- The paper reveals that thermal constraints cap HMC performance, with increased bandwidth driving operational temperatures toward critical limits.
- It employs extensive experiments using the AC-510 accelerator to measure latency, power consumption, and throughput trade-offs under various cooling conditions.
- The findings underscore the need for advanced thermal management and optimized data mapping to fully exploit 3D-stacked memory architectures.
Demystifying the Characteristics of 3D-Stacked Memories: A Case Study for Hybrid Memory Cube
Introduction and Motivation
In contemporary computational systems, processor-centric architectures predominate, characterized by separate processor and memory units connected via the JEDEC protocol. However, the advent of 3D-stacked memory architectures, notably the Hybrid Memory Cube (HMC), promises substantial advancements in memory bandwidth and energy efficiency. The integration of dynamic random-access memory (DRAM) and logic dies in a 3D configuration allows for high internal concurrency and reduced latency. This architectural refinement paves the way for innovative memory designs, such as processor-in-memory (PIM) configurations.
This study delineates the thermal characteristics and performance bottlenecks of HMCs, focusing on latency, bandwidth, and their correlation with power consumption and operational temperature, topics underexplored in existing literature. Extensive experimental characterizations using the AC-510 accelerator are presented, revealing that temperature emerges as a pivotal constraint in the performance cap of HMCs.
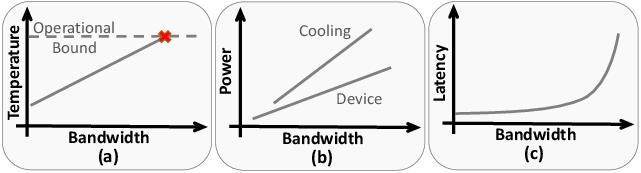
Figure 1: Conceptual graphs showing relationships between the temperature, power consumption, latency, and bandwidth of HMC.
Hybrid Memory Cube Architecture
HMC Structure
The HMC integrates multiple DRAM layers stacked atop a logic layer, interconnected via through-silicon vias (TSVs). This vertical integration enhances internal bandwidth while minimizing communication energy and latency. The HMC 1.1 configuration includes eight DRAM layers segmented into 16 partitions, each controlled by dedicated memory controllers in the logic die.
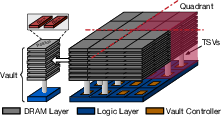
Figure 2: 4\,GB HMC~1.1 internal structure.
With a focus on HMC 1.1 specifications, choicest due to its current hardware availability, comparisons are drawn against HMC 2.0, highlighting evolutions such as increased bank and vault counts, which facilitate greater memory operations per layer.
Communication Protocol and Address Mapping
Adopting a packet-based communication protocol, the HMC achieves superior throughput by employing high-speed SerDes circuits over traditional synchronous buses. Memory accesses and control logic converge into flits, ensuring efficient packet routing and integrity.
Address mapping capitalizes on low-order interleaving, optimizing block distribution to vaults and banks. This mapping strategy enhances parallelism, promoting high bandwidth utilization across distributed access patterns.
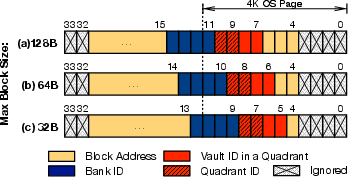
Figure 3: Address mapping of 4\,GB HMC\,1.1 with various maximum block size of (a) 128\,B, (b) 64\,B, and (c) 32\,B.
Experimental Results and Analysis
Bandwidth and Thermal Dynamics
HMC's bandwidth performance was meticulously tested across varying access patterns, uncovering that optimal throughput is realized through distributed accesses spanning multiple vaults and banks. Crucially, the study delineates the thermal consequences of increased bandwidth: higher data throughput escalates operational temperatures, potentially necessitating advanced thermal management solutions.
