- The paper introduces a dual-path model that utilizes GCN-based text modeling to capture complex word relationships.
- It constructs text graphs using k-nearest neighbor word2vec similarities and aligns modalities via a pairwise similarity loss.
- Experiments demonstrate up to 35% improvement in text-image retrieval, outperforming traditional CNN-based models.
Modeling Text with Graph Convolutional Network for Cross-Modal Information Retrieval
This essay explores the paper "Modeling Text with Graph Convolutional Network for Cross-Modal Information Retrieval" (1802.00985). The research focuses on improving the performance of cross-modal information retrieval by introducing a novel model that leverages Graph Convolutional Networks (GCNs) to handle textual data while using traditional neural networks for image data.
Cross-modal information retrieval refers to the task of retrieving data of different modalities through queries presented in a single modality—images and texts in this scenario. The primary challenge in this domain is learning a representation that allows different modalities to be compared in a common semantic space. Traditional approaches typically rely on Convolutional Neural Networks (CNNs) for image feature extraction while utilizing word-level features, such as word2vec or bag-of-words, for text.
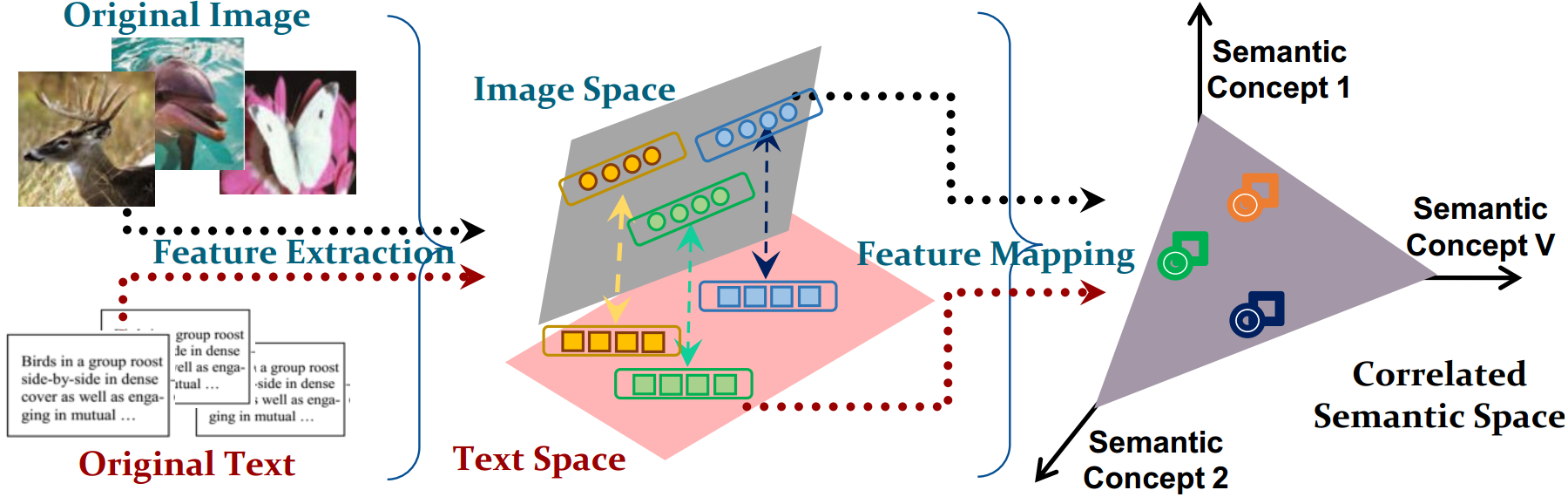
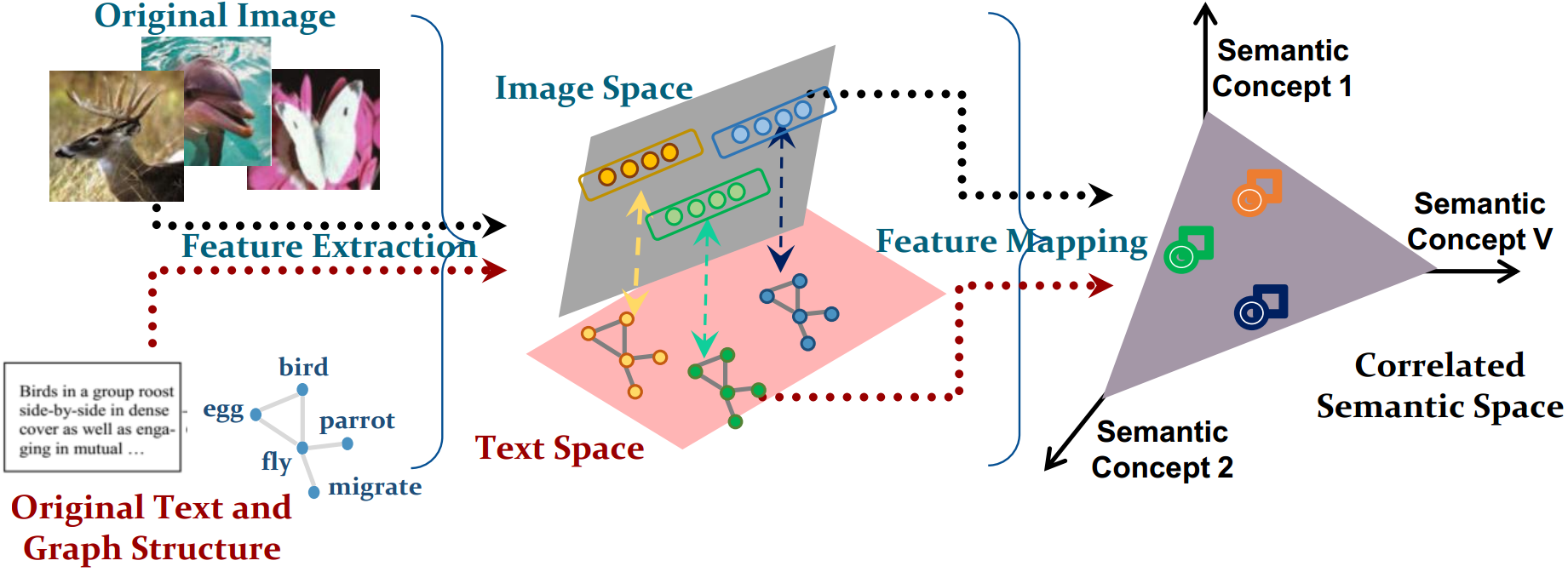
Figure 1: Comparison of classical cross-modal retrieval models to our model. (a) Classical models adopt feature vectors to represent grid-structured multimodal data; (b) Our model can handle both irregular graph-structured data and regular grid-structured data simultaneously.
Methodology
The proposed model is designed as a dual-path neural network aimed at learning representations from both textual and visual data to achieve cross-modal retrieval.
Text Modeling with GCN
In traditional models, word semantics in texts were modeled through vector space methods like word2vec, which lack consideration for word relationships. This paper adopts a graph-based representation of text, where the structure and semantics are incorporated through a graph explicitly constructed using a k-nearest neighbor approach based on word2vec cosine similarities.
The use of GCNs allows for the extraction of meaningful representations from these graphs by performing operations similar to convolutions in the spectral domain. Specifically, the text GCN applies two layers of graph convolution followed by non-linear activations, ultimately mapping text graph features into a shared semantic space with image features.
Image Representation with Neural Networks
For image data, the pipeline employs a conventional neural network initialized with pre-trained off-the-shelf features. These are fine-tuned through fully connected layers mirroring the dimensions of the text representation, ensuring that both modalities are comparable in the final semantic space.
