- The paper presents a reinforcement learning system that personalizes SMS feedback to boost daily physical activity among type 2 diabetes patients.
- It employs a contextual bandit approach by integrating accelerometer data, demographics, and message history to predict next-day activity changes.
- The RL intervention significantly improved activity trends and reduced HbA1c, demonstrating scalable potential for digital health solutions.
Reinforcement Learning for Personalized Physical Activity Interventions in Type 2 Diabetes
Introduction
This study presents a reinforcement learning (RL) system designed to increase physical activity among sedentary patients with type 2 diabetes via personalized SMS feedback, leveraging smartphone-based activity monitoring. The system is evaluated against static and non-personalized messaging policies, with primary outcomes including changes in physical activity and secondary outcomes in glycemic control (HbA1c). The work addresses the challenge of scalable, individualized behavioral interventions in chronic disease management, integrating contextual bandit RL with real-world patient data.
System Architecture and Methodology
The intervention consists of a background smartphone application that continuously monitors physical activity using accelerometer data, transmitting activity summaries to a central server. Each morning, the RL algorithm selects a feedback message for each participant, aiming to maximize next-day activity. The system's architecture is as follows:
- Data Acquisition: The app samples accelerometer data every 3.5 minutes, detecting contiguous walking/running episodes of at least 10 minutes.
- Feature Engineering: User state is represented by demographics (age, gender), recent activity metrics (minutes walked, fraction of goal achieved), and message history (time since each feedback type).
- Action Space: Four possible daily feedback actions: negative, positive-self, positive-social, or no message.
- Reward Signal: Next-day change in activity, operationalized as the ratio of minutes walked on day t+1 to day t.
- Policy Learning: A linear regression model with interaction terms predicts the reward for each action-context pair. Boltzmann sampling (T=5) is used for action selection, balancing exploration and exploitation.
The RL approach is contextual bandit rather than full RL, focusing on immediate action effects rather than long-term state transitions, justified by data scarcity and the need for rapid adaptation.
Experimental Design
A total of 27 adults with type 2 diabetes and suboptimal glycemic control were enrolled for 26 weeks. Participants were randomized into a control group (weekly static reminders) and a personalized group (daily RL-driven feedback). All received a personal activity prescription and the monitoring app. The primary endpoint was persistent improvement in physical activity; secondary endpoints included changes in HbA1c and patient satisfaction.
Efficacy of Feedback Policies
The RL-driven personalized feedback policy demonstrated superior efficacy in increasing both the quantity and intensity of physical activity compared to static reminders and the initial random policy. Notably, the RL policy led to a positive slope in activity over time (+0.012 min/day, SEM 0.002), while control and initial policies showed negative or negligible trends.
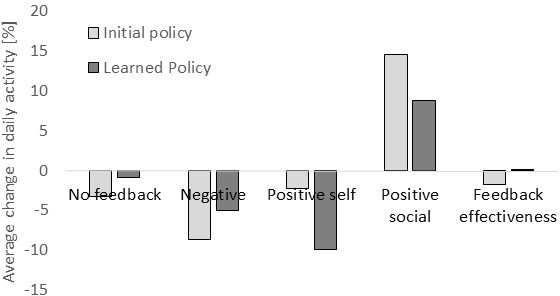
Figure 1: Change in activity following feedback messages for the two feedback policies.
Analysis of message effectiveness revealed that positive-social feedback (e.g., "You are exercising more than the average person in your group") produced the largest next-day activity increases, while negative or positive-self messages were less effective or even counterproductive on average. However, the effect of a message was modulated by the preceding message, indicating nontrivial temporal dependencies.
