- The paper introduces a one-shot visual imitation technique that leverages meta-learning to enable rapid task adaptation from minimal data.
- It employs a two-phase gradient update process that fine-tunes policy parameters using both simulated and real-world demonstration tasks.
- Experimental evaluations in reaching, pushing, and placing scenarios demonstrate improved data efficiency and performance over prior methods.
Introduction
The paper "One-Shot Visual Imitation Learning via Meta-Learning" (1709.04905) presents a method that enables robots to learn new tasks from a single visual demonstration, leveraging meta-learning combined with imitation learning. The challenge addressed in this research is the inefficiency of learning complex skills from scratch in unstructured environments using high-capacity models like deep neural networks. To tackle this, the paper introduces a scalable method for one-shot imitation learning from raw pixel inputs, reducing the need for extensive task-specific data.
The method combines meta-learning with imitation learning, allowing a robot to reuse past experiences to acquire new skills from only one demonstration. Unlike previous methods that depend on extensive task identity or demonstration inputs, this approach utilizes a parameterized policy adaptable to various tasks through gradient updates. The policy is trained across multiple tasks, using only minimal data for each, which significantly enhances data efficiency and reduces supervisory needs.
The paper extends model-agnostic meta-learning (MAML) to the imitation learning context. MAML optimizes the model parameters such that they can adapt rapidly to new tasks. During meta-training, the method involves sampling tasks that represent entire episodes as data points, optimizing the policy parameters based on the demonstration data and testing task performance after adaptation using gradient updates.
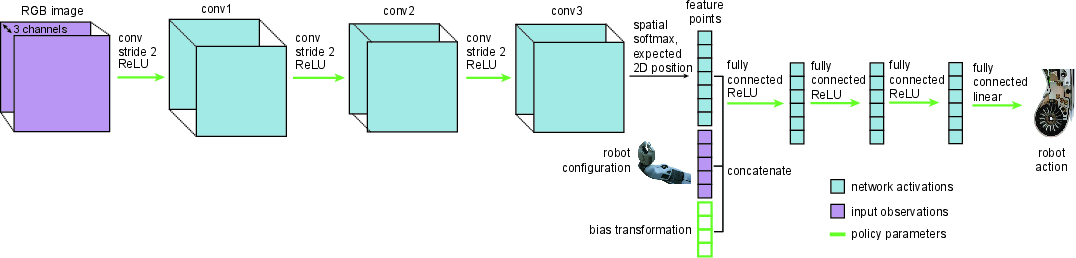
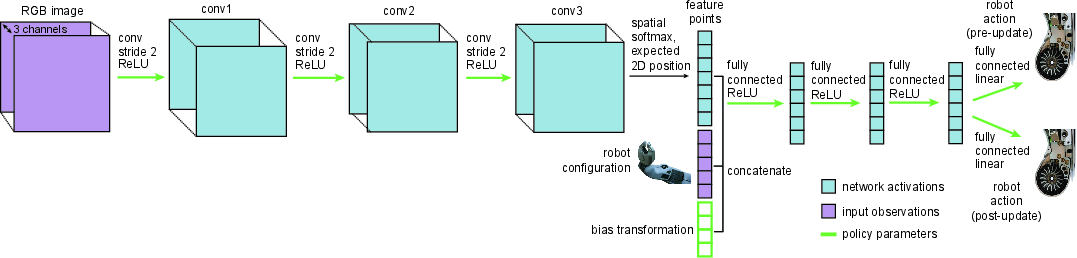
Figure 1: Diagrams of the policy architecture with a bias transformation (top and bottom) and two heads (bottom). The green arrows and boxes indicate weights that are part of the meta-learned policy parameters θ.
Algorithmic Implementation
The algorithm leverages MAML by structuring meta-training around two phases: adaptation and evaluation. The adaptation phase involves updating model parameters using gradient descent applied to the sampled demonstration from a task. The evaluation phase assesses the adapted model on a new demonstration, using this assessment to further refine model parameters through meta-optimization.
During meta-training, the key process involves handling demonstrated tasks, sampling from the distribution of tasks p(T), and executing inner gradient steps that finetune the model for each specific task, applying a meta-gradient update that collectively refines model parameters for fast adaptation. The method employs a parameter-efficient architecture, combining standard neural network components with novel elements like two-head architecture and bias transformation, enhancing adaptation capabilities.



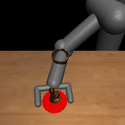


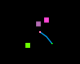




Figure 2: Example tasks from the policy's perspective. In the top row, each pair of images shows the start and final scenes of the demonstration. The bottom row shows the corresponding scenes of the learned policy roll-out.
Experimental Evaluation
The experimental setup explored the efficacy of the proposed method in simulated reaching and pushing domains, as well as real-world placing tasks. Meta-learning across diverse tasks enables rapid adaptation with notable success rates upon encountering novel settings:
- Simulated Reaching: Policies were evaluated on reaching tasks where each task involved different color targets. The results indicated superior performance over other one-shot imitation methods, particularly when utilizing vision-based input.
- Simulated Pushing: The method demonstrated success in learning diverse pushing tasks from visual inputs, showcasing efficacy in complex 3D environments with 7-DoF torque control.
- Real-World Placing: Utilizing a PR2 robot, the method successfully grasped and placed objects into containers from a single demonstration, even when novel objects were introduced.




Figure 3: Training and test objects used in our simulated pushing (left) and real-world placing (right) experiments.
Conclusion
The paper successfully introduces a method for one-shot visual imitation learning that is efficient and practical for real-world applications. By integrating gradient-based meta-learning with imitation learning, the approach dramatically enhances the capability of robots to learn from minimal demonstrations, leveraging extensive prior task experience. Looking ahead, the scalability of this method suggests promising avenues for robotic learning, especially in utilizing vast datasets for meta-training to further bolster skill acquisition efficiency.