- The paper presents Residual Policy Learning (RPL), which augments initial control policies with a learned residual function using deep reinforcement learning.
- RPL leverages a burn-in phase for critic training, allowing gradient updates from the residual, and enables policy gradient methods to work with nondifferentiable controllers.
- Experimental results show that RPL converges faster and outperforms both hand-designed policies and learning-from-scratch methods in challenging robotic manipulation tasks.
Residual Policy Learning
Introduction
The paper presents Residual Policy Learning (RPL), a technique designed to enhance nondifferentiable control policies using model-free deep reinforcement learning (RL). The central thesis is that RPL can significantly improve the performance of initially effective but imperfect controllers, especially in complex robotic tasks where learning from scratch is data-inefficient or infeasible.
Methodology
The methodology underlying RPL is to learn a residual function fθ(s), which adjusts the output of an existing policy π(s), effectively creating an augmented policy πθ(s)=π(s)+fθ(s). This framework allows the gradient of the policy updates during RL to be calculated directly from the residual, thereby enabling the use of policy gradient methods even with nondifferentiable initial policies.
RPL operates within a standard MDP framework and exploits various deep RL techniques, particularly those involving actor-critic architectures, such as DDPG. The introduction of a "burn-in" period ensures stability by training the critic before the actor is updated, minimizing the risk of degradation in policy performance when starting with a strong initial policy.
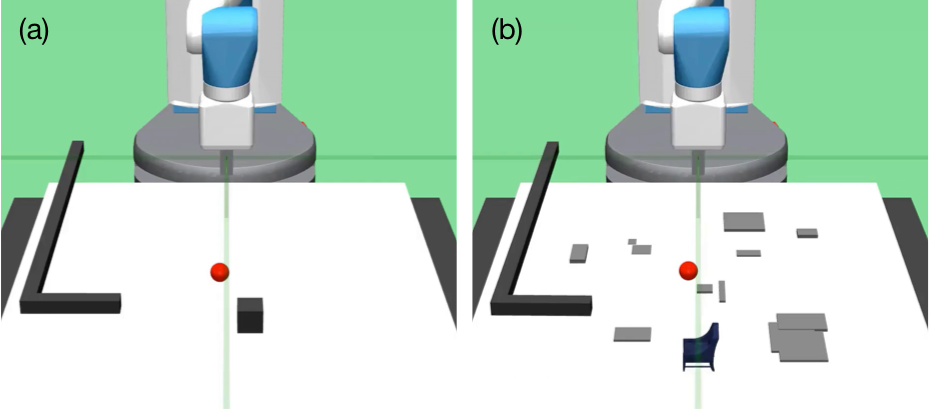
Figure 1: (a) A simulated Fetch robot must use a hook to move a block to a target (red sphere). A hand-designed policy can accomplish this task perfectly. (b) The same policy often fails in a more difficult task where the block is replaced by a complex object and the table top contains large "bumps." Residual Policy Learning (RPL) augments the policy π with a residual fθ, which can learn to accomplish the latter task.
Experimental Evaluation
Experiments were conducted on six robotic manipulation tasks using MuJoCo to assess RPL's effectiveness. Challenges addressed include partial observability, sensor noise, and controller miscalibration, exploring the spectrum from hand-designed policies to model-based controllers with learned dynamics models.
Baselines and Comparative Analysis
RPL's performance was compared to several baselines: the initial policy executed without learning, model-free RL approaches using DDPG and HER, and the "Expert Explore" baseline, which simulates exploration using the initial policy's actions.
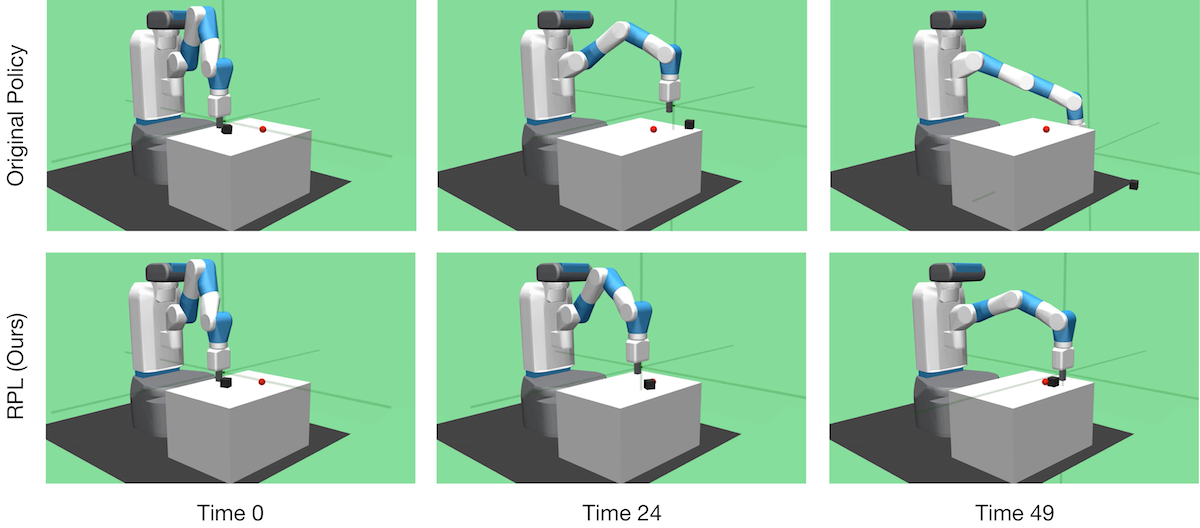
Figure 2: Illustration of the original ReactivePush policy and RPL on the SlipperyPush task. RPL learns to correct the faulty policy within 1 million simulator steps, while the RL from scratch remains ineffective.
