- The paper presents a novel framework where a chatbot continuously self-improves by deriving training data from ongoing user interactions.
- It employs multi-task learning with a Transformer architecture to manage both dialogue and feedback tasks through real-time user satisfaction estimation.
- Evaluation on the PersonaChat dataset demonstrates up to a 31% accuracy boost, underscoring its potential for cost-efficient model enhancement.
Self-Feeding Chatbot: Learning from Dialogue after Deployment
The paper "Learning from Dialogue after Deployment: Feed Yourself, Chatbot!" introduces a novel framework for enabling dialogue agents to continuously improve their responses by leveraging interactions post-deployment. This self-feeding capability is achieved through a dynamic learning process that integrates user satisfaction estimation and feedback mechanisms without incurring additional annotation costs.
Self-Feeding Chatbot Framework
Core Concept
The self-feeding chatbot framework allows a dialogue agent to derive new training data from its active conversations with users. Engagements with users provide dual opportunities for learning: inferring user satisfaction from ongoing dialogue and soliciting feedback when potential errors are detected. This model organically evolves its understanding and response quality by continuously integrating these insights into its learning process.
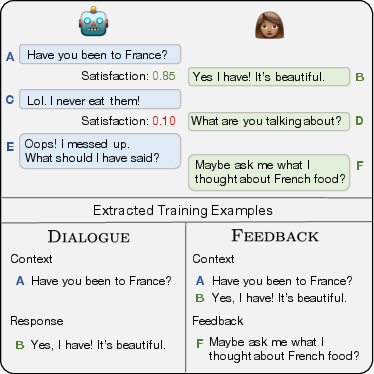
Figure 1: As the self-feeding chatbot engages in dialogue, it estimates user satisfaction to know when to ask for feedback. From the satisfied responses and feedback responses, new training examples are extracted for the Dialogue and Feedback tasks, respectively, both of which improve the model's dialogue abilities further.
Data and Methodology
Initially, the conversational agent is trained on pre-existing supervised datasets using a base model. Post-deployment, it collects new data through user interactions, divided into dialogue and feedback datasets. Two primary auxiliary tasks enhance the core Dialogue task: predicting user satisfaction and interpreting user-provided feedback. The model dynamically switches between imitation learning of user responses and corrective feedback application based on user satisfaction metrics.
Model Architecture
The architecture utilizes a Transformer-based multi-task learning model, integrating shared embeddings across tasks with distinct task-specific layers for dialogue and feedback processing. Candidate responses are ranked using shared candidate encoders, enhancing response accuracy through cross-task learning synergy.
Implementation Details
The architecture's implementation prioritizes scalability and adaptability, benefiting from the Transformer model's intrinsic parallelization capabilities. A key aspect of training involves balancing task-specific losses, ensuring that both Dialogue and Feedback tasks contribute effectively to the model's performance improvements.
Evaluation and Results
Dataset Integration
The self-feeding approach is validated using the PersonaChat dataset, consisting of diverse conversational topics across numerous dialogue turns. The method demonstrates significant performance gains across various scales of supervised data availability, with notable improvements observed in settings with limited initial training data due to effective leveraging of deployment-derived examples.
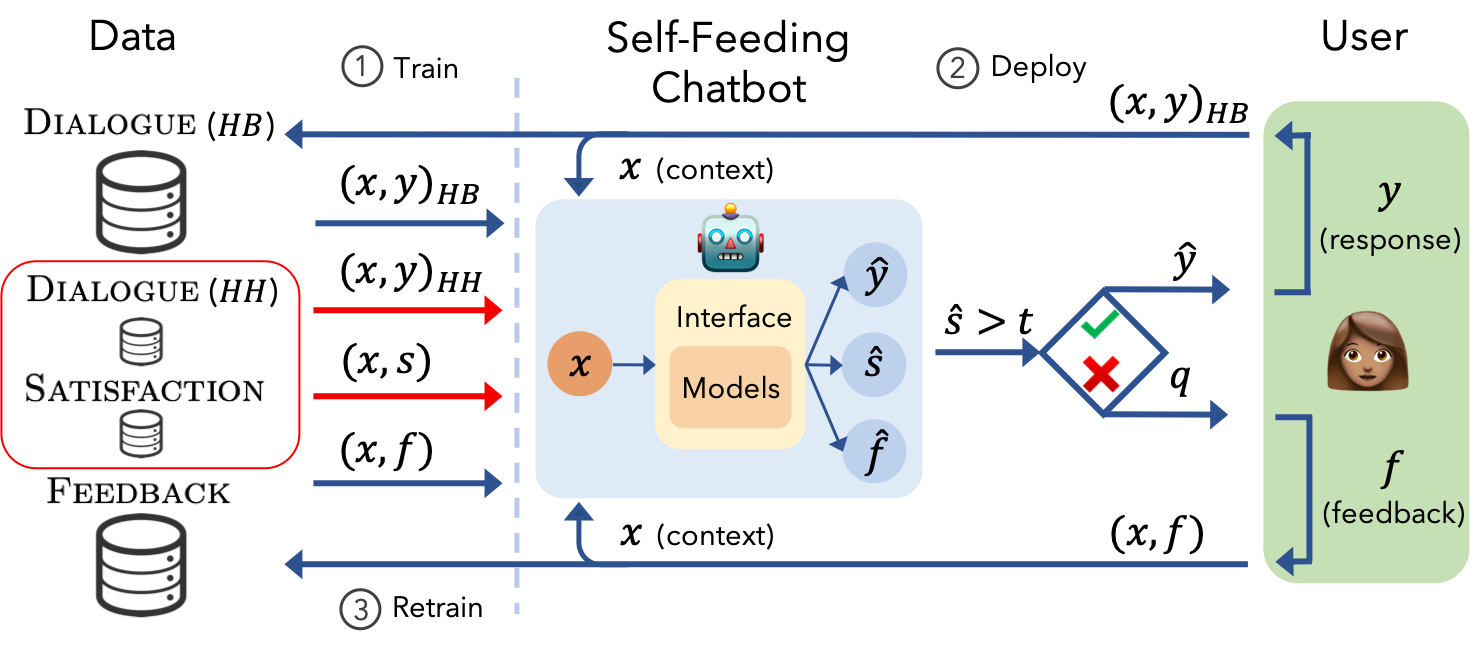
Figure 2: The chatbot is first trained with any available supervised data (boxed in red) on the Human-Human (HH) Dialogue (x,y)HH and Satisfaction (x,s) tasks. During deployment, when predicted satisfaction is high, a new Human-Bot (HB) Dialogue example is extracted. Otherwise, feedback is requested, guiding further task training.
Quantitative analysis indicates that integration of self-feeding datasets can enhance model performance by up to 31% in accuracy, significantly surpassing baselines that rely solely on pre-deployment data. Feedback examples, in particular, have shown to be highly impactful, correlating directly with improvements in handling models' past failures.
Strategic Implications
Theoretical Impact
The introduction of self-feeding chatbots exemplifies a shift towards autonomous, continuously improving dialogue systems. This approach aligns with the broader objectives of lifelong learning and active learning within AI, potentially reducing dependency on large-scale static datasets and offering a pathway to more adaptive AI systems.
Practical Applications
Deployment of such self-enhancing dialogue agents can be particularly beneficial in customer service and support settings, where dynamic adaptation to user interactions can improve both response accuracy and customer satisfaction. Moreover, the ability to actively derive training data from actual deployment environments introduces cost-saving potential by minimizing the need for traditional dataset annotation and supervision.
Conclusion
The self-feeding chatbot framework represents a significant advancement in the domain of dialogue systems, highlighting the potential for AI models to adapt and learn beyond initial training phases through strategic incorporation of user interactions. Future exploration may focus on optimizing the feedback mechanism further, enhancing the sophistication of satisfaction estimation, and broadening the application scope across varied conversational AI applications.

