- The paper introduces a novel back-gradient optimization technique for efficiently generating adversarial poisoning attacks on deep learning models.
- It extends the threat model to multiclass systems by distinguishing between error-generic and error-specific attacks, enhancing our understanding of data poisoning vulnerabilities.
- Experiments on tasks like spam detection and MNIST show that even a small set of adversarial examples can significantly degrade model performance and transfer across different algorithms.
"Towards Poisoning of Deep Learning Algorithms with Back-gradient Optimization"
Introduction
The paper "Towards Poisoning of Deep Learning Algorithms with Back-gradient Optimization" addresses the evolving threat of data poisoning in machine learning systems. By exploiting vulnerabilities inherent in the training data, adversaries can subvert learning processes. The research extends existing frameworks to consider multiclass systems and neural networks and introduces a novel algorithm based on back-gradient optimization for generating adversarial training examples.
Extending the Threat Model
The researchers expand the definition of data poisoning to include multiclass classification, which poses a greater challenge due to the increased complexity of potential misclassifications. They elaborate on the distinctions between error-generic and error-specific attacks, which respectively relate to increasing the general misclassification rate and targeting specific misclassification outcomes.
Back-gradient Optimization Technique
The paper proposes using back-gradient optimization to efficiently compute adversarial perturbations. Traditional methods rely on bilevel optimization, involving the solution of KKT conditions of the learning problem, which is computationally intensive. The newly suggested approach computes gradients using reverse-mode automatic differentiation, facilitating the generation of poisoning attacks that affect broader classes of algorithms, including those leveraging deep neural network architectures.
Experimental Evaluation
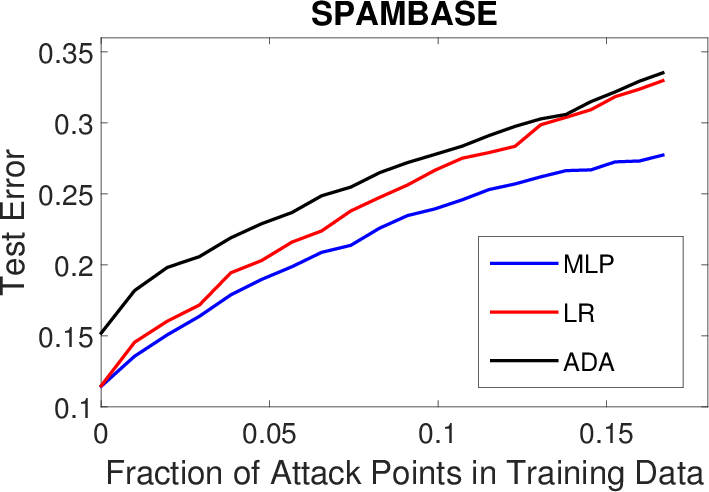
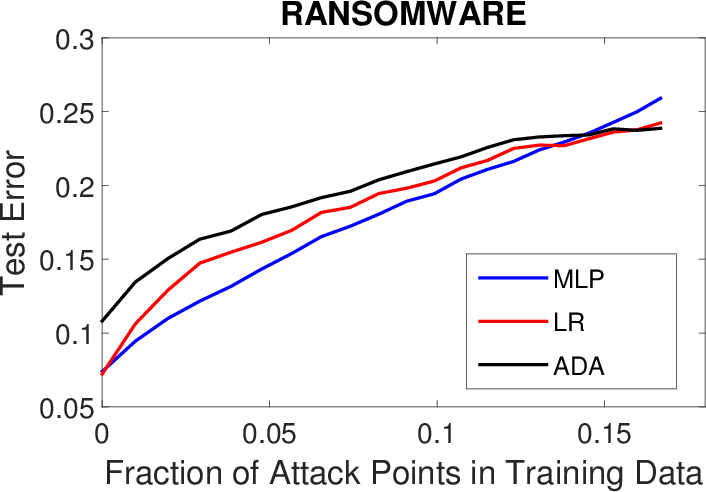
Figure 1: Results for PK poisoning attacks.
