- The paper proposes integrating atrous convolution with ASPP modules to enhance multi-scale context capture in deep convolutional networks.
- It demonstrates that fine-tuned batch normalization and a revised training protocol yield significant segmentation accuracy improvements, achieving 85.7% mean IOU.
- The method eliminates the need for additional post-processing, making it efficient for practical applications like autonomous driving and medical imaging.
Rethinking Atrous Convolution for Semantic Image Segmentation
The paper "Rethinking Atrous Convolution for Semantic Image Segmentation" (1706.05587) explores advanced techniques for improving semantic segmentation in DCNNs, focusing on atrous (dilated) convolution. The authors propose several novel strategies integrating atrous convolution to enhance multi-scale context capturing capabilities and demonstrate superior performance compared to previous methodologies without additional post-processing like DenseCRF.
Atrous Convolution Mechanics
Atrous convolution manipulates the field-of-view of filters in DCNNs without increasing the number of parameters, effectively addressing challenges posed by downsampling during feature extraction. Standard convolution is a form with rate=1, whereas atrous convolution expands the input signal sampling by inserting zeros between filter weights, shown to maintain detailed spatial information critical for segmentation tasks.


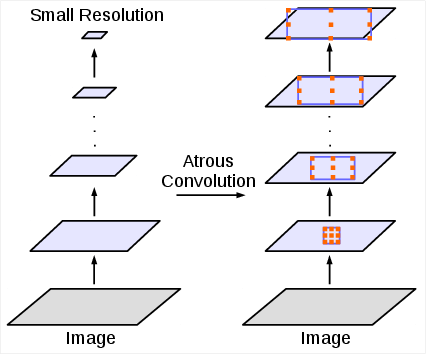

Figure 1: Alternative architectures to capture multi-scale context.
Multi-Scale Context Integration
The occurrence of objects at varying scales presents a significant challenge in semantic segmentation. The authors address this problem by implementing atrous convolution in both cascaded modules and parallel configurations using Atrous Spatial Pyramid Pooling (ASPP). Notably, ASPP involves multiple atrous convolutions applied at varying rates to capture robust multi-scale information, augmented by image-level features to embed global context effectively.

Figure 2: Visualization results on the val set when employing our best ASPP model. The last row shows a failure mode.
Training and Implementation
To facilitate efficient training with atrous convolution, a revised protocol includes fine-tuning batch normalization and maintaining intact ground truth annotations, counteracting potential data loss from downsampling. The model is initially trained with ImageNet-pretrained ResNet modified for atrous convolution, leveraging significant data augmentation strategies for better object segmentation fidelity.


Figure 3: Bootstrapping on hard images improves segmentation accuracy for rare and finely annotated classes such as bicycle.
Experimental Evaluation
The proposed DeepLabv3 model exhibits marked improvement over previous versions, achieving a 85.7% mean IOU on the PASCAL VOC 2012 test set without DenseCRF. This efficiency largely stems from incorporating fine-tuned batch normalization parameters and ASPP augmented with image-level features, optimizing feature response density and multi-scale recognition.
Practical Implications
Atrous convolution's adaptability in filter field-of-view makes it highly suitable for deploying DCNNs in real-world applications where multi-scale object recognition is crucial—such as autonomous driving systems and medical image analysis. Moreover, by circumventing the need for extensive post-processing, compute resources are economized, enabling deployments in resource-constrained environments.

Figure 4: Visualization results on Cityscapes val set.
Conclusion
The advancements introduced in this paper by revisiting atrous convolution and ASPP modules contribute significantly to semantic image segmentation's performance. Future exploration can extend to integrating these methodologies with complementary enhancements like learned deformation in convolutions and hybrid network architectures, underpinning continued progress in machine vision applications.