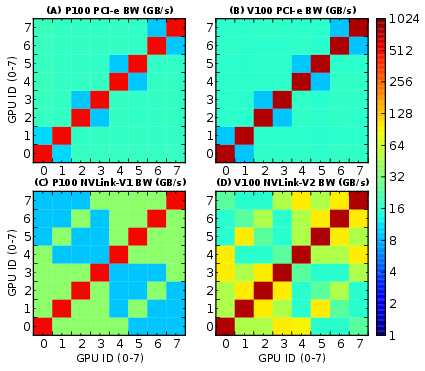
Figure 4: P100/V100-DGX-1 P2P communication latency indicative of NUMA effects.
- Intra-node CL Communication: Implementations leveraging NCCL showcased improvements in communication efficiency. Understanding the topology and integrating optimally structured communication patterns (e.g., ring networks) could mitigate potential bottlenecks.
- Inter-node P2P and CL Communication: Leveraging GPUDirect significantly improved bandwidth efficiency, contrasting scenarios with traditional memory access methods. Applications such as all-reduce could particularly benefit from the superior throughput of GPUDirect-RDMA.
Benchmarking and Observations
The study utilized the Tartan Benchmark Suite to analyze performance implications of these interconnect technologies on real-world multi-GPU applications, focusing on both scale-up and scale-out configurations:
- Intra-node Scale-up: Without optimizing for inter-GPU communication, strong scaling benefits from NVLink enhancements were limited. Further gains require a paradigm shift in parallelization models to capitalize on high-speed interconnects.

Figure 5: Normalized latency reduction by NVLink-V1 and NCCL-V2 of weak scaling for single-node scaling-up on NVIDIA P100-DGX-1.
- Inter-node Scale-out: Applications exhibited notable performance improvements when leveraging GPUDirect-RDMA, underscoring the necessity for efficient inter-node communication strategies. Faster interconnects, such as InfiniBand, present clear advantages in multi-node HPC settings.

Figure 6: Performance speedup by InfiniBand GPUDirect-RDMA of strong scaling for multi-node scaling-out on ORNL SummitDev.
Conclusion
This paper systematically evaluates the latest GPU interconnect technologies, elucidating their effects on HPC and machine learning applications. The distinct NUMA effects observed, along with the heterogeneous nature of these interconnect systems, highlight the need for robust multi-GPU programming models that can dynamically leverage these high-speed communication channels. Future developments should focus on refining multi-GPU execution frameworks and performance models to maximize the potential of modern GPU interconnects in computing environments.