- The paper introduces a novel end-to-end CNN with an encoder-decoder architecture and skip links to effectively harmonize composite images.
- The joint training scheme integrates scene parsing for pixel-level semantic guidance, significantly improving the harmony between foreground and background.
- Experimental results with synthesized datasets and user studies validate the method's superior performance and suitability for real-time photo editing.
Deep Image Harmonization: An Expert Review
The paper "Deep Image Harmonization" introduces an advanced deep learning framework aimed at addressing the challenges involved in creating realistic composite images by harmonizing the appearances of foreground and background regions. This novel approach leverages a convolutional neural network (CNN) architecture to incorporate both contextual and semantic information, ensuring pixel-wise compatibility in composite images. In this review, we dissect the methodology, experimental findings, and implications of this work in the domain of image processing and AI-driven photo editing.
Methodology
End-to-End CNN Architecture
The proposed solution stands as an end-to-end trainable CNN model, composed of an encoder-decoder structure designed to optimize the harmonization of composite images. The encoder extracts meaningful feature representations while the decoder reconstructs the harmonized image, adjusting the appearance of the foreground region against the background context. The inclusion of skip links between the encoder and decoder retains detailed image textures that conventional methods overlook, thus enhancing image realism.
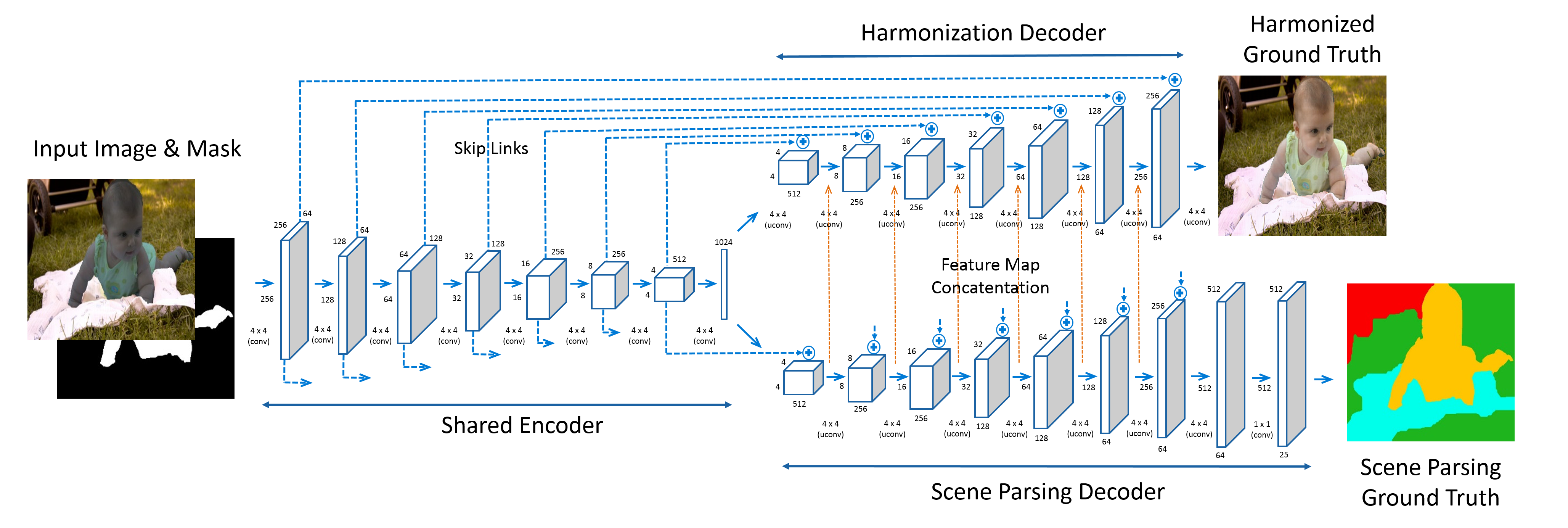
Figure 1: The proposed joint network architecture showcases the integration of semantic cues through scene parsing, enhancing harmonization results.
Recognizing the significance of semantic understanding in harmonization tasks, the paper introduces an additional decoder dedicated to scene parsing, which jointly trains with the harmonization process. The decoder extracts pixel-wise semantic labels that permeate the harmonization decoder via feature map concatenation, guiding the aesthetic adjustments of foreground elements based on learned semantic context, such as correct coloration of sky or skin.
Data Acquisition for Training
Synthesized Datasets
To support the learning process, the researchers devised sophisticated data acquisition methods, creating large-scale synthetic datasets from Microsoft COCO, MIT-Adobe FiveK, and Flickr. This involved generating composite images through color transfer techniques applied to segmented objects or scenes in reference images, producing harmonized images reflective of true realism.


Figure 2: The data acquisition process is illustrated for generating training pairs from various datasets, enhancing model learning capacity.
Experimental Evaluation
Quantitative and Qualitative Assessment
The paper provides extensive experimental results demonstrating superior performance of the proposed CNN in harmonizing composite images, both synthesized and real. Quantitative metrics include mean-squared errors (MSE) and PSNR scores, where the joint training network consistently outperformed existing methods, validating the model's capability to generalize across varying image datasets.
(Figure 3, Figure 4)
Figure 3: Harmonization results on synthesized datasets reveal the efficacy of the joint network with enhanced PSNR scores.
Figure 4: Real composite image results from the proposed network establish its effectiveness in generating visually realistic outcomes.
User Study and Real Composite Images
A user study leveraging the Bradley-Terry model further gauged the realism of images produced by the method versus other state-of-the-art techniques. Results strongly favored the joint network as users perceived images from this method as more visually coherent and realistic compared to competitors.
Practical Implications
The adoption of an end-to-end CNN framework allows for rapid processing speeds, significantly reducing turnaround times from minutes to mere seconds—from traditional CPU-driven methods to GPU-accelerated harmonization. This ensures applicability for real-time photo editing applications, overcoming the latency challenges of previous approaches.
Conclusion
The "Deep Image Harmonization" paper presents a substantial advance in photo editing technology, leveraging deep learning to resolve the intricate task of image compositing with both contextually and semantically-aware adjustments. This work lays a foundation for future investigations into AI-driven image editing, proposing a scalable approach that bridges technical prowess with practical deployment capabilities. By fostering synthesized datasets and semantic integration, this study contributes valuable insights towards developing AI systems that natively understand and replicate human-like photo editing finesse.