The effectiveness of the attack methodology was empirically validated through experiments involving spam, malware detection, and handwritten digit classification. It was demonstrated that neural networks, when poisoned accurately using back-gradient optimization, could substantially degrade in performance with a relatively small set of adversarial examples. Moreover, evidence of transferability in such attacks was provided, corroborating that adversarial samples created for one learning algorithm could impact others, underscoring the cross-model robustness of the attack.
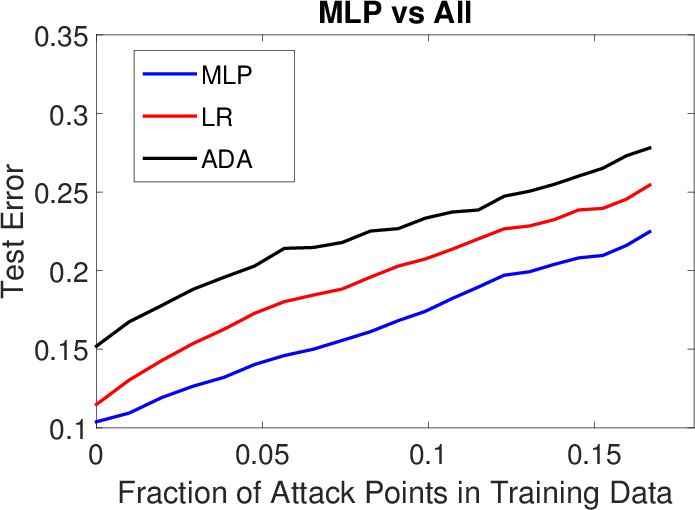
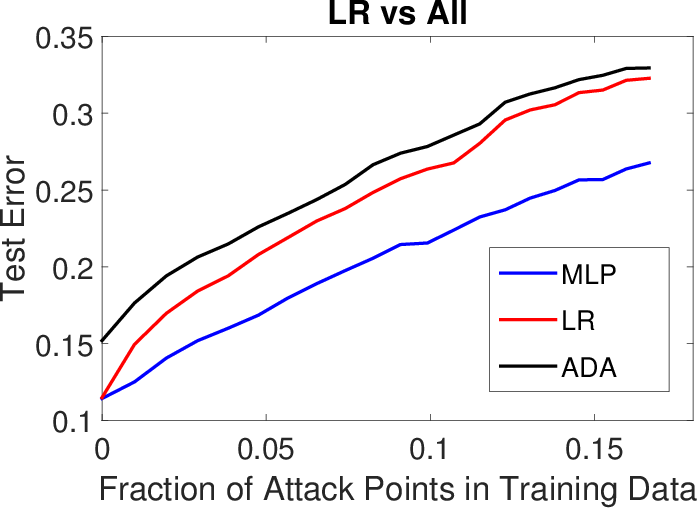
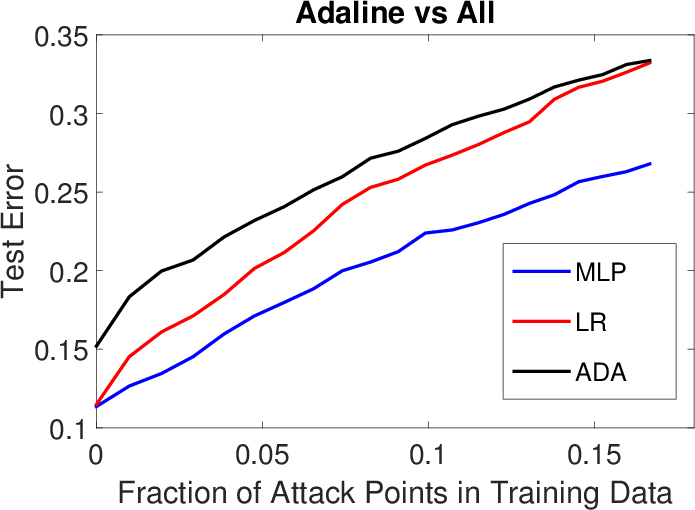
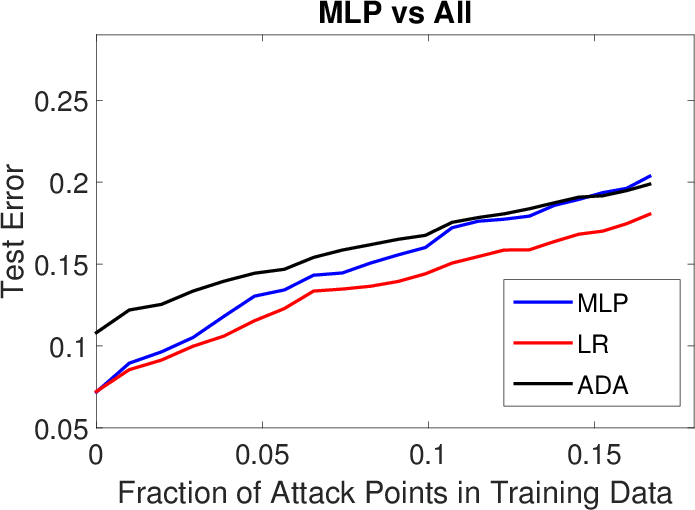
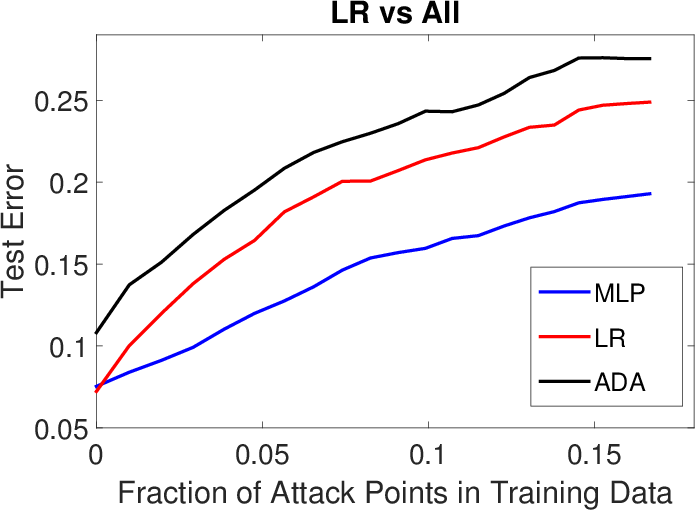
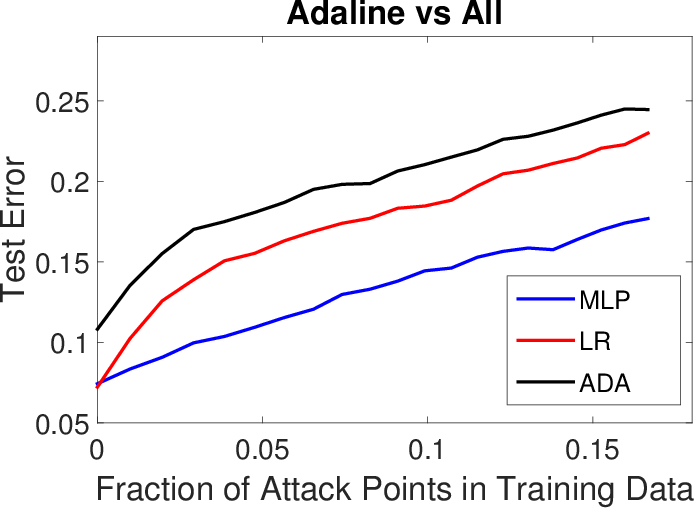
Figure 2: Results for LK-SL poisoning attacks (transferability of poisoning samples) on Spambase (top row) and Ransomware (bottom row).
