- The paper introduces HRAN, which integrates word-level and utterance-level attention to effectively model multi-turn dialogues.
- HRAN achieves significant improvements in perplexity (41.14) and human evaluation margins compared to baselines like VHRED and HRED.
- Ablation studies confirm that dual-level attention is crucial for selecting contextually relevant content, ensuring coherent and fluent responses.
Hierarchical Recurrent Attention Network for Multi-Turn Response Generation
Introduction and Motivation
Multi-turn response generation presents unique challenges in open-domain conversational agents, requiring sensitivity to both hierarchical structure and differential informativeness across conversations. Existing encoder-decoder approaches, such as HRED and VHRED, model conversational context hierarchically but do not explicitly identify which words or utterances are salient for the current generation step, frequently producing inconsistent or irrelevant responses. The "Hierarchical Recurrent Attention Network for Response Generation" addresses this gap by proposing a model (HRAN) that integrates hierarchical structure with attention at both word and utterance levels, enabling more contextually relevant and coherent output.

Figure 1: An example of a multi-turn conversation, demonstrating the complexity of context that must be navigated for effective generation.
HRAN Architecture
HRAN operates through a three-stage hierarchical process: word-level encoding and attention, utterance-level encoding and attention, and decoding. At its foundation, HRAN employs bidirectional GRUs to encode words in each utterance, yielding hidden representations that support fine-grained attention over intra-utterance elements. Word-level attention dynamically computes the contribution of each hidden state towards forming an utterance representation, explicitly informed by both the decoder state and higher-level utterance context.
This process is recursively extended: utterance representations are sequentially processed by a backward GRU, and utterance-level attention further highlights which utterances are most consequential for the response at a given timestep. These weights form a context vector, continuously updated as decoding proceeds. Finally, a GRU decoder leverages this evolving context vector to generate the appropriate response word by word.
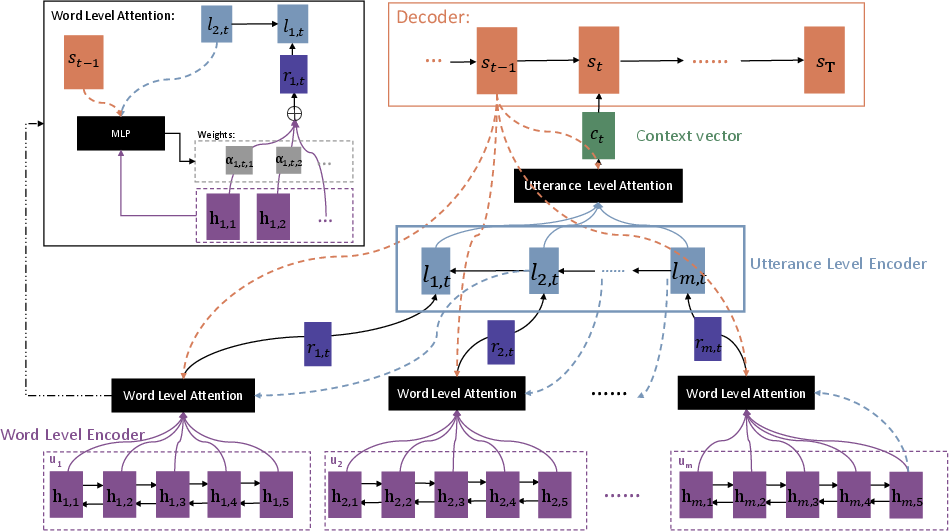
Figure 2: The architecture of the Hierarchical Recurrent Attention Network, illustrating the flow from word-level to utterance-level structure and attention, culminating in the decoder.
This architecture distinguishes itself from prior models by the dependency between word-level attention and utterance-level encoder states, aligning selection of salient content with summarizations of subsequent (i.e., more recent) context. Empirically, this setup reflects conversation flow, where later utterances in context often clarify salience of prior portions.
Experimental Setup
A large-scale dataset was constructed from Douban Group, containing over 1.6 million multi-turn dialogues, extensively preprocessed to ensure linguistic diversity and quality. Standard baselines included S2SA (flattened input, single-turn sequence-to-sequence with attention), HRED (hierarchically structured encoding/decoding), and VHRED (HRED+latent variable augmentation). All models used identical embedding and hidden state dimensions, and training was carried out using AdaDelta optimization on GPUs.
