- The paper presents a comprehensive overview of deep reinforcement learning, detailing the integration of deep neural networks with classical RL frameworks.
- It categorizes methods into value-based, policy search, and actor-critic architectures, highlighting key algorithms like DQN and improvements such as double Q-learning.
- It discusses current challenges including data efficiency, exploration strategies, and interpretability, while speculating on hybrid systems combining deep learning with symbolic reasoning.
Comprehensive Survey of Deep Reinforcement Learning
Foundations and Evolution of Reinforcement Learning
The surveyed paper delineates the conceptual and mathematical groundwork of RL, focusing on the paradigm where autonomous agents learn to optimize behavior via trial-and-error within high-dimensional environments. The framework formalizes RL as an instance of Markov Decision Processes (MDPs) incorporating states, actions, transition dynamics, reward functions, and discount factors. The paper points out critical challenges, including the temporal credit assignment problem, strong temporal correlations in observations, and the necessity for scalable learning in complex, high-dimensional domains.
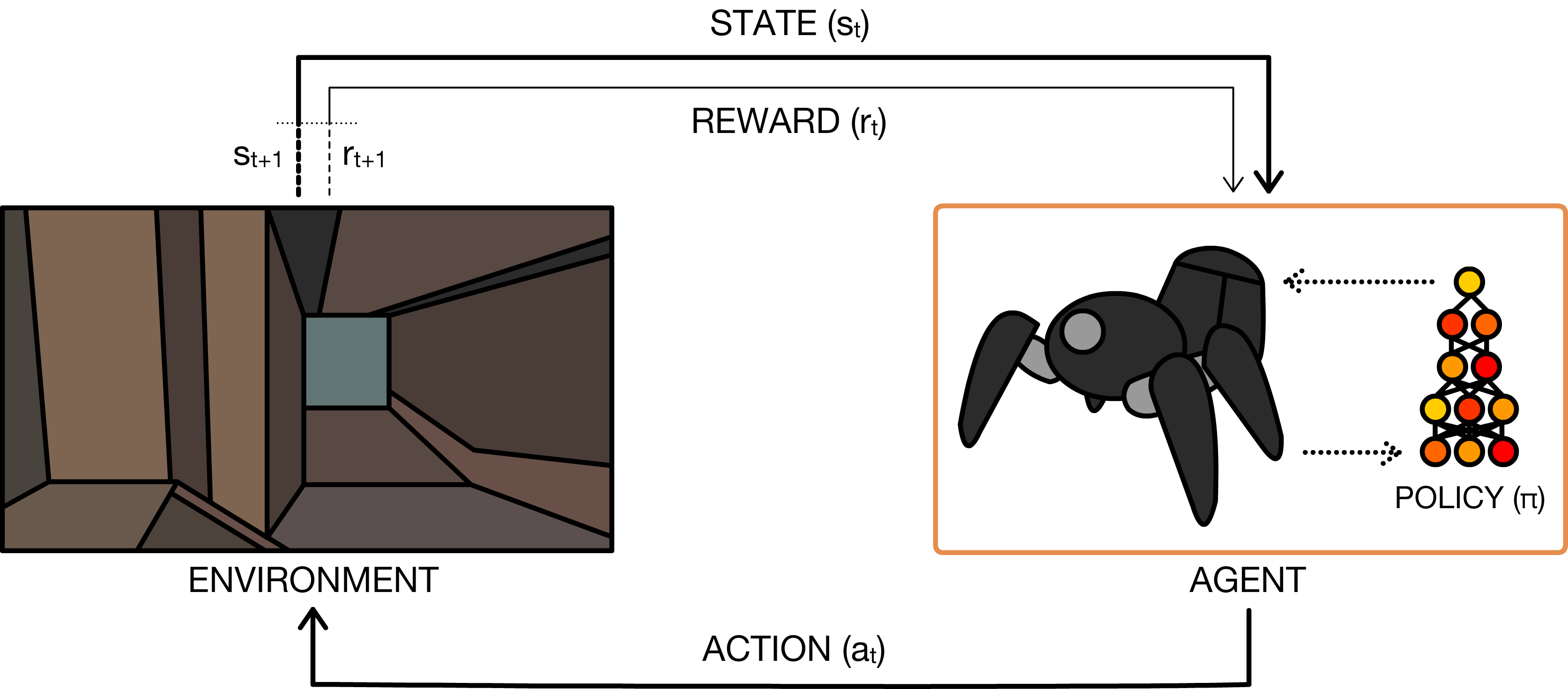
Figure 1: Illustration of the perception-action-learning loop formalizing agent-environment interaction with sequential state, action, and reward feedback.