Application to Deep Networks
The paper also provides a proof-of-concept for executing such attacks on convolutional neural networks (CNNs) on the MNIST digit recognition task. The study finds neural networks’ decision boundaries in the input space contribute to their vulnerability to well-crafted adversarial training examples, highlighting the nuanced difficulties deep learning models face under such poisoning scenarios.
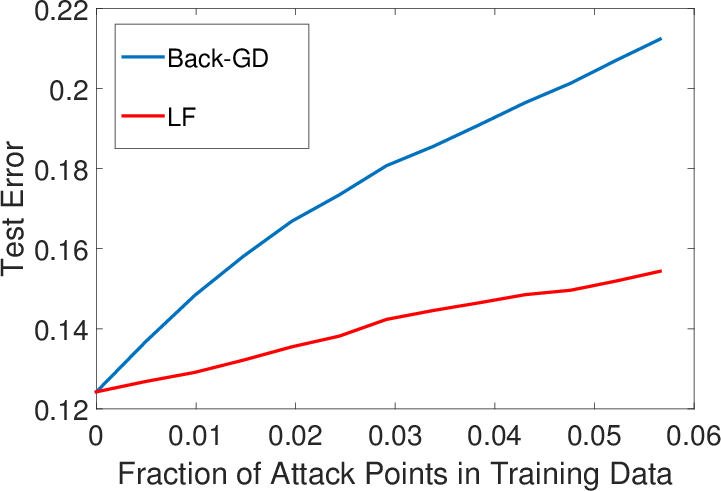
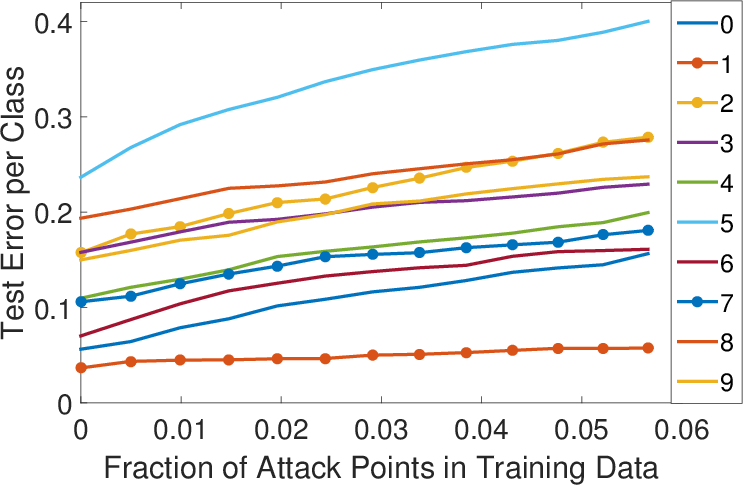
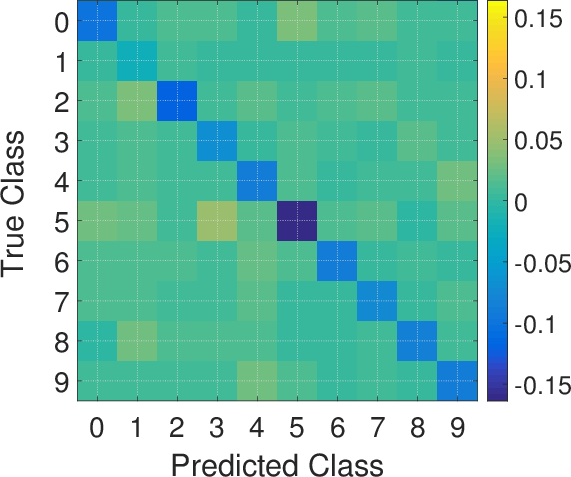
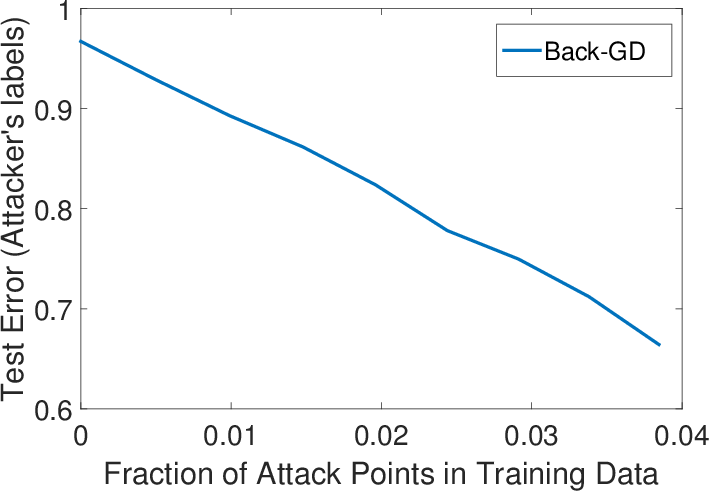
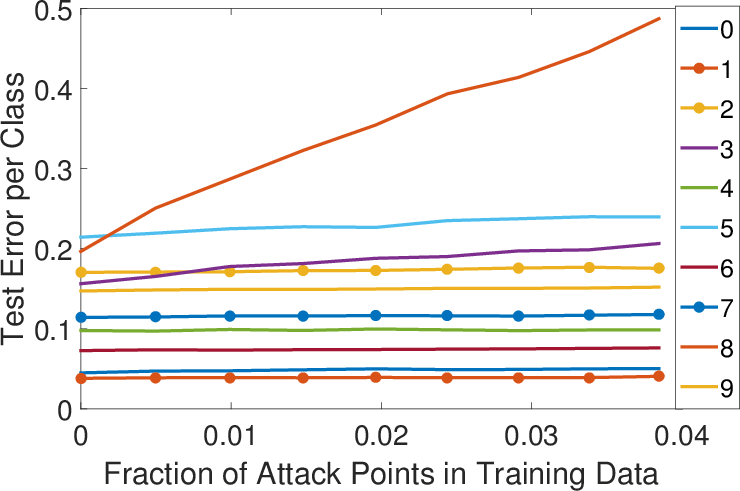
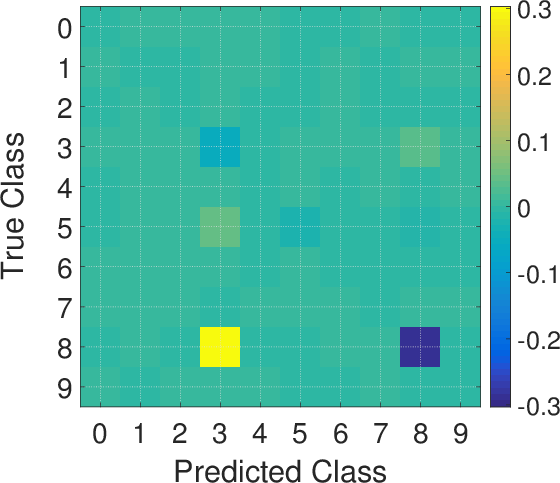
Figure 3: Error-generic (top row) and error-specific (bottom row) poisoning against multiclass LR on the MNIST data.
Conclusion
In conclusion, the study juxtaposes traditional machine learning algorithms against deep learning architectures under adversarial conditions controlled by an intelligent threat model. While traditional models displayed susceptibility, the paper recognizes deep learning models' resilience, albeit acknowledging potential vulnerabilities. Future work could bridge gaps in understanding universal perturbations for deep learning models and defense mechanisms against increasingly sophisticated poisoning strategies. This research thus pushes the envelope in securing learning systems in environments perennially exposed to adversarial manipulation.