- The paper demonstrates that current automatic metrics (e.g., BLEU, ROUGE) often fail to capture sentence-level nuances compared to human evaluations.
- It examines discrepancies across datasets and NLG systems, highlighting issues like scale mismatch and system-specific variability in metric performance.
- The study calls for developing new, context-aware evaluation methods, including reference-less and discriminative models for more reliable assessments.
Necessity for New Evaluation Metrics in NLG
Recent advancements in Natural Language Generation (NLG) have led to the widespread adoption of automatic metrics for evaluating system performance, primarily due to their cost-effectiveness and rapid processing capabilities. However, this paper seeks to underscore the inadequacies of current metrics by analyzing their correlation with human judgments, thereby advocating for new evaluation methodologies.
Examination of Current Metrics
The study focuses on Word-Based Metrics (WBMs) and Grammar-Based Metrics (GBMs), scrutinizing their ability to reflect human evaluations effectively in the context of end-to-end, data-driven NLG systems. Evaluated metrics include, but are not limited to, BLEU, ROUGE, METEOR, and SMATCH, alongside grammar indicators such as Flesch Reading Ease scores and Stanford Parser scores. The analysis spans multiple datasets and domains to ensure comprehensive insights.
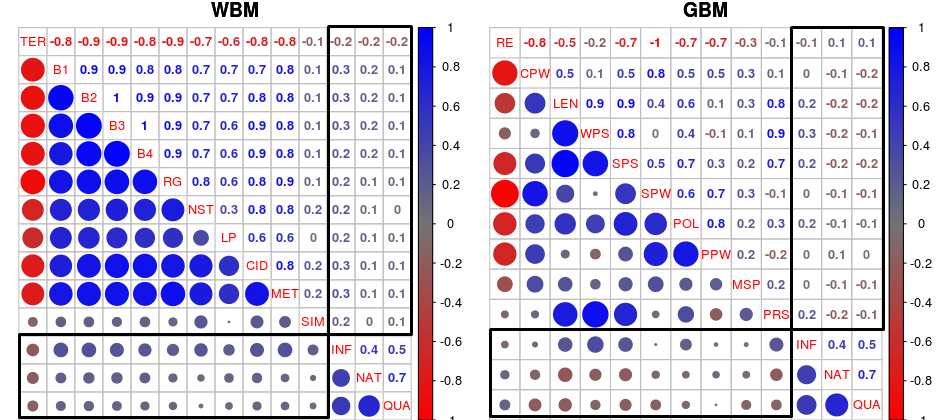
Figure 1: Spearman correlation results for on . Correlations between human ratings and automatic metrics are highlighted, with blue circles indicating positive and red indicating negative correlations. The circle size denotes correlation strength.
Data-Driven NLG Systems
Three distinct NLG systems are evaluated: RNNLG, TGEN, and JLOLS, each leveraging different methodologies for sentence planning and surface realization. The systems are tested across various datasets, with outputs compared against human references for informativeness, naturalness, and quality.
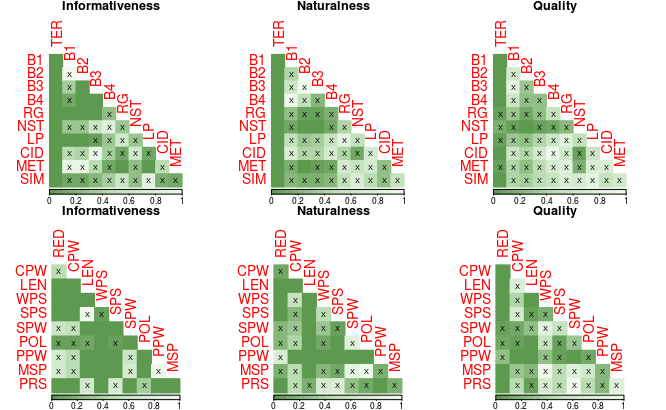
Figure 2: Williams test results: The significance of correlation differences between metrics and human ratings.
The results reveal significant discrepancies between automatic metric evaluations and human judgments. While automatic scores may align at the systemic level, they often fail to capture nuances at the sentence level. This misalignment is particularly pronounced in outputs with middle-range human ratings, where metrics inaccurately reflect user satisfaction. Furthermore, system performance is observed to be highly dataset-specific, suggesting that current metrics lack robustness across different contexts.
Human and Automatic Metric Correlation
The study provides a detailed correlation analysis between human evaluations and various metrics. The analysis suggests that none of the metrics achieve a moderate correlation across the board, with outputs traditionally evaluated as either good or bad reflecting more accurate correlations than those rated average.
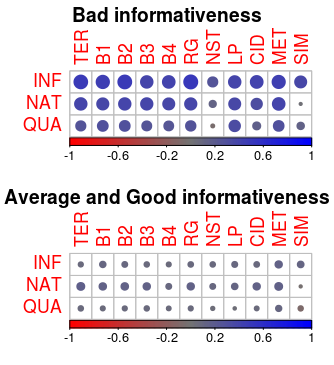
Figure 3: Correlation between automatic metrics (WBMs) and human ratings, differentiated by informativeness levels.
Limitations of Current Approaches
The paper identifies several limitations inherent in current evaluation practices:
- Assumption of Gold Standards: Current metrics presuppose that human references are correct and complete, which is frequently invalid, particularly in crowdsourced datasets where ungrammatical references may skew accuracy.
- Scale Mismatch: The quantitative scale of metric outputs versus qualitative human judgments presents alignment challenges.
- System-Specific Variability: The dependency of metrics on specific system architectures and datasets dilutes their reliability across broader applications.
Conclusions and Future Directions
The authors conclude that state-of-the-art automatic evaluation metrics inadequately reflect human evaluations, underscoring the necessity for human assessments in the development of NLG systems. Future directions include the exploration of reference-less evaluations and discriminative models, alongside enhancements to existing metrics to improve cross-domain performance.
In advancing the field, the integration of advanced contextual assessments and extrinsic evaluation methods offers promising avenues for developing more reliable, system-independent evaluation metrics for NLG technologies.