Semantic Modeling of Textual Relationships in Cross-Modal Retrieval
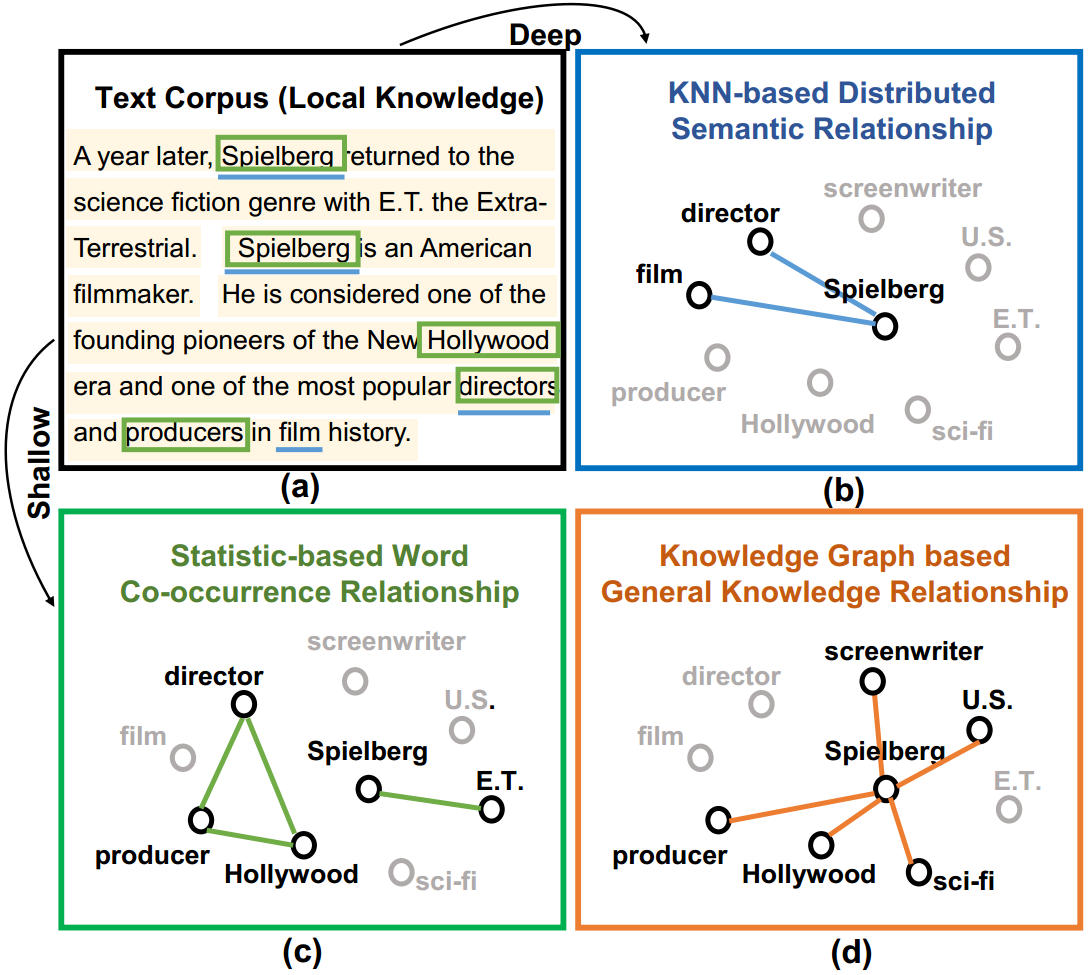
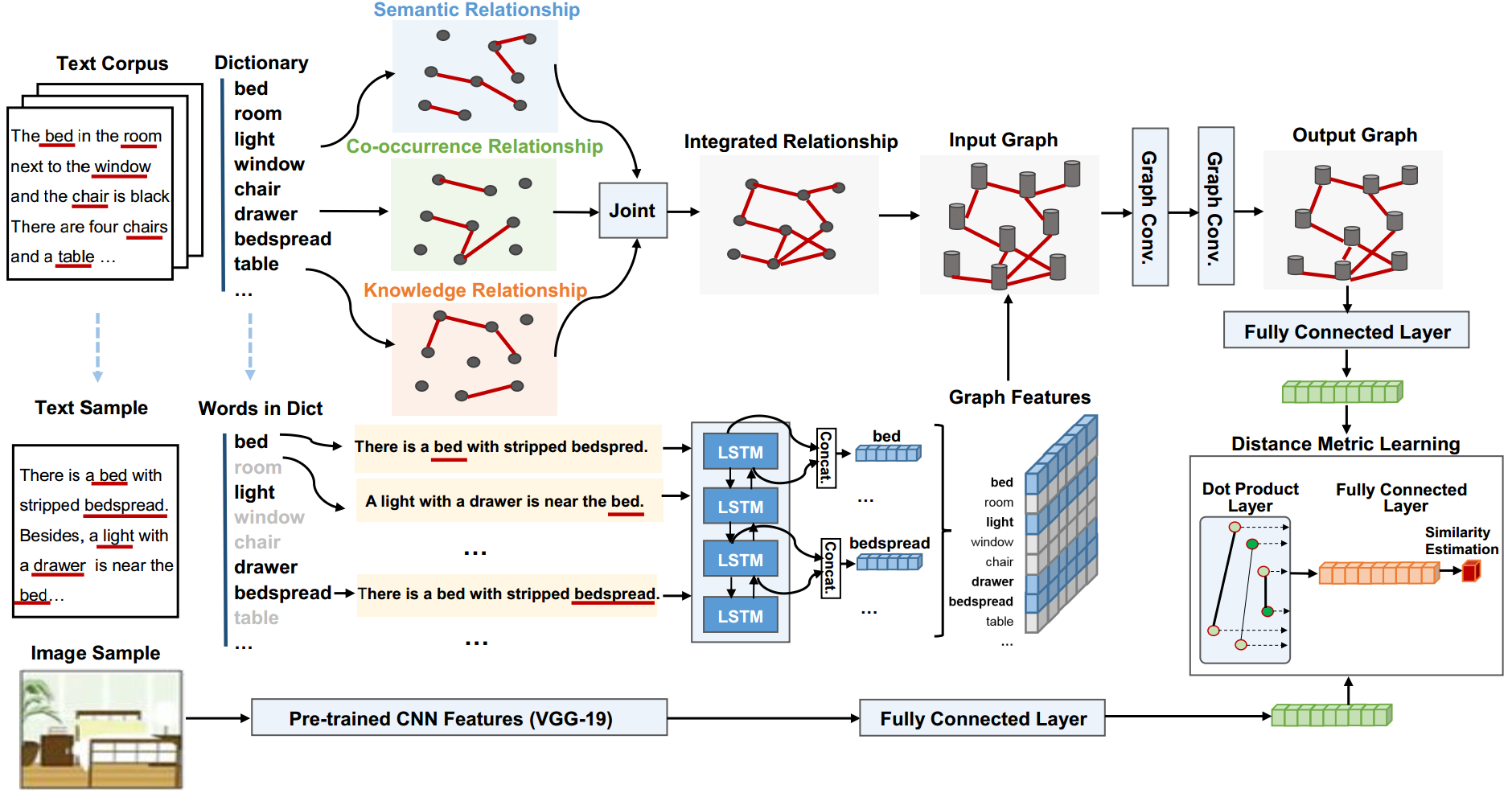
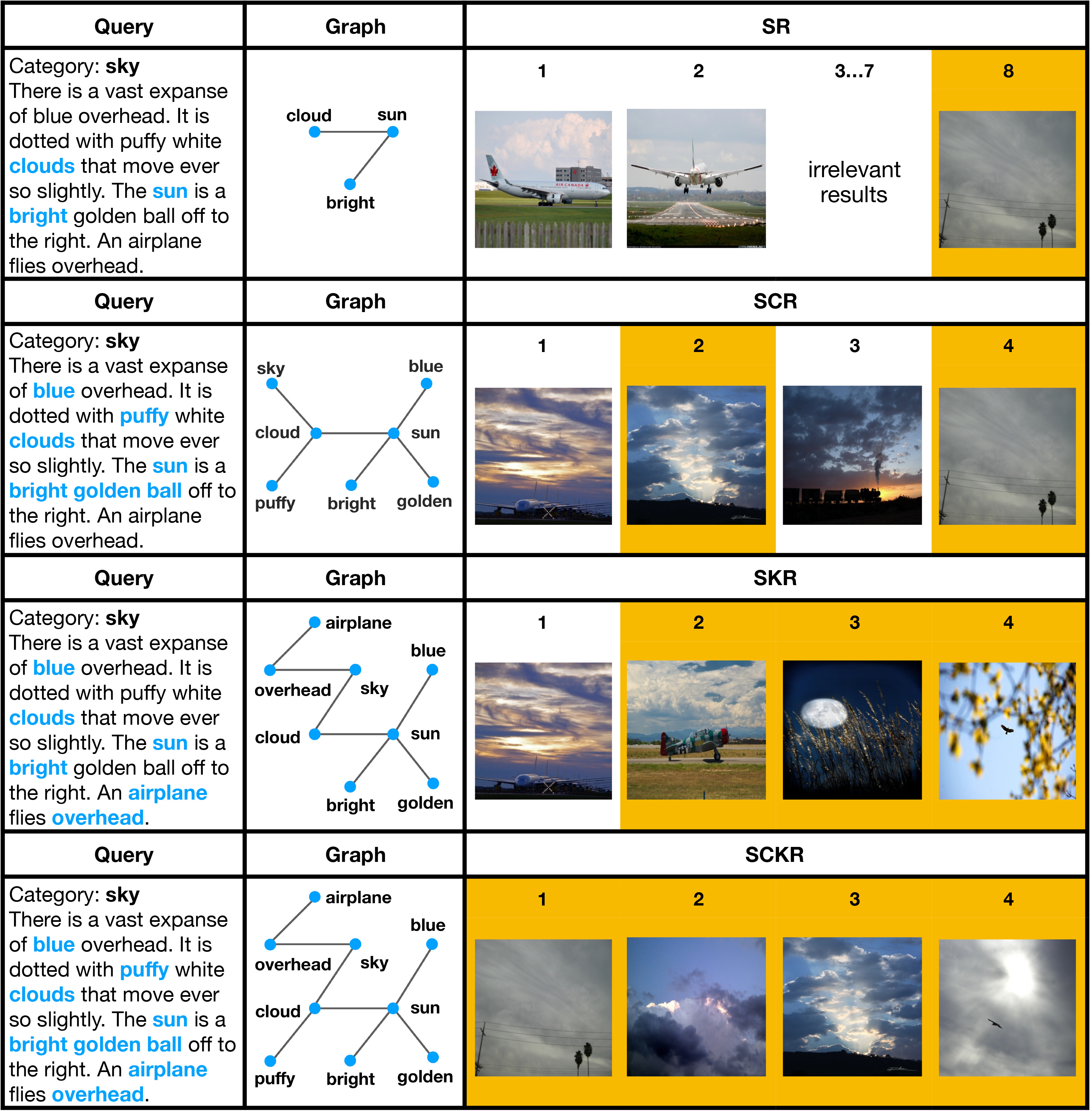
Abstract: Feature modeling of different modalities is a basic problem in current research of cross-modal information retrieval. Existing models typically project texts and images into one embedding space, in which semantically similar information will have a shorter distance. Semantic modeling of textural relationships is notoriously difficult. In this paper, we propose an approach to model texts using a featured graph by integrating multi-view textual relationships including semantic relations, statistical co-occurrence, and prior relations in the knowledge base. A dual-path neural network is adopted to learn multi-modal representations of information and cross-modal similarity measure jointly. We use a Graph Convolutional Network (GCN) for generating relation-aware text representations, and use a Convolutional Neural Network (CNN) with non-linearities for image representations. The cross-modal similarity measure is learned by distance metric learning. Experimental results show that, by leveraging the rich relational semantics in texts, our model can outperform the state-of-the-art models by 3.4% and 6.3% on accuracy on two benchmark datasets.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

