- The paper presents DVSO, which integrates deep depth prediction into Direct Sparse Odometry to significantly reduce scale drift in monocular visual odometry.
- It employs a novel StackNet architecture with SimpleNet and ResidualNet to refine disparity predictions for improved depth accuracy.
- Experimental results on the KITTI dataset show that DVSO achieves stereo-level accuracy while outperforming traditional monocular methods.
Deep Virtual Stereo Odometry: Leveraging Deep Depth Prediction for Monocular Direct Sparse Odometry
The paper "Deep Virtual Stereo Odometry: Leveraging Deep Depth Prediction for Monocular Direct Sparse Odometry" (DVSO) explores advanced techniques for monocular visual odometry in environments such as autonomous navigation and augmented reality. The authors incorporate deep learning-based monocular depth prediction into traditional geometric approaches, addressing issues such as scale drift and motion parallax.
Introduction
Traditional monocular visual odometry (VO) methods suffer from inherent scale drift due to their reliance on geometric cues. While stereo methods can resolve these limitations, they require calibration and additional equipment, making them less desirable for some applications. DVSO proposes a solution that leverages deep monocular depth prediction, employing a neural network to provide depth estimates and virtual stereo measurements for initialization in Direct Sparse Odometry (DSO).

Figure 1: DVSO achieves monocular visual odometry on KITTI on par with state-of-the-art stereo methods. It uses deep-learning based left-right disparity predictions (lower left) for initialization and virtual stereo constraints in an optimization-based direct visual odometry pipeline. This allows for recovering accurate metric estimates.
Network Architecture and Training
The novel network architecture, StackNet, refines depth predictions in two stages using fully convolutional encoder-decoder subnetworks: SimpleNet and ResidualNet.
- SimpleNet: Utilizes a ResNet-50 based encoder and skip connections for high-resolution disparity map predictions.
- ResidualNet: Refines disparity estimates from SimpleNet using an additive residual signal.
The training process is semi-supervised, leveraging photometric consistency and sparse depth information from Stereo DSO for enhanced depth prediction accuracy.
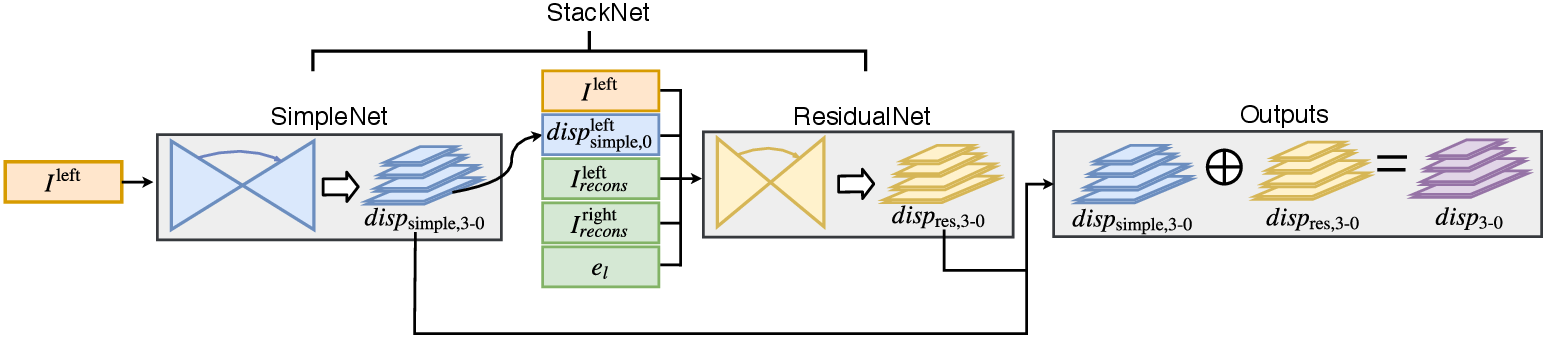
Figure 2: Overview of StackNet architecture.
Deep Virtual Stereo Odometry Implementation
DVSO integrates deep monocular depth predictions into the monocular DSO pipeline, initializing depth maps and formulating virtual stereo image alignment constraints. This optimization includes a novel virtual stereo term that enhances bundle adjustment accuracy by aligning estimated depth with predicted disparities.

Figure 3: System overview of DVSO. Every new frame is used for visual odometry and fed into the proposed StackNet to predict left and right disparity. The predicted left and right disparities are used for depth initialization, while the right disparity is used to form the virtual stereo term in direct sparse bundle adjustment.
Experimental Results
DVSO was tested extensively on the KITTI dataset. The implementation showed significant improvements over traditional monocular methods, achieving results comparable to stereo VO systems. Post-tuning, DVSO also demonstrated superior results against deep learning end-to-end VO systems, affirming its practical utility in monocular setups.
- Monocular VO: DVSO reduces scale drift significantly, outperforming state-of-the-art methods on benchmarks.
- Monocular Depth Prediction: StackNet yields improved depth estimation compared to both supervised and self-supervised state-of-the-art methods.

Figure 4: Qualitative comparison with state-of-the-art methods. The ground truth is interpolated for better visualization. Our approach shows better prediction on thin structures than the self-supervised approach~\cite{godard2016unsupervised}.
Conclusion
DVSO enhances monocular visual odometry by integrating deep depth predictions into a geometric framework, effectively tackling scale drift and improving accuracy. This approach delivers significant advancements in the reliability and efficacy of monocular camera systems for real-world applications. Future directions may include further network fine-tuning within the odometry pipeline to adapt to various environments and camera setups. The method's applicability across different domains underscores its potential as a robust solution for monocular navigation and mapping tasks.


Figure 5: Qualitative results on Eigen et al.'s KITTI Raw test split. The result of Godard et al.~\cite{godard2016unsupervised} highlights superior prediction quality compared to other methods.