A central motivation for the integration of deep learning into RL is the ability to efficiently process and represent high-dimensional sensory data, such as visual inputs, which allows RL algorithms to scale to previously intractable tasks. Figure 2 catalogues diverse RL domains explored, from Atari games to robotic manipulation and visual navigation.

Figure 2: Representative DRL domains, including Atari 2600 games, robotic control, simulated car racing, transfer from simulation to real-world robotics, indoor navigation, and neural attention for image captioning.
Algorithmic Taxonomy of RL and DRL
The paper systematically reviews canonical algorithmic families in RL—value function methods, policy search methods, and hybrid actor-critic architectures—together with their historical and contemporary deep learning instantiations.
Value Function Methods
Value-based RL algorithms estimate state or state-action value functions (Vπ, Qπ), employing techniques such as temporal difference (TD) learning and dynamic programming. The deep Q-network (DQN) [mnih2015human] is identified as a seminal DRL algorithm, leveraging convolutional neural networks for Q-function approximation directly from raw pixels in Atari environments. DQN stabilizes learning through experience replay and target networks, addressing function approximation instability.

Figure 3: Schematic of the DQN, highlighting end-to-end learning from stacked visual frames to discrete action selection and reward-based Q-learning.
The evolution of Q-function approaches includes enhancements such as double Q-learning for mitigating overestimation bias, distributional RL for modeling value distributions, duelling architectures separating advantage and value estimation, and scalable action embedding strategies for large action spaces. The NAF algorithm extends Q-learning to continuous control through a convex advantage function.
Saliency analysis elucidates the interpretability of DRL agents, demonstrating the capacity to identify task-relevant visual features in high-dimensional input (Figure 4).
