- The paper leverages Bayesian neural networks and MC dropout to quantify both model (epistemic) and data (aleatoric) uncertainties in various NLP tasks.
- The study demonstrates significant performance gains, including a 26.4% improvement in sentiment analysis and a 2.7% F1 score boost in named entity recognition.
- Incorporating uncertainty quantification in language modeling reduced perplexity by 4.2%, highlighting its potential to enhance AI prediction reliability.
Quantifying Uncertainties in Natural Language Processing Tasks
The study explores applications of Bayesian deep learning to quantify uncertainties in NLP tasks, including sentiment analysis, named entity recognition (NER), and language modeling. The research demonstrates the robustness and effectiveness of incorporating model and data uncertainty, showing performance improvements across all evaluated tasks.
Introduction to Uncertainty Quantification
The paper discusses two primary types of uncertainties: model uncertainty (epistemic) and data uncertainty (aleatoric). Model uncertainties arise from the lack of knowledge about model parameters, while data uncertainties pertain to inherent noise in data. Quantifying these uncertainties could improve model predictions and aid in creating safe, reliable AI systems.
Methods for Uncertainty Quantification
The paper employs Bayesian neural networks to quantify uncertainties by using Monte Carlo (MC) dropout methods for model uncertainty and learns input-dependent data uncertainty through logit space variance in classification settings.
Model Uncertainty
Bayesian neural networks use a prior distribution over network weights, allowing prediction variance to be explored via MC dropout methods.
Data Uncertainty
Data uncertainty is quantified based on input-dependency. Regression settings use variance prediction associated with inputs, while classification employs the variance of logit distribution.
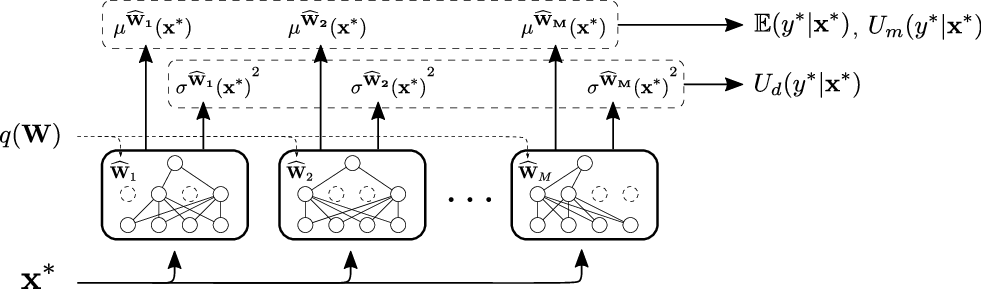
Figure 1: An illustration of the bidirectional LSTM model used for named entity recognition.
Empirical Evaluation
The study tests the utility of uncertainty quantification in three different NLP tasks using distinct datasets and models:
Sentiment Analysis
For sentiment analysis, CNN models are evaluated on Yelp and IMDB datasets. Both regression and classification formulations show significant improvements when unknowns are modeled, with up to 26.4% improved performance in regression settings.
Named Entity Recognition
Using the CoNLL 2003 dataset, experiments show that quantifying data uncertainty significantly enhances model performance, achieving a 2.7% improvement in F1 score.