The analysis demonstrated that RPL generally converges faster and with fewer samples than learning from scratch. Notably, in scenarios with significant changes, such as model miscalibration or sensor noise (e.g., SlipperyPush and NoisyHook tasks), RPL showed superior data efficiency and improved outcomes beyond the initial controller's capabilities.
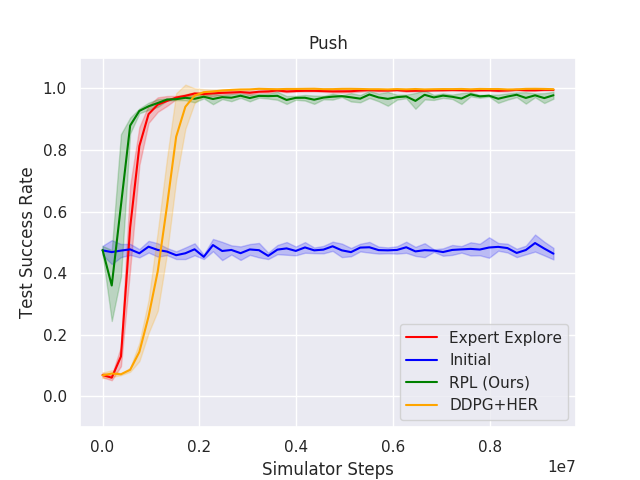
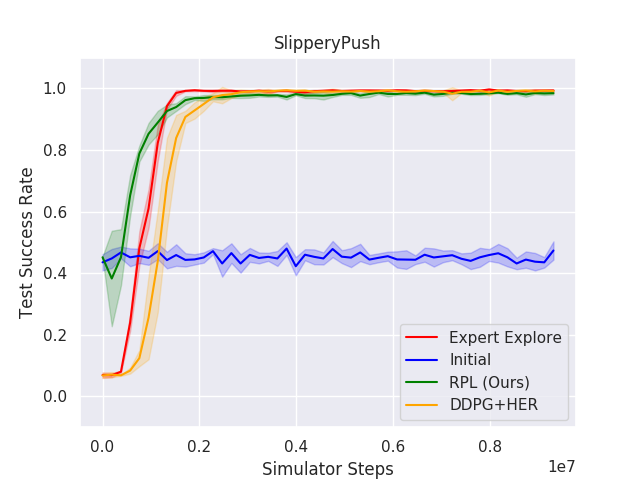
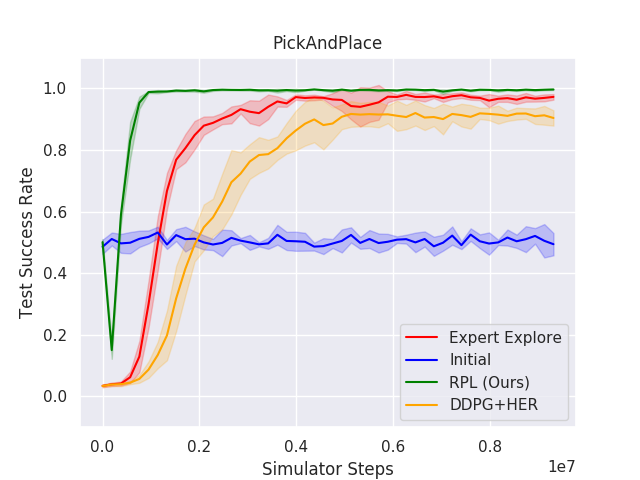
Figure 3: RPL and baseline results for the Push, SlipperyPush, and PickAndPlace tasks highlight how RPL sustains superior performance compared to initial policies and DDPG from scratch.
Implications and Future Directions
RPL is shown as a promising avenue for bridging the gap between optimal control and RL. It effectively leverages existing control policies, enhancing them with adaptive RL techniques. This balance can simplify the solving of complex, long-horizon tasks where handcrafted controller optimization is impractical.
The applicability of RPL extends beyond robotic manipulation, potentially benefiting any domain where robust but non-exacting controllers are utilized. Therefore, future research could focus on systematic exploration into other domains and refinement of RPL’s integration with varying RL architectures and model-based strategies.
Conclusion
Residual Policy Learning presents a scalable method for leveraging existing control strategies to derive enhanced robotic control policies. Through its experiment-backed evaluation, RPL underscores the benefits of combining domain-specific strategies with robust RL paradigms, offering a compelling model for addressing nuanced control challenges in AI-driven robotics. This solid foundation suggests broader applicability and room for further refinement in policy learning techniques.