Evaluation combined perplexity (on held-out data) and rigorous, side-by-side human comparison—favoring direct qualitative assessment due to the well-known limitations of BLEU and other reference-based metrics in conversational settings.
Results: Quantitative and Qualitative Evaluation
HRAN demonstrated substantial improvements in perplexity, achieving 41.14 on the test set—a significant reduction relative to VHRED and other baselines, with p<0.01 according to t-tests. In paired human evaluations, HRAN responses were preferred over S2SA, HRED, and VHRED by margins of 6.7\%, 6.0\%, and 4.8\%, respectively. Kappa statistics confirmed robust inter-annotator agreement (κ≈0.35). The analysis of "wins" further illustrated that HRAN's improvements derived particularly from enhanced relevance and fluency, rather than simply increased verbosity.
Qualitative case analysis, as provided in the paper, showed that HRAN could navigate subtle conversational cues, both reacting appropriately to queries predicated on earlier context and initiating smooth topic transitions—capabilities underdeveloped in previous architectures.
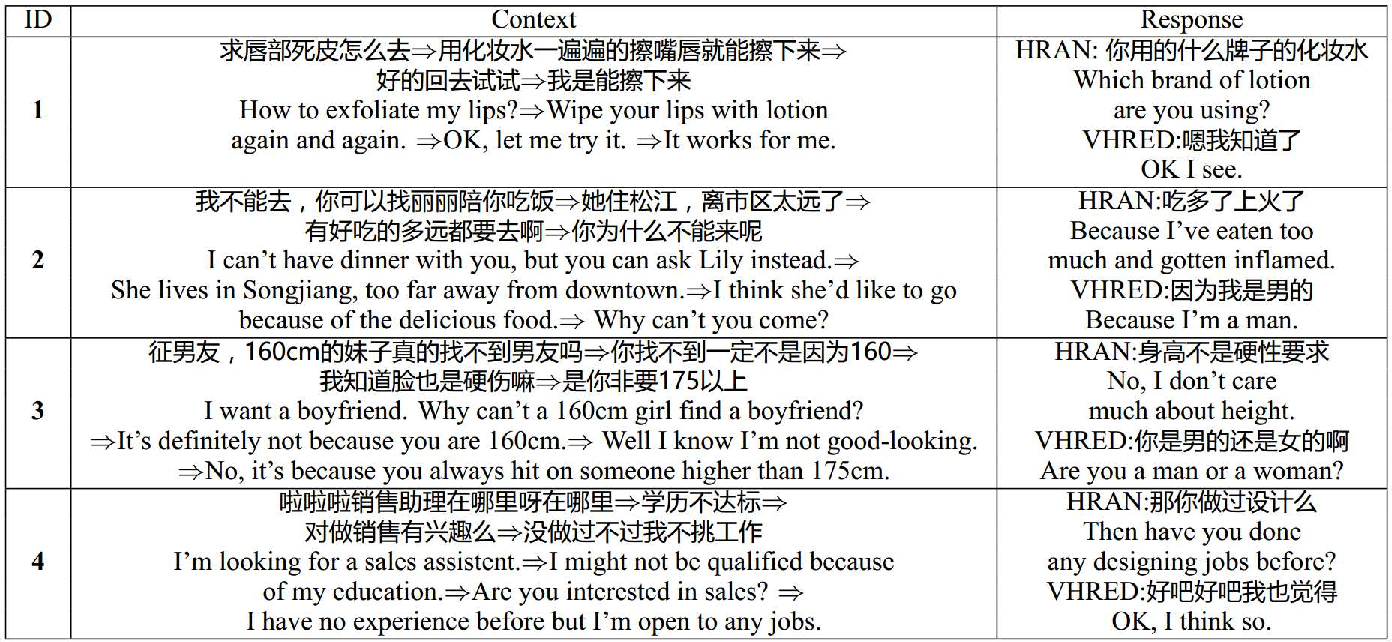
Figure 3: Case study showing utterances split by speakers, illustrating nuanced improvements in HRAN's responses compared to VHRED.