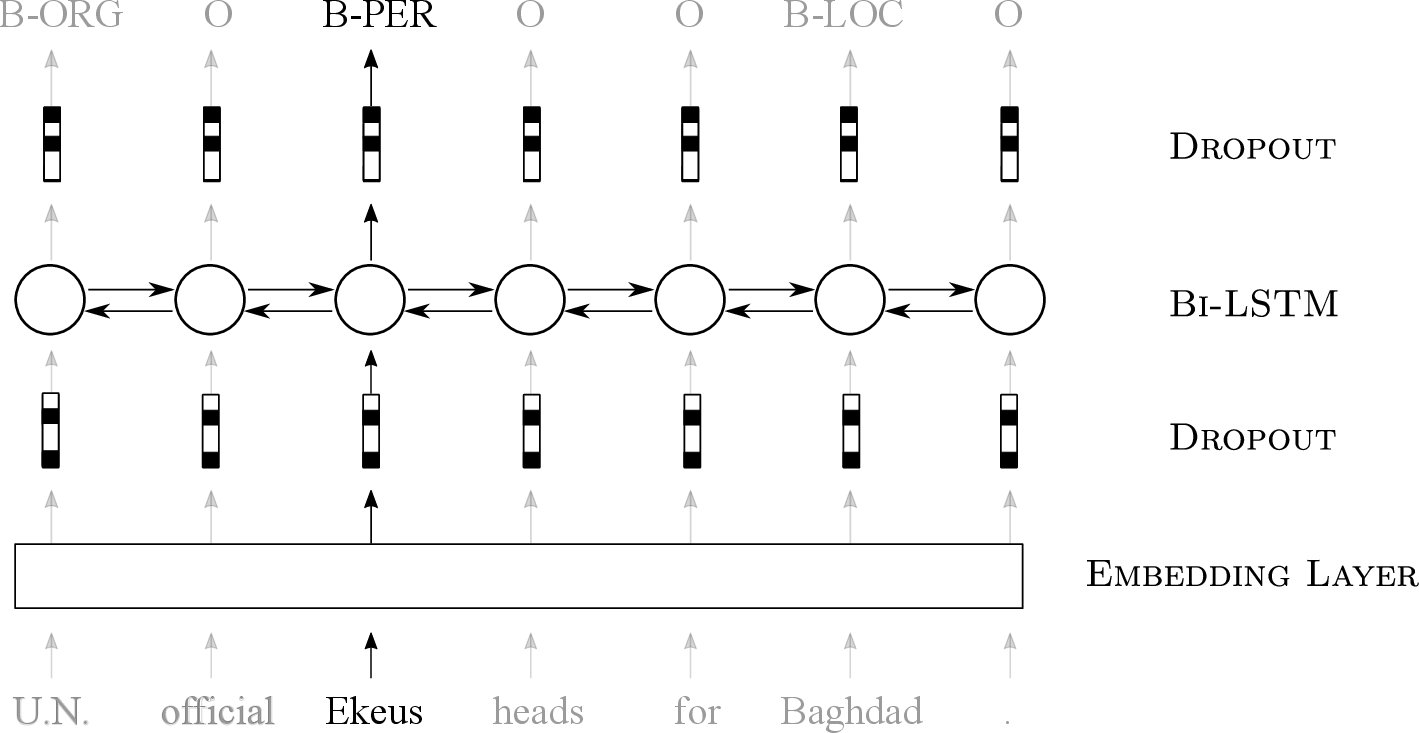
Figure 2: Scatter plot of evaluated data uncertainty against NER tag entropy, highlighting higher uncertainties for tokens with diverse tagging.
Language Modeling
The LSTM models are tested on the Penn Treebank dataset. Models incorporating both types of uncertainty outperform baselines, reducing perplexity by 4.2%.
Analysis
The study explores the characteristics of data uncertainty. It finds that data uncertainty estimates align with prediction difficulty, characterized by high entropy in potential outputs, thereby suggesting its effectiveness in real-world applications.
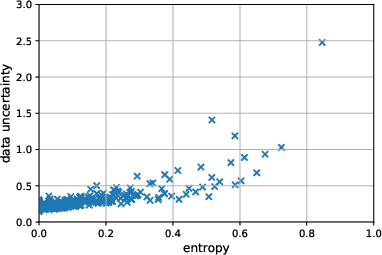
Figure 3: Scatter plot of F1 score vs. data uncertainty for NER tags, correlating higher uncertainty with challenging predictions.
Conclusion
This research establishes the benefits of integrating uncertainty quantification in NLP tasks, spotlighting enhanced model performance and prediction reliability. The findings advocate for expanding research on leveraging uncertainties in AI system developments. Future investigations might explore sophisticated methods to optimize the use of predictive uncertainty quantification.
The inclusion of visual analytics further supports comprehensions, such as the entropy distribution relation to data uncertainty and F1 score dependencies on uncertainty levels, presenting a comprehensive understanding of uncertainty quantification in AI systems.