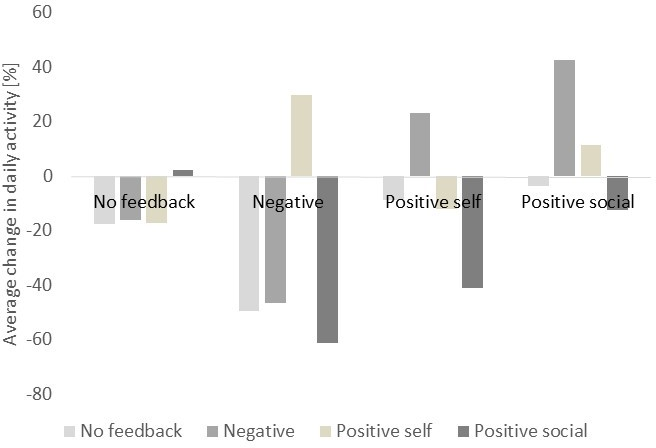
Figure 2: Change in activity as a function of feedback, grouped by current feedback and previous feedback, highlighting the importance of message sequencing.
Personalization and Heterogeneity in Response
Clustering analysis of user responses to feedback identified three distinct patient subgroups:
- Cluster 1: Negative response to all feedback (n=4)
- Cluster 2: Weak or mixed response (n=9)
- Cluster 3: Strong positive response, especially to positive-social/self messages (n=5)
Demographic analysis showed that Cluster 3 was predominantly male, while Cluster 2 was mostly female, suggesting that gender may modulate feedback efficacy.
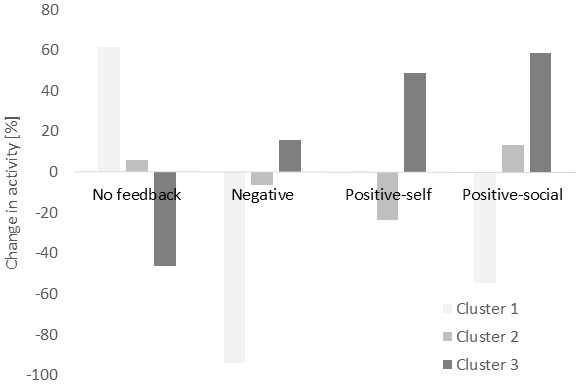
Figure 3: Change in activity as a function of feedback message in each cluster, illustrating heterogeneity in message responsiveness.
These findings underscore the necessity of individualized feedback policies and the value of incorporating demographic/contextual features into the RL model.
Learning Dynamics and Model Stability
The RL model's predictive accuracy and parameter stability improved over time as more data were collected. The adjusted R2 of the model reached approximately 0.43, indicating that a substantial fraction of day-to-day activity variance could be explained by the model's features and actions.
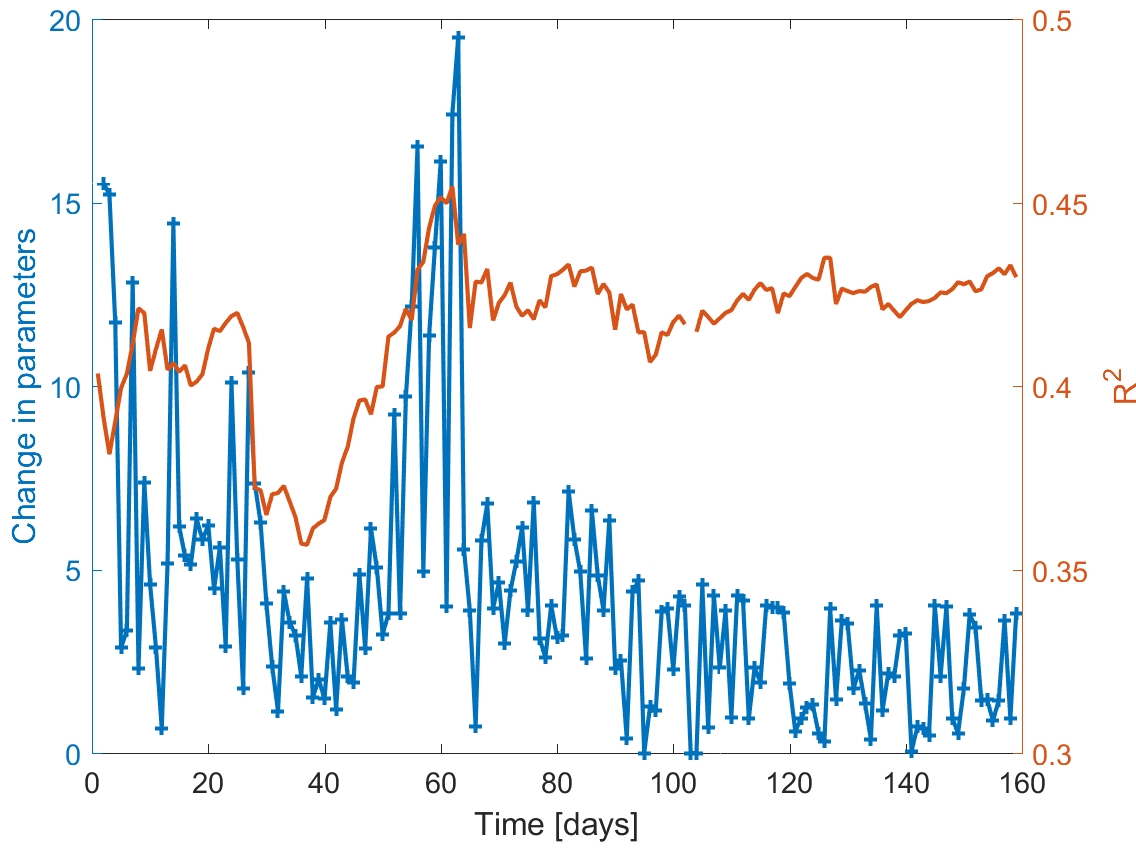
Figure 4: Learning algorithm stability and predictiveness over time, showing increasing R2 and parameter convergence.
Notably, abrupt changes in model parameters corresponded to exogenous events (e.g., adverse weather), highlighting the need for incorporating additional contextual variables (e.g., weather, calendar events) for further robustness.
Impact on Glycemic Control
Participants in the RL-driven personalized feedback group exhibited a statistically significant reduction in HbA1c compared to controls. The relative reduction in HbA1c was positively correlated with duration in the intervention and allocation to the personalized policy, even after controlling for baseline HbA1c and activity targets. The effect size, while moderate, is clinically meaningful given the intervention's scalability and low cost.