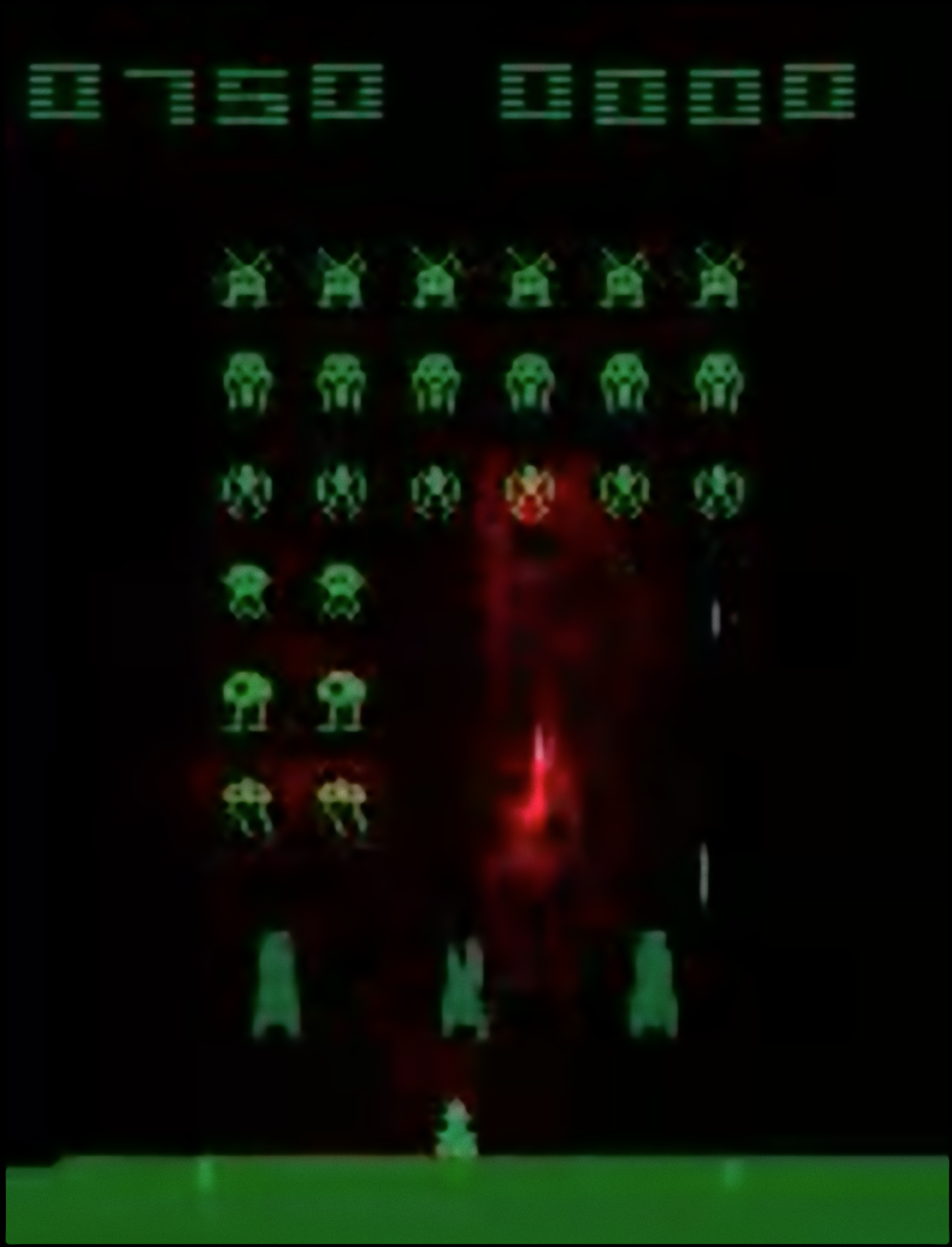
Figure 4: Saliency map of a trained DQN, showing prioritized attention to actions and anticipated outcomes within “Space Invaders”.
Policy Search and Actor-Critic Architectures
Policy search methods directly optimize parameterized policies, either via gradient-free evolutionary algorithms or gradient-based policy gradient methods (e.g., REINFORCE). Backpropagation remains the principal optimization technique, augmented by variance reduction baselines such as advantage estimation and trust region strategies (TRPO, PPO).
Actor-critic methods unify value function estimation and policy optimization, enabling variance-bias tradeoffs and enhanced sample efficiency, further improved via off-policy learning and distributed asynchronous training (A3C, A2C).
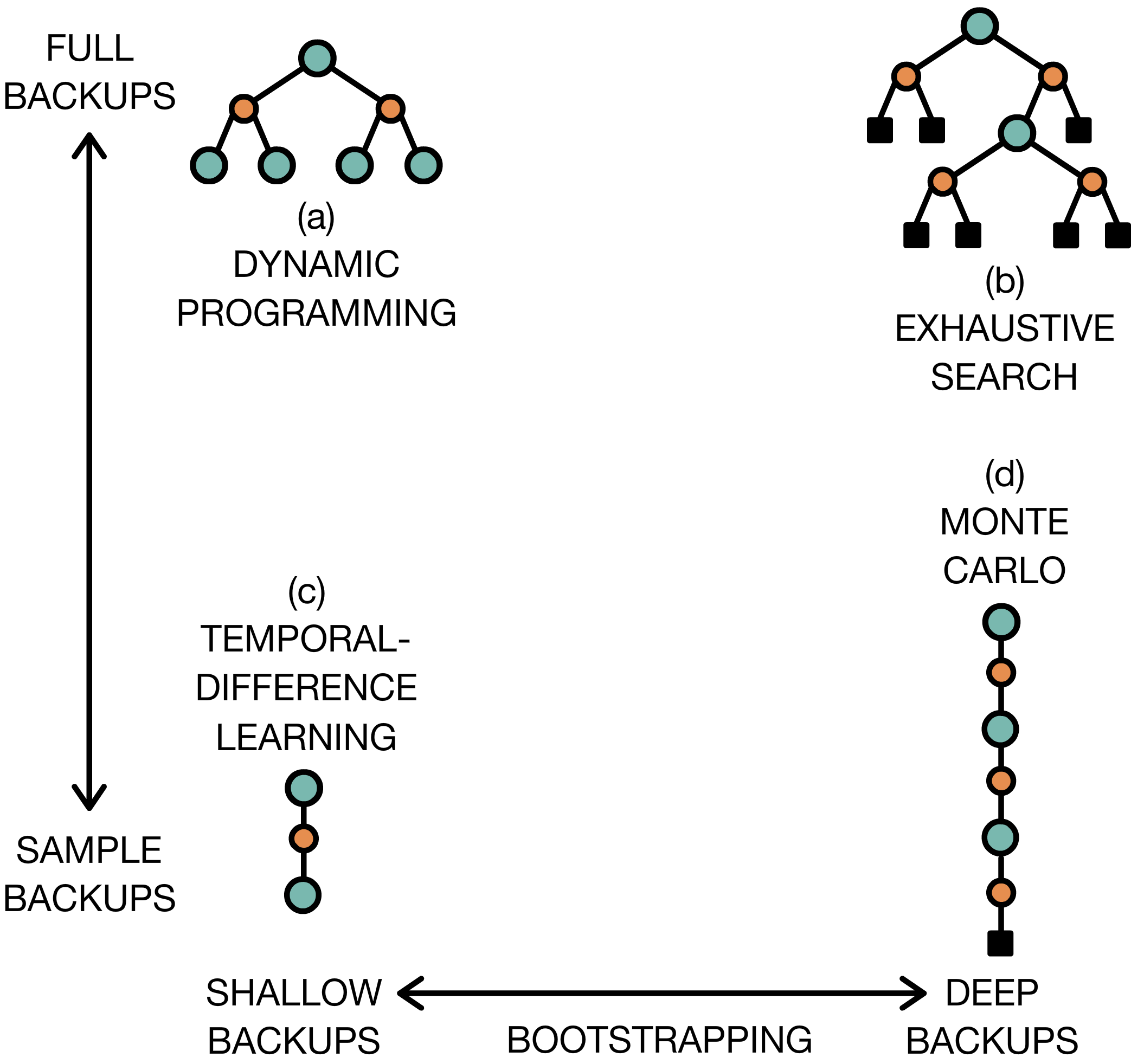
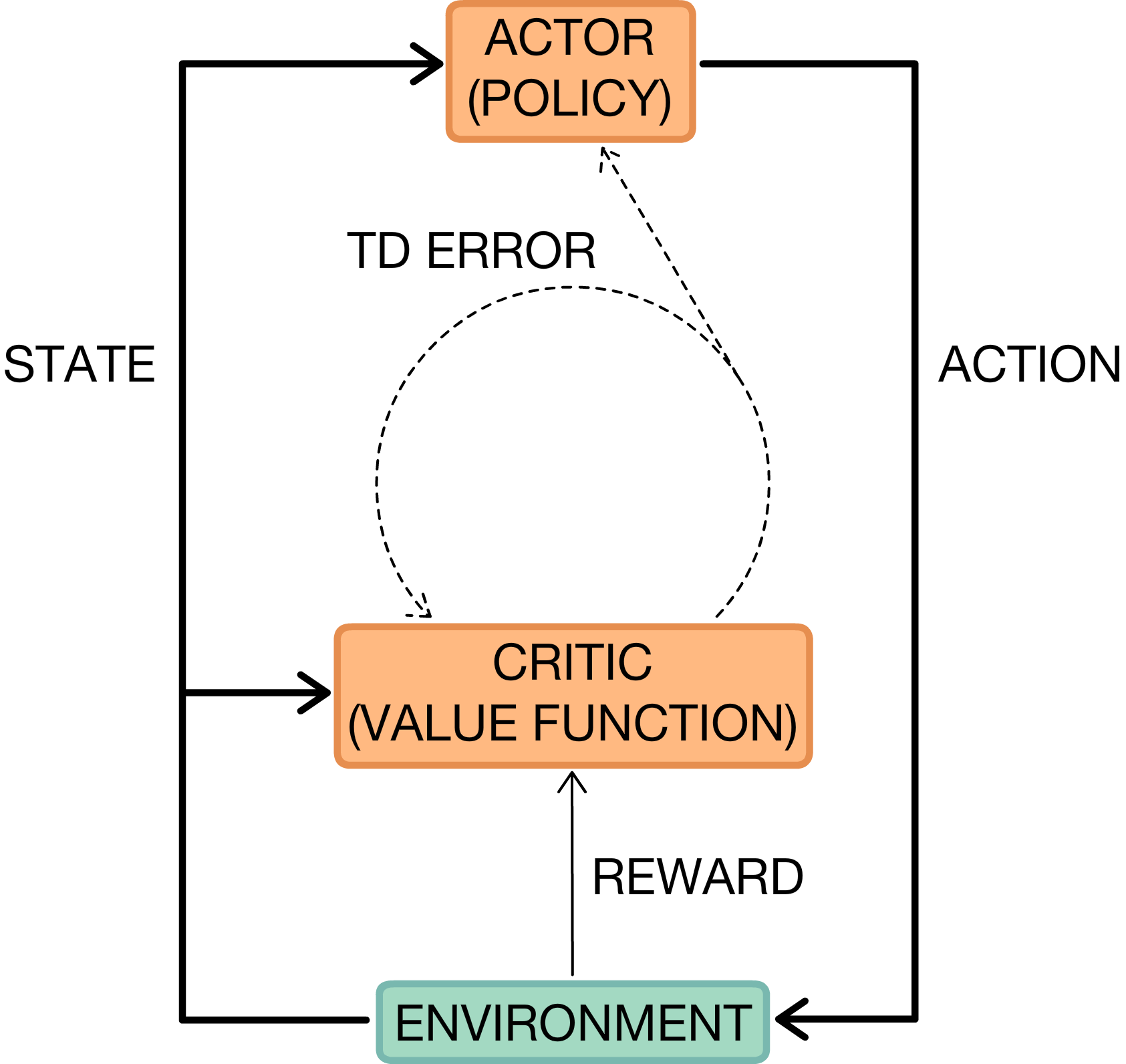
Figure 5: Two-dimensional taxonomy of RL algorithms, ranging from dynamic programming to Monte Carlo sampling, and from expectation-based to sampling-based backups.
