- The paper introduces a novel weighted distance measure that integrates vertex and edge attributes using a weighted Euclidean norm.
- It presents the MAGDist and MAGSim algorithms, which improve clustering accuracy compared to traditional methods on datasets like Iris and Twitter.
- Experimental results show reduced misclassification and enhanced cluster cohesion, indicating potential applications in social media and citation networks.
A Novel Weighted Distance Measure for Multi-Attributed Graphs
Introduction
The paper introduces a novel weighted distance measure designed for multi-attributed graphs where both vertices and edges are represented as multi-dimensional vectors. This metric, based on the weighted Euclidean norm, facilitates graph analysis tasks such as classification and clustering by incorporating both vertex and edge attributes. The proposed framework includes the MAGDist algorithm for calculating distances and the MAGSim algorithm for generating similarity graphs, ultimately improving clustering outcomes over traditional methods.
Methodology
Weighted Distance Measure
The distance measure leverages the weighted Euclidean norm to compute distances between vertices in a multi-attributed graph. This is achieved by accounting for both vertex and edge attributes, enabling a nuanced understanding of the graph's structure. The proposed method utilizes a scalar λ, derived from the aggregate weight of edges between vertex pairs, allowing the model to modulate the influence of edge attributes.
The formulation is as follows:
- Distance Input: For vertices u and v, and edge attributes e1,e2,…,em.
- Aggregate Weight: Calculated by equation (12), where weights αi contribute to the edge influence.
- Distance Calculation: The distance Δ(u,v) is computed using equation (10), adjusting vertex separation by edge weights.
Algorithms
- MAGDist: Calculates the pairwise distances within the graph:
1
2
3
|
def MAGDist(vertex_data, edge_data, alpha, gamma):
# Calculate distances considering vertex and edge weights
# Returns a CSV file with distances between vertex pairs |
- MAGSim: Utilizes the distances from MAGDist to create a similarity graph:
1
2
3
|
def MAGSim(distance_data):
# Convert distances to similarity scores
# Returns a CSV file representing the similarity graph |
Experimental Evaluation
The proposed methodology was evaluated on several datasets:
- Iris Dataset: Modeled as a multi-attributed graph (Figures 4 and 5).
- Twitter Dataset: Tweaked for heterogeneous data analysis with real social media data (Figures 8 and 9).
The results denote that MAGSim-generated similarity graphs facilitate superior clustering accuracy when compared to traditional methods like Gaussian kernel or k-nn.
