- The paper introduces GAIL, which learns policies directly through an adversarial training process that eliminates the need for explicit cost functions.
- It leverages occupancy measure matching and TRPO, significantly improving sample efficiency and generalization in high-dimensional continuous control tasks.
- Experimental results demonstrate GAIL's superior performance over behavioral cloning and traditional IRL methods, especially with limited expert data.
Summary of "Generative Adversarial Imitation Learning" (1606.03476)
Introduction
The authors address the problem of imitation learning, which involves training an agent to replicate expert behavior from demonstration data. The paper critiques the traditional two-step approach of inverse reinforcement learning (IRL) followed by reinforcement learning (RL) due to its indirectness and computational inefficiency. The authors propose a novel method that learns a policy directly from data without inferring a cost function, drawing an analogy to generative adversarial networks (GANs).
Background
Imitation learning typically involves two main approaches: behavioral cloning and inverse reinforcement learning. Behavioral cloning, a supervised learning method, is limited by covariate shift and requires significant data. IRL models the expert's behavior through a cost function, but often incorporates a costly RL process in an inner loop, making it computationally expensive. The authors seek a direct policy learning approach that circumvents the cost function step.
Approach
The authors propose a model-free imitation learning algorithm inspired by GANs. The method involves an adversarial process where a discriminator differentiates between real expert trajectories and generated ones. Concurrently, a generator (policy) learns to produce trajectories indistinguishable from the expert. This adversarial training approach effectively minimizes Jensen-Shannon divergence between the expert and learner's trajectory distributions.
Characterizing Optimal Policy
The proposed imitation learning algorithm leverages occupancy measures, which summarize the state-action pair distribution encountered by a policy. By casting the imitation task as an occupancy measure matching problem, the GAN-inspired approach learns a policy that directly mimics the expert, optimizing a divergence-based objective without an explicit cost function. The insight is that various cost regularizers tie closely to different imitation learning objectives.
Practical Implementation
The algorithm, termed Generative Adversarial Imitation Learning (GAIL), is developed to handle high-dimensional, continuous environments efficiently. It uses environments with dynamic models and employs trust region policy optimization (TRPO) to ensure policy updates are stable. The authors provide an optimization framework where policy and discriminator networks are iteratively updated, using sampled trajectories and adjusting to minimize the divergence-based objective.
Experimental Evaluation
GAIL is tested across several simulated control tasks with varying complexity and dimension. Results demonstrate that GAIL significantly outperforms behavioral cloning and other IRL-based methods, especially in environments demanding complex, high-dimensional control. The findings emphasize GAIL's ability to generalize even with limited expert data, owing to its data-driven imitation capability.
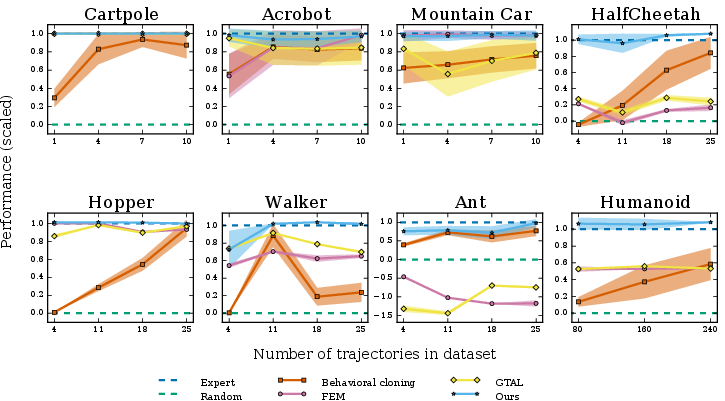
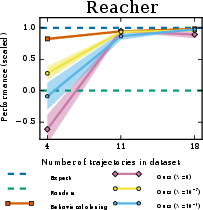
Figure 1: (a) Performance of learned policies is benchmarked against expert and random policies. (b) Impact of causal entropy regularization on Reacher task.
Discussion
The authors reflect on the balance between sample efficiency and computational complexity. While GAIL excels in imitation efficiency, it may require substantial environment interaction similar to RL. Handling environments with better models or expert interaction could enhance sample efficiency further. The paper acknowledges the potential for combining GAIL with model-based or expert-interacting approaches to optimize both data and environment interaction efficiency.
Conclusion
The proposed method introduces a powerful, general framework for imitation learning that bypasses traditional IRL complexities. By harnessing the adversarial paradigm and direct policy learning, GAIL presents a practical solution for imitation in high-dimensional domains. The promising results pave the way for further research in adversarial learning frameworks and potential enhancements by integrating model-based strategies.