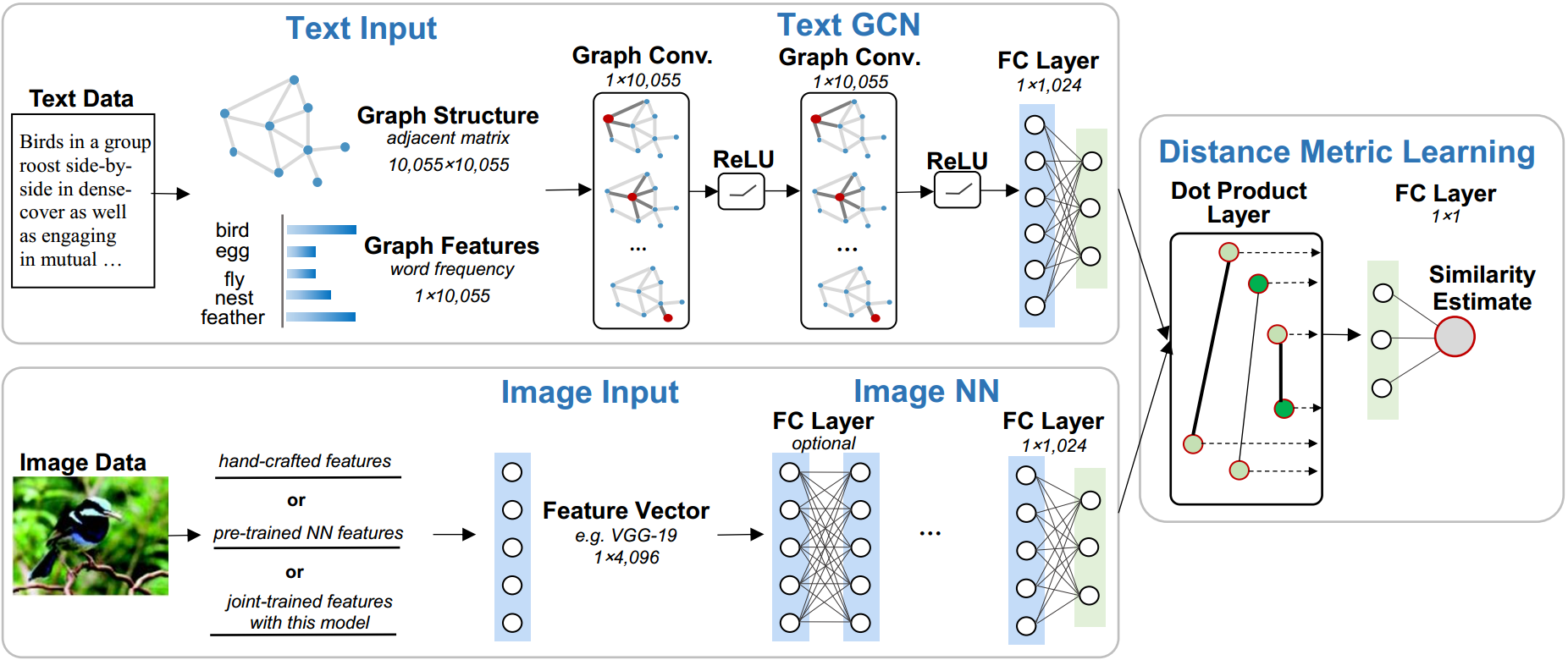
Figure 2: The structure of the proposed model is a dual-path neural network: i.e., text Graph Convolutional Network (text GCN) (top) and image Neural Network (image NN) (bottom).
Objective Function and Training
The model aims to maximize similarity between matching text-image pairs and minimize it for non-matching pairs using a pairwise similarity loss function, which balances the mean similarity score and its variance for both matching and non-matching pairs. This approach contributes to learning robust representations that generalize well across different datasets.
Experimental Results
The model was evaluated on five datasets, including English Wikipedia and NUS-WIDE. It substantially outperformed existing models across tasks, particularly in text-query-image retrieval tasks, demonstrating up to 35% improvement over the second-best models.
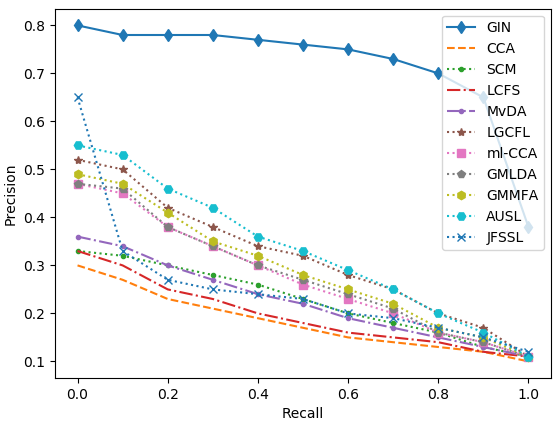
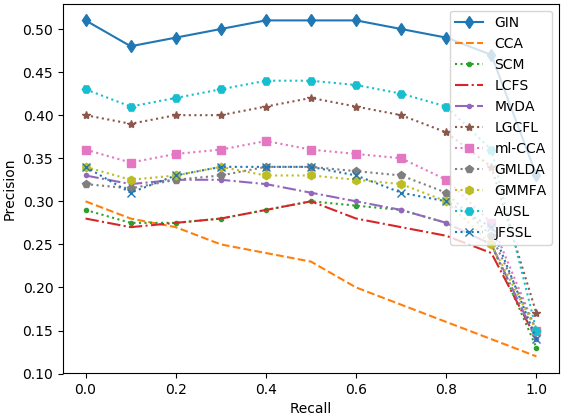
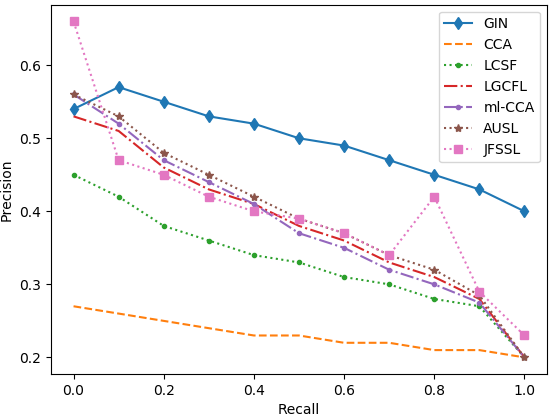
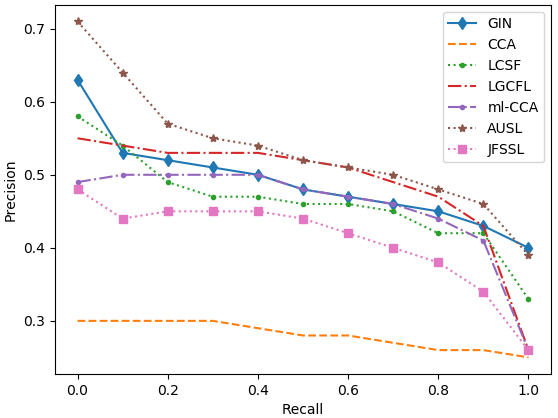
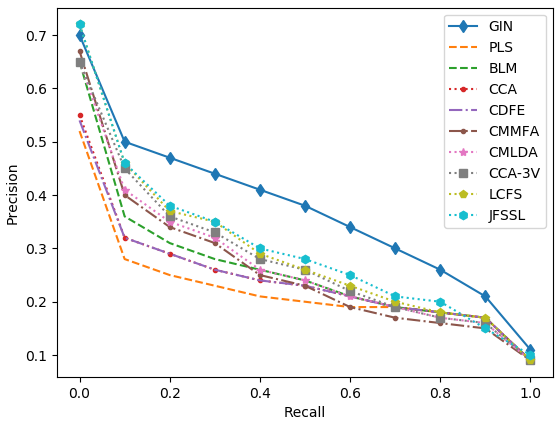
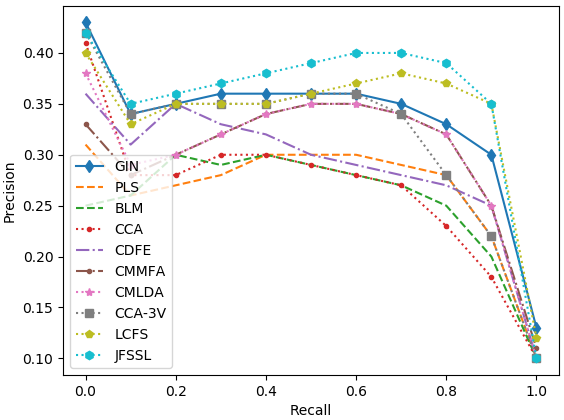
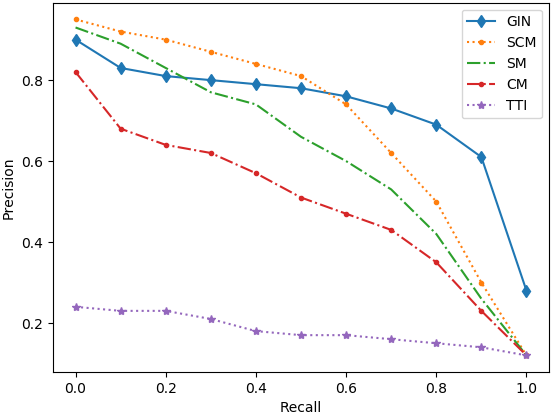
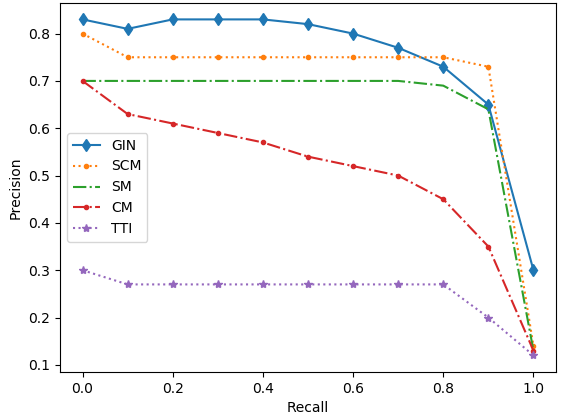
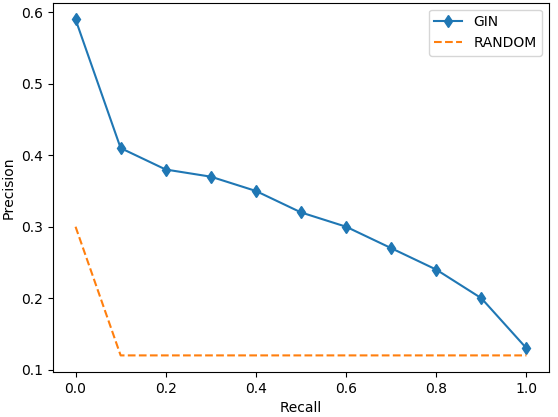
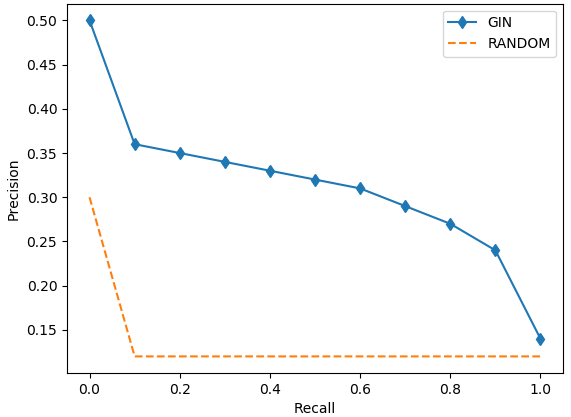
Figure 3: Precision-recall curves on the five datasets.
Practical and Theoretical Implications
This research establishes a new route for cross-modal retrieval by integrating graph structures into text modeling, which was traditionally vector-based. The advancement provides a robust framework for handling irregular graph-structured data like text, expanding its application in non-Euclidean data domains. Future developments could explore end-to-end training for feature extraction components to further enhance retrieval tasks.
Conclusion
By modeling text with graphs and leveraging GCNs, the proposed dual-path approach facilitates more effective cross-modal retrieval than traditional methodologies. The model's ability to handle complex data structures directly impacts applications in semantic understanding and information retrieval across diverse, multimodal datasets.