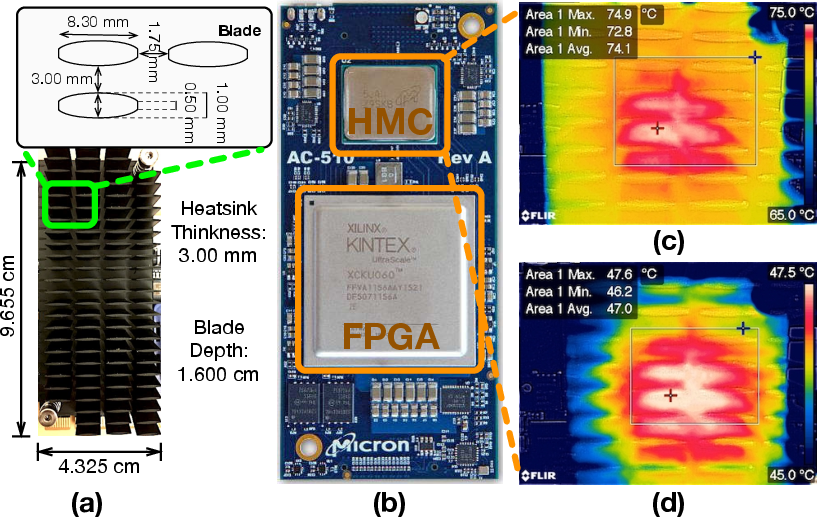
Figure 4: AC-510 accelerator with (a) and without the heatsink (b), and two images of the HMC with various temperature, taken by the thermal camera showing heatsink surface temperature (c,d).
Experiments conducted under different cooling configurations reveal that write-dominant workloads heighten thermal risk, pegging the operational temperature ceiling around 75∘C for reliability—lower than read-focused tasks.
Power Efficiency and Latency Trade-offs
The study evaluates power efficiency, establishing a proportional relationship between bandwidth, cooling power, and device power consumption. Practical limitations stemming from inherent DRAM row policies—closed-page operation—prompt bandwidth optimization via increased request sizes rather than reliance on access locality.
Latent latency assessments under various loads disclose how queue depths within HMCs impact effective access times. Critical analyses of latency in high-load environments underscore the latency-bandwidth trade-off, a pivotal consideration for future architectural and compiler strategies.
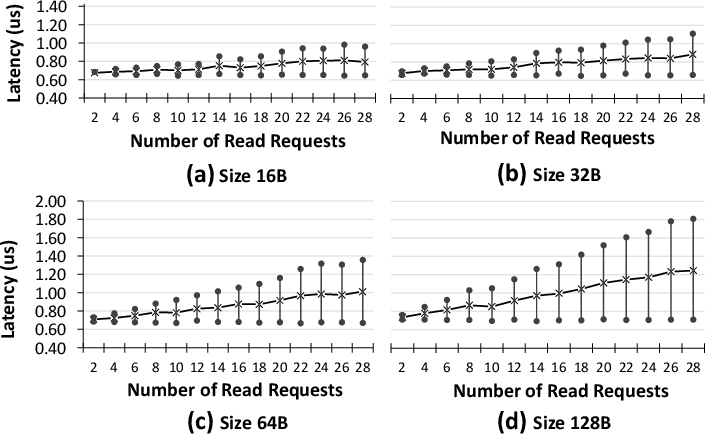
Figure 5: Average, minimum, and maximum latency of low-load accesses for various request sizes.
Conclusion
This comprehensive characterization of 3D-stacked memories underscores the architectural benefits and bottlenecks inherent in HMC design. Key insights affirm the necessity for distributed data accesses and expanded BLP to counteract latency and thermal concerns. The findings advocate for optimizations at multiple system levels—encompassing thermal management, data organization, and power utilization—to harness the full potential of HMC technologies in high-performance computing domains. Although bounded by certain operating conditions, HMCs demonstrate robust scalability, reinforcing their viability in future memory technology advancements.