Patient Satisfaction
Survey data indicated that participants receiving personalized RL-driven messages reported higher satisfaction and perceived helpfulness of the intervention compared to those receiving static reminders. No participants in the control group found the static messages helpful, while 80% in the personalized group did.
Theoretical and Practical Implications
This study demonstrates the feasibility and effectiveness of online, on-policy RL for behavioral health interventions in a real-world clinical population. The contextual bandit approach is well-suited for settings with limited data and the need for rapid personalization. The results highlight the importance of message sequencing, demographic tailoring, and continuous adaptation.
From a practical perspective, the system is deployable at scale with minimal clinician involvement, offering a cost-effective adjunct to standard diabetes care. The approach is generalizable to other domains requiring personalized behavioral interventions, such as medication adherence, dietary management, or mental health support.
Limitations and Future Directions
The study's sample size is modest, and the duration, while sufficient for initial evaluation, limits assessment of long-term sustainability. The RL model is linear and does not capture complex nonlinearities or latent states. Future work should explore:
- Larger, more diverse cohorts to enable stratified or hierarchical modeling
- Incorporation of additional contextual features (e.g., weather, social factors)
- Nonlinear or deep RL models for richer personalization
- Off-policy evaluation and transfer learning for broader generalizability
Conclusion
The integration of RL-driven personalized feedback with mobile health monitoring yields measurable improvements in physical activity and glycemic control among sedentary type 2 diabetes patients. The contextual bandit framework enables effective, scalable, and adaptive interventions, with clear implications for digital health and chronic disease management. Further research is warranted to optimize model complexity, expand contextual awareness, and validate efficacy in larger, heterogeneous populations.