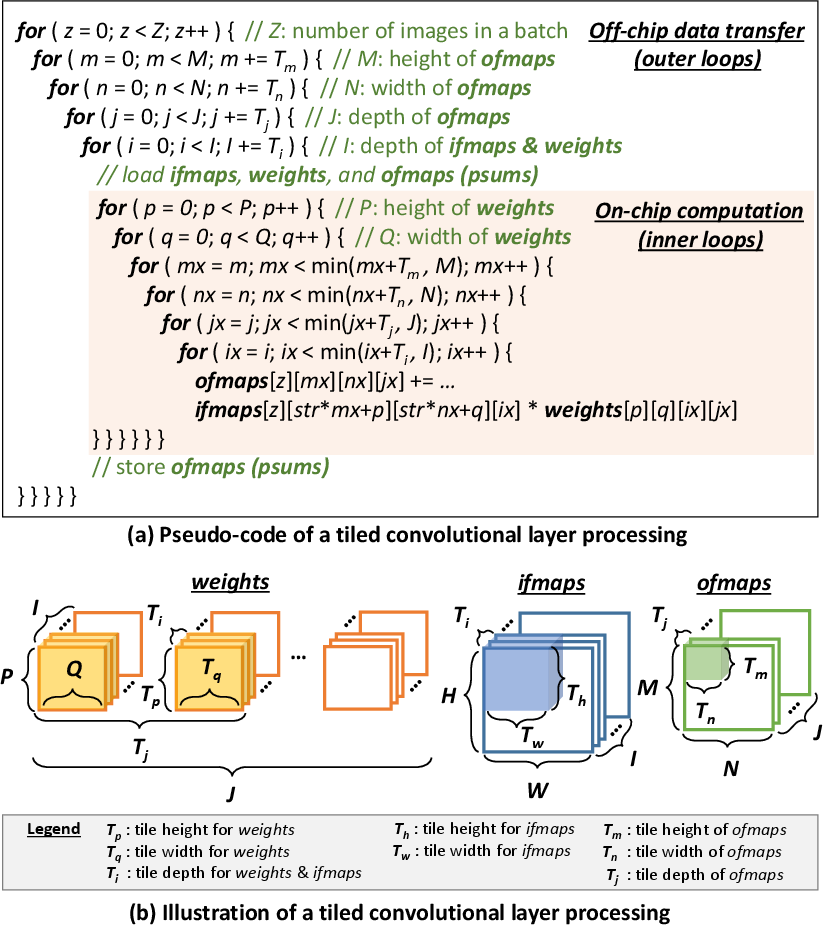
- The paper presents ROMANet, a reuse-driven DRAM access management strategy that minimizes redundant operations to reduce energy consumption in DNN accelerators.
- It employs a design space exploration approach with fine-grained layer partitioning and a novel DRAM data mapping technique, achieving up to 46% energy savings and 10% throughput improvements.
- Experiments on architectures such as AlexNet, VGG-16, and MobileNet validate ROMANet's scalability and effectiveness in enhancing performance in resource-constrained environments.
Overview of "ROMANet: Fine-Grained Reuse-Driven Off-Chip Memory Access Management and Data Organization for Deep Neural Network Accelerators"
Introduction
The paper, "ROMANet: Fine-Grained Reuse-Driven Off-Chip Memory Access Management and Data Organization for Deep Neural Network Accelerators," addresses the critical challenge of optimizing DRAM access energy in DNN accelerators by proposing a novel technique, ROMANet. The study highlights the significant portion of energy consumed by DRAM accesses in CNN architectures, demonstrating that effective management of DRAM operations is essential for enhancing energy efficiency.
Methodology
ROMANet optimizes DRAM access by intelligently partitioning layers and scheduling data transfers based on reuse factors. The paper introduces a design space exploration (DSE) approach that identifies optimal scheduling and partitioning configurations to minimize DRAM accesses. This methodology is predicated on:
- Reuse-Factor Analysis: Determining the reuse priority order for each layer based on factors such as ifmaps, ofmaps, and weights ensures maximum data reuse and minimum redundant operations.
- Layer Partitioning Models: Utilizing fine-grained layer partitioning models tailored for different data types (ifmaps, weights, ofmaps) allows efficient data fetching and minimizes overlap, reducing unnecessary DRAM accesses.
- DRAM Data Mapping: A novel DRAM mapping strategy designed to exploit row buffer hits and minimize conflicts while leveraging chip- and bank-level parallelism enhances throughput and reduces access energy.
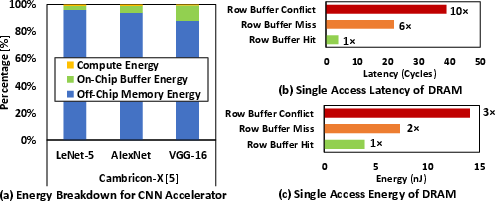
Figure 1: (a) Breakdown of the total energy consumption of CNN accelerator, i.e., Cambricon-X. DRAM access energy consumes >80% of the total energy.
Implementation and Experimental Setup
The evaluation of ROMANet is conducted using a state-of-the-art cycle-accurate DRAM simulator integrated into a comprehensive tool flow that estimates DRAM access energy. The experiments utilize popular DNN architectures, including AlexNet, VGG-16, and MobileNet, to demonstrate the scalability and effectiveness of ROMANet across different network topologies.
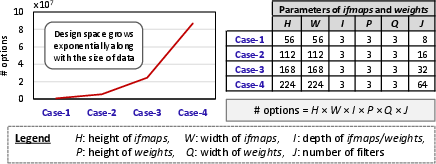
Figure 2: Estimated number of layer partitioning options to be investigated (left) in the design space for different cases listed in the table (right).
Results and Discussion
The experimental results confirm the substantial improvements provided by ROMANet. The methodology achieves DRAM access energy savings by up to 46% for MobileNet, improved throughput by 10%, and significant reductions in row buffer conflicts and misses compared to previous state-of-the-art methods.
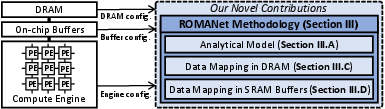
Figure 3: Typical CNN accelerator with our novel contributions in blue box.
The study quantitatively demonstrates the effectiveness of ROMANet in improving energy efficiency through detailed performance metrics:
Conclusion
ROMANet presents a well-defined approach to DRAM access management, proving significant energy and throughput improvements for DNN accelerators. The methodology fosters advancements in embedded deep learning implementations with broader implications for improving the sustainability and efficiency of AI systems. Future research can extend ROMANet's principles to other memory architectures and adapt its optimization strategies to integrated on-chip memory systems.