Recent advances include deterministic policy gradients (DPG, DDPG) for improved sample efficiency in continuous action spaces, stochastic value gradient (SVG) methods, and interpolated policy gradients (IPG) for unifying on-policy and off-policy updates. Parallelization and auxiliary tasks further accelerate learning and representation acquisition in DRL agents.
Current Research Directions and Challenges
Model-Based DRL
Model-based approaches attempt to learn transition dynamics for improved data efficiency and planning. Autoencoder-based latent embedding models, deep predictive models, and successor representations offer alternative methodologies for leveraging learned dynamics, though deep models typically require large sample sizes.
Exploration, Hierarchical Architectures, and Transfer
The survey comprehensively treats exploration versus exploitation, highlighting strategies such as ϵ-greedy, temporally correlated noise, bootstrapped Q-learning, and principled upper confidence bounds—augmented by intrinsic motivation for unsupervised exploration.
Hierarchical RL employs options and subpolicies to address temporal abstraction, with advances in automatic goal discovery and multi-level policy architectures.
Imitation learning, inverse RL, and generative adversarial imitation learning (GAIL) provide supervised signals for learning, enabling adaptation and generalization beyond demonstration-based behavioral cloning. Multi-agent RL extends DRL to non-stationary, cooperative, and competitive multi-agent environments, with mechanisms for differentiable inter-agent communication.
Memory-augmented DRL incorporates recurrent architectures and differentiable external memory modules for improved handling of POMDPs and information integration, fostering advances in navigation, planning, and temporal reasoning.
Transfer learning, multitask learning, and curriculum learning constitute important directions for knowledge reuse, sample efficiency, and domain adaptation, with contemporary frameworks enabling policy distillation and progressive network expansion for overcoming catastrophic forgetting.
Evaluation and Benchmarking
The paper details standardized evaluation domains such as the Arcade Learning Environment (ALE), MuJoCo, ViZDoom, TorchCraft, DeepMind Lab, and OpenAI Gym, all of which facilitate reproducible and comparable research in DRL.
Theoretical and Practical Implications
The deep reinforcement learning paradigm represents convergence between function approximation, unsupervised representation learning, and trial-and-error optimization, offering principled frameworks for autonomous agents learning directly from raw sensory streams. Practical implications include improvements in robotics, autonomous control, visual navigation, and complex task automation. Theoretical implications concern the generalization capabilities, representation efficiency, and causal reasoning capacities of DRL agents. The surveyed research underscores the importance of integrating DRL with classical AI techniques (e.g., search, planning, causal modeling) for enhanced sample complexity, interpretability, and robustness.
Conclusion
The paper provides an authoritative overview of the field of deep reinforcement learning, tracing its origins, algorithmic diversity, and ongoing challenges. Major milestones include end-to-end learning from pixels, robust policy optimization in complex domains, and scalable architectures via distributed and parallel computation. Several open problems remain—including data efficiency, generalization, transfer across domains, interpretability, and integration with symbolic reasoning. The trajectory outlined indicates future progress toward general-purpose autonomous agents capable of complex adaptive behavior in real-world environments.
Speculation on Future AI Developments
The advancement of DRL algorithms will likely catalyze progress in generalizable, sample-efficient, and robust AI agents. Research focusing on hybrid systems combining deep learning, causal inference, and knowledge structures may yield architectures capable of superior reasoning and transfer. Improved theoretical understanding of neural representations and decision-making dynamics in DRL will further inform the design of AI systems able to learn and act across increasingly complex, diverse environments.