Visualization of Hierarchical Attention
Attentional visualizations highlighted HRAN’s capacity for dynamic content selection. Words and utterances integral to accurate response generation received elevated weights, visually reinforcing their impacts on the generated sequence. For example, when context included semantically loaded tokens like "girl" or "boyfriend," and numerical references to height, HRAN consistently assigned greater attention, directly influencing downstream response generation.
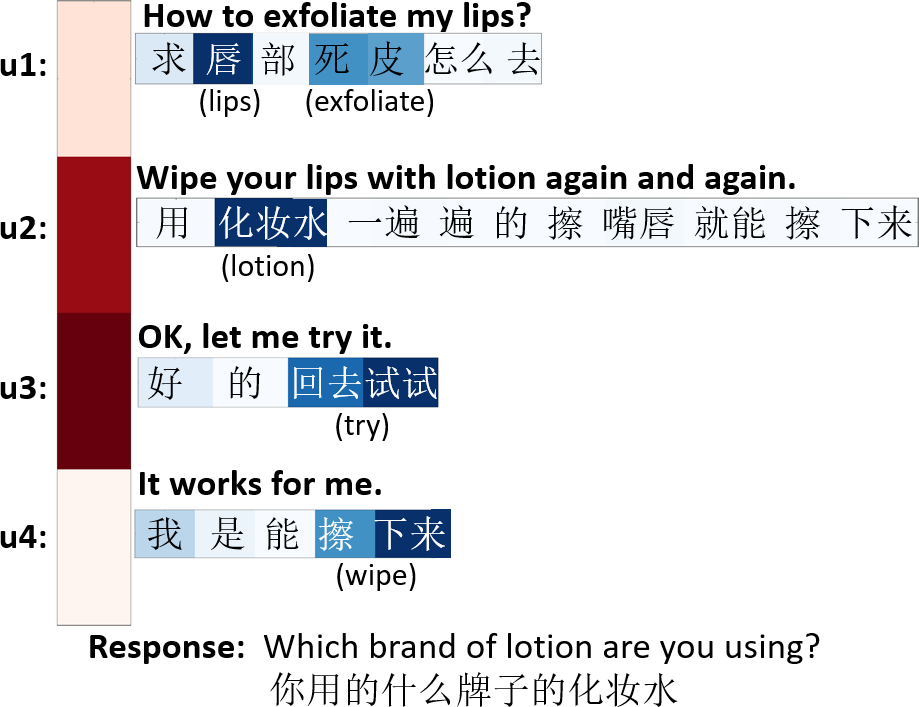



Figure 4: Visualization illustrating word and utterance attention, with shading denoting weight magnitude during response generation.
Ablation and Error Analysis
Systematic ablation underscored the essentiality of each architectural component. Removing word-level attention, utterance-level attention, or the dependency of word attention on utterance encoding each led to marked performance degradation, both in perplexity and human preference. Notably, word-level attention was shown to be the most critical: without it, the model regressed towards less informative, more generic replies.
Error analysis revealed persistent challenges common in generative models: logical contradiction (51.8\%), universal replies (26.9\%), and occasional irrelevance. These are attributed mainly to limitations in explicit logical reasoning and diversity modeling, as well as fallible attention mechanisms under complex conversational contexts.
Implications and Future Directions
HRAN's dual-level attention offers both practical and theoretical advances for conversational AI. Practically, this architecture directly enhances chatbot interaction quality in multi-turn settings without sacrificing scalability. The explicit interpretability of attention distributions provides a foundation for controllability and post-hoc diagnostics. Theoretically, HRAN illuminates the utility of hierarchical content selection under recurrent context and sets a precedent for further research into multi-granularity context modeling.
Limitations include the continued tendency to produce safe/universal responses and logical contradictions under intricate conversation dependencies. Prospective work should integrate explicit mechanisms for tracking discourse entities, modeling logic, or augmenting with external knowledge, as well as advanced diversity incentivization during decoding.
Conclusion
The HRAN framework constitutes a substantive refinement in multi-turn dialogue generation models by marrying hierarchical encoding with recurrent, dual-level attention mechanisms. Empirical results demonstrate statistically significant improvements in both automatic and qualitative human-centric measures, while attention visualizations offer interpretative clarity. This work establishes foundational techniques for future advancements in context-sensitive, multi-turn conversational modeling and paves the way for increased fidelity and utility in open-domain chatbot systems.