- The paper demonstrates that standard unsupervised metrics like BLEU, METEOR, and ROUGE often do not correlate with human evaluations in dialogue contexts.
- It highlights that both word overlap and embedding-based metrics struggle to capture the dynamic, contextual nuances of conversational responses.
- The study calls for developing innovative, context-aware evaluation strategies that better reflect the semantic richness of human dialogues.
Evaluating Unsupervised Metrics for Dialogue Response Generation
Overview
The paper "How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation" investigates the effectiveness of various unsupervised metrics for evaluating dialogue response generation. This study highlights the inadequacies of these metrics by comparing their outputs to human judgments in distinct domains - casual conversations on Twitter and technical dialogues in the Ubuntu Dialogue Corpus. The results expose significant shortcomings in current practices, igniting discourse on the necessity of new, more reliable evaluation methodologies.
Unsupervised Evaluation Metrics
Word Overlap Metrics
The study scrutinizes standard word overlap metrics that are adopted from machine translation and summarization. Metrics such as BLEU, METEOR, and ROUGE are assessed for their validity in dialogue systems.
- BLEU: Primarily used for machine translation, BLEU calculates n-gram precision with added brevity penalties. The research indicates that higher-order BLEU scores (BLEU-3, BLEU-4) effectively result in near-zero values in many instances, thus failing to capture dialogue nuances.
- METEOR: Unlike BLEU, METEOR creates alignments based on linguistic associations beyond direct word matches. Despite its robustness in translation tasks, METEOR does not display significant correlation with human evaluations in dialogue contexts.
- ROUGE: Typically utilized in summarization, ROUGE-L examines the longest common subsequences. Its static nature in dialogue dynamics results in minimal matching efficacy.
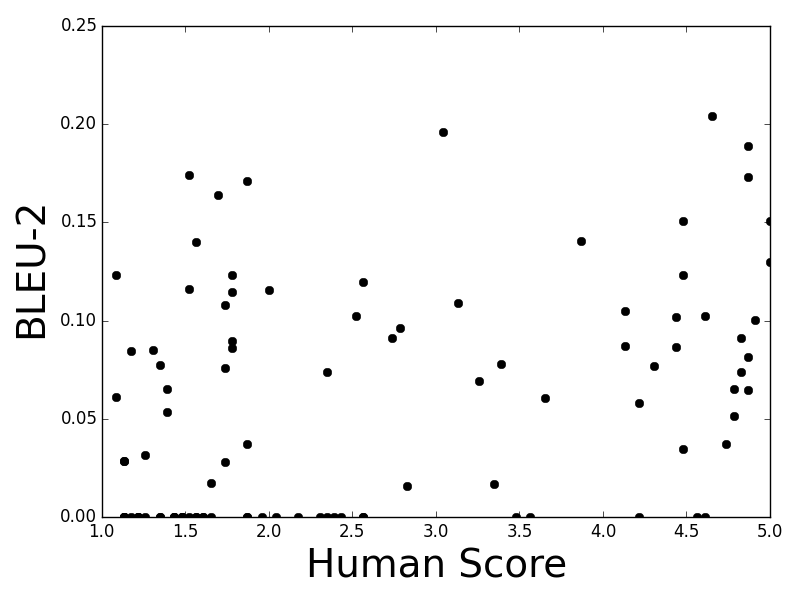
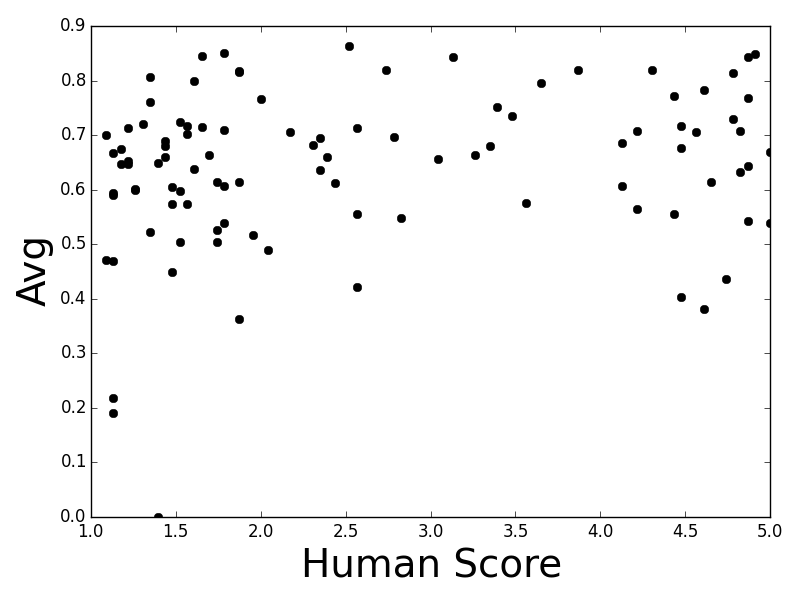
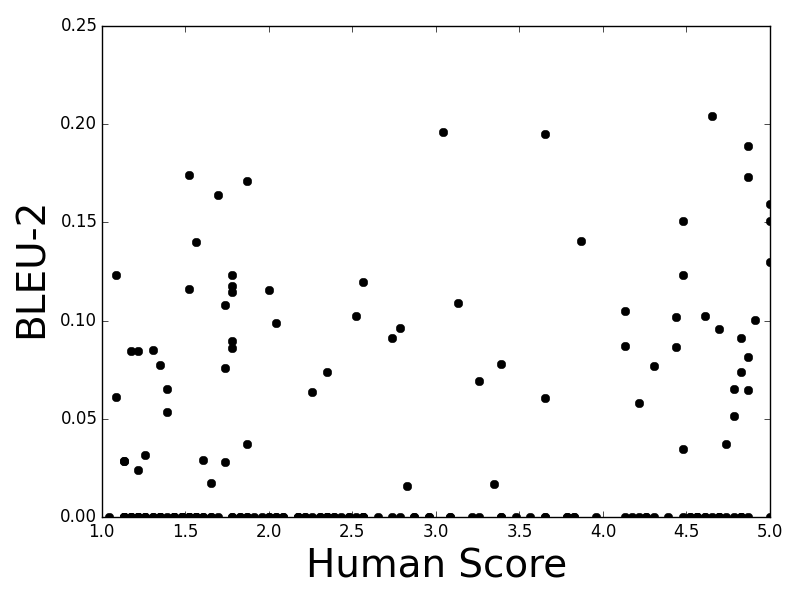
Figure 1: Twitter
Embedding-based Metrics
Alternatively, embedding-based metrics aim to capture semantic resemblance bypassing direct lexical overlaps:
- Embedding Average: Averages vector representations of words in a sentence. Despite conceptual advances, it shows limited correlation with human assessments due to a lack of contextual sensitivity.
