- The paper demonstrates that NeoCPU significantly reduces inference latency by up to 3.45× through systematic operation- and graph-level optimizations.
- NeoCPU employs customizable operation templates and a global search algorithm to identify optimal configurations while minimizing costly data layout transformations.
- Evaluation against baselines across 15 CNN models shows superior performance on varied CPU architectures, emphasizing its applicability in both mainstream and edge devices.
Optimizing CNN Model Inference on CPUs
Introduction
The paper "Optimizing CNN Model Inference on CPUs" addresses the performance limitations inherent in utilizing Convolutional Neural Networks (CNNs) on Central Processing Units (CPUs). CNN models are prominent in computer vision applications, and efficient inference on widespread hardware platforms like CPUs is critically important. This work introduces NeoCPU, a framework agnostic optimization approach, focusing on maximizing CNN inference efficiency on CPUs through operation- and graph-level strategies, providing significant performance improvements.
NeoCPU Overview
NeoCPU encapsulates a systematic, full-stack set of optimizations for CNN inference on CPUs. By circumventing dependency on third-party high-performance libraries such as Intel MKL-DNN, NeoCPU facilitates customizable templates for operation-level optimizations and orchestrates graph-level transformations. Experiments demonstrate up to a 3.45× reduction in latency compared to state-of-the-art CPU implementations, achievable through various architectural optimizations.
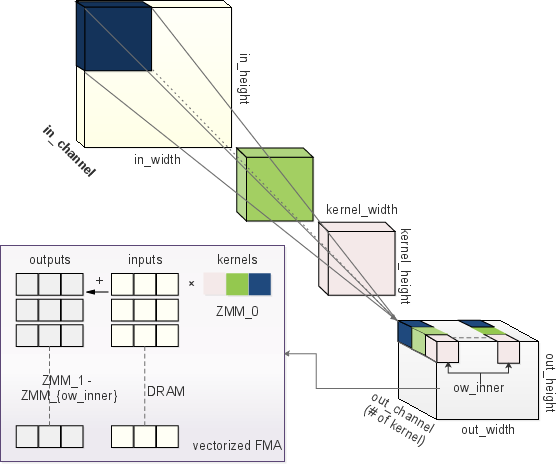
Figure 1: The illustration of CONV and the efficient implementation in AVX-512 instructions as an example.
The framework leverages advanced CPU features including SIMD and FMA, and adopts a comprehensive approach to tuning computationally intensive operations like convolutions through configurable templates adaptable to different workloads and architectures. NeoCPU's global optimization strategy reduces data layout transformations, optimizing end-to-end model efficiency.
Operation Optimization
Central to CNN computation is the convolution operation, known for its arithmetic intensity. The optimization employed in NeoCPU prioritizes enhancing data locality and maximizing vector processing unit utilization, by rearranging and blocking data dimensions effectively. This extends beyond single operation optimization, forming a template that facilitates coherent graph-level optimization without direct manipulation of assembly code.
Graph-Level Optimization
A significant part of the performance enhancement stems from the minimization of data layout transformations throughout the computation graph, deploying layout-oblivious, layout-tolerant, and layout-dependent classifications for operations. This strategy is executed by maintaining and managing data layout flow intelligently from operation to operation, minimizing costly format transformations at runtime (Figure 2).
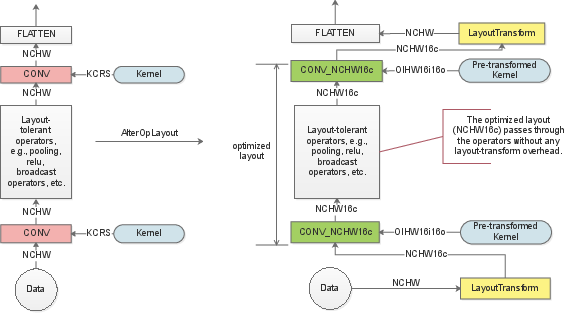
Figure 2: Layout optimization of a simple CNN model. The network on the left side shows unnecessary data layout transformations, while the optimized layout on the right reduces these overheads.
Global Optimization Scheme
NeoCPU incorporates an innovative global search for identifying optimal layout and execution parameters. By integrating both local (operation-level) and global (graph-level) searches, NeoCPU constructs a systemic approach to derive best-case configurations for complex, computationally intensive CNN models. Using dynamic programming and heuristic methods, the search navigates vast configuration spaces to enhance performance effectively (Figure 3).
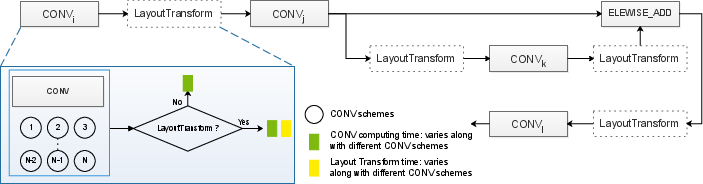
Figure 3: Global search for CNN model inference illustrating layout transformation decisions and their associated overheads.
Evaluation and Comparison
Evaluation of NeoCPU against existing baselines including MXNet, TensorFlow (with ngraph), and OpenVINO shows pervasive advantages. The performance metrics indicate a superior rate of inference on a variety of CPU architectures, validated across 15 popular CNN models. NeoCPU achieves optimal latency with advantages noted particularly on ARM platforms, where baselines like OpenVINO lack applicability owing to their dependency on x86 centered optimizations.
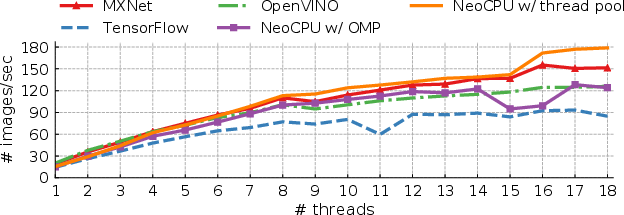
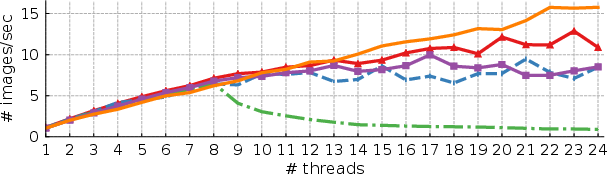
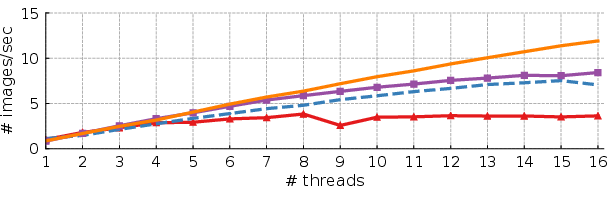
Figure 4: ResNet-50 on a system with 18-core Intel Skylake CPU.
The competitive edge NeoCPU holds is significantly attributed to its comprehensive, modular optimization framework that dynamically adapts to CPU architectural specifics, yielding enhancements across multiple CPF (cycles per frame) configurations.
Conclusion
NeoCPU outlines a robust framework capable of delivering insightful improvements for CNN model inference on CPUs. It exhibits potential expansibility to include more diverse operations and leverage quantized computation methodologies, presenting a valuable asset for scaling performance on mainstream and edge computing platforms. Future development may focus on expanding the support to additional hardware types and exploring techniques specialized for dynamic model structures.