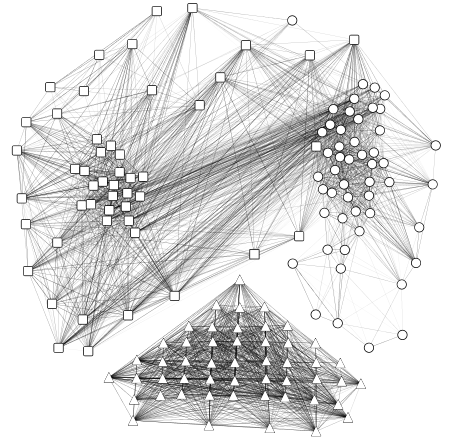
Figure 1: G1: Iris data graph modeled as a multi-attributed graph with Gaussian similarity.
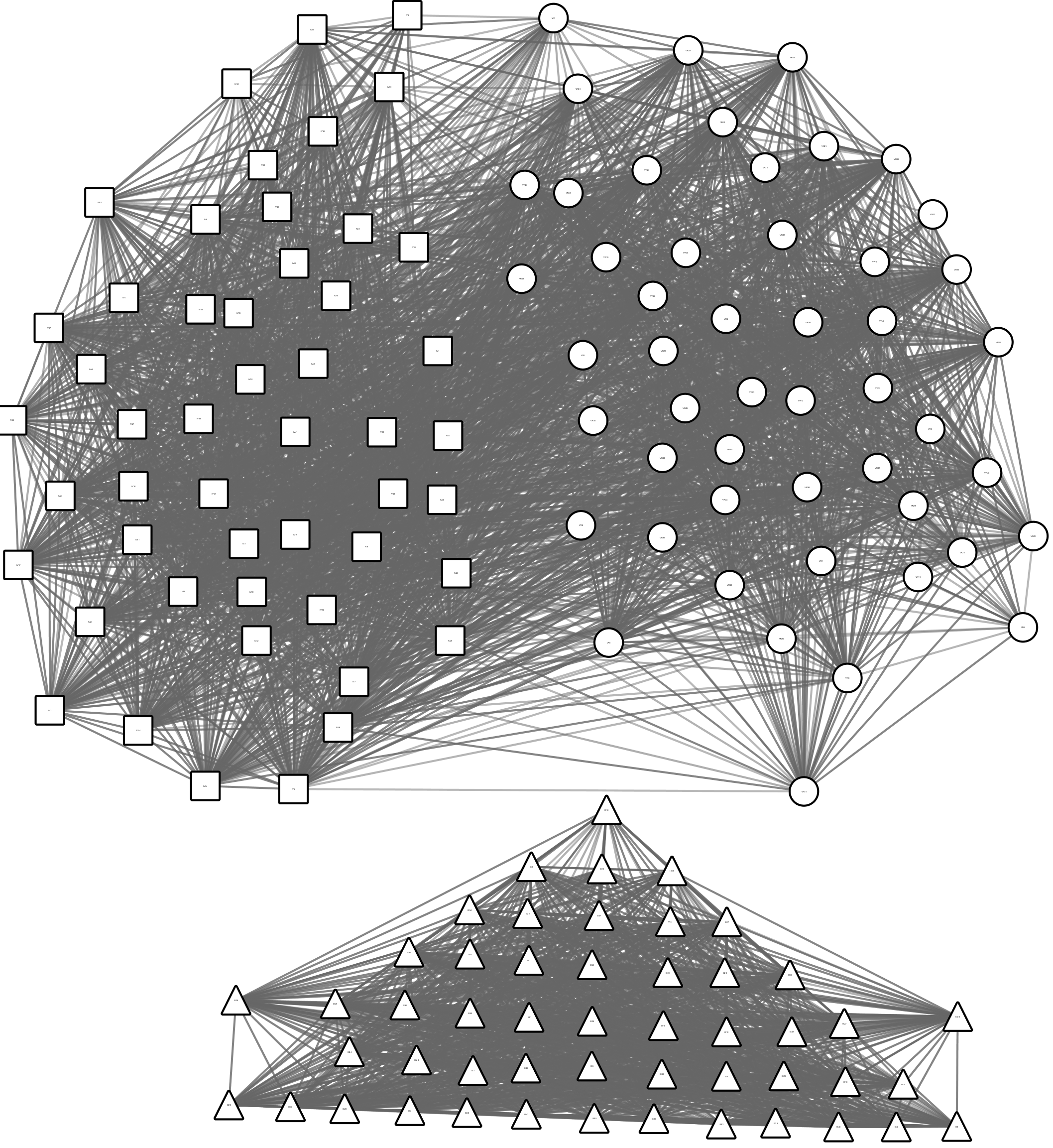
Figure 2: G2: Iris data graph with MAGSim similarity calculated using equation (14).
Clustering Results
Applying the Markov Clustering (MCL) algorithm on similarity graphs derived from MAGDist revealed improved classification accuracy for different data categories. The Iris data clustering (Figures 6 and 7) demonstrated reduced misclassification rates and enhanced cluster cohesion.
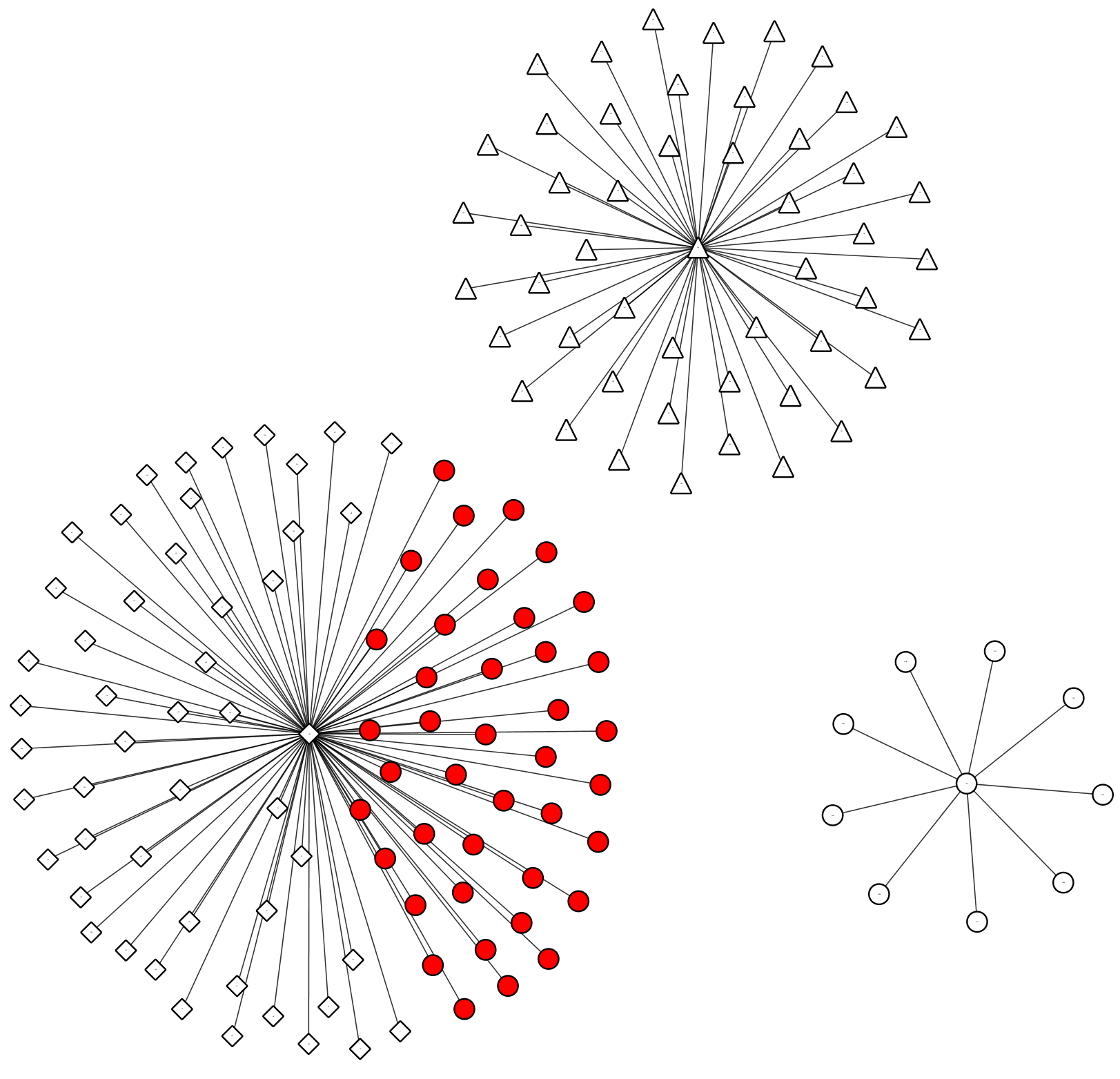
Figure 3: Clustering results after applying MCL over the Iris data graph G1.
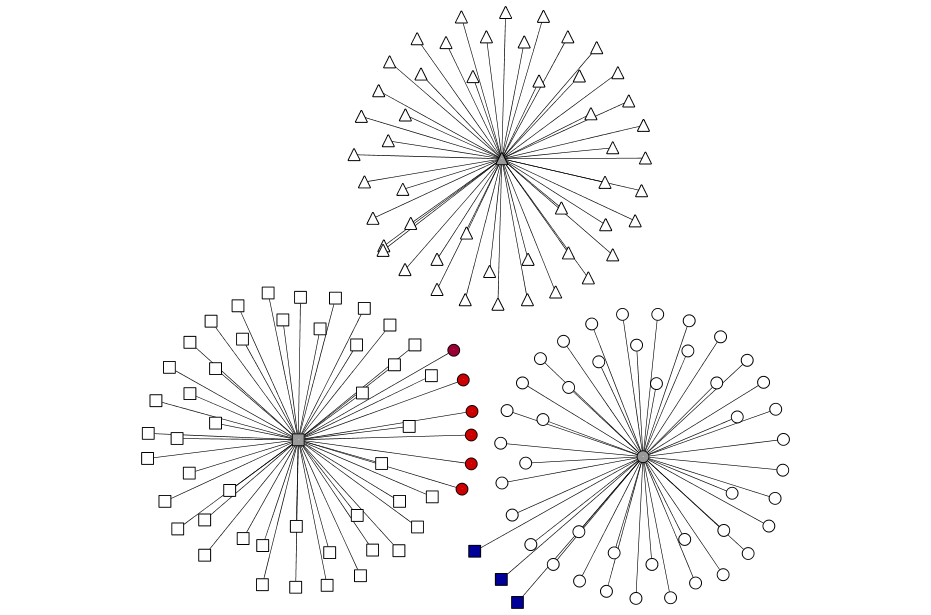
Figure 4: Clustering results after applying MCL over the Iris data graph G2.
Conclusion
The paper presents a significant enhancement in handling multi-attributed graphs by developing a measure that efficiently incorporates both vertex and edge attributes. The MAGDist and MAGSim algorithms successfully transform complex, multi-dimensional data into simplified representations, enabling proficient clustering and classification. Future directions include scaling the approach for large graph datasets and applying it to domains like citation networks and social media analysis, which demand multi-faceted graph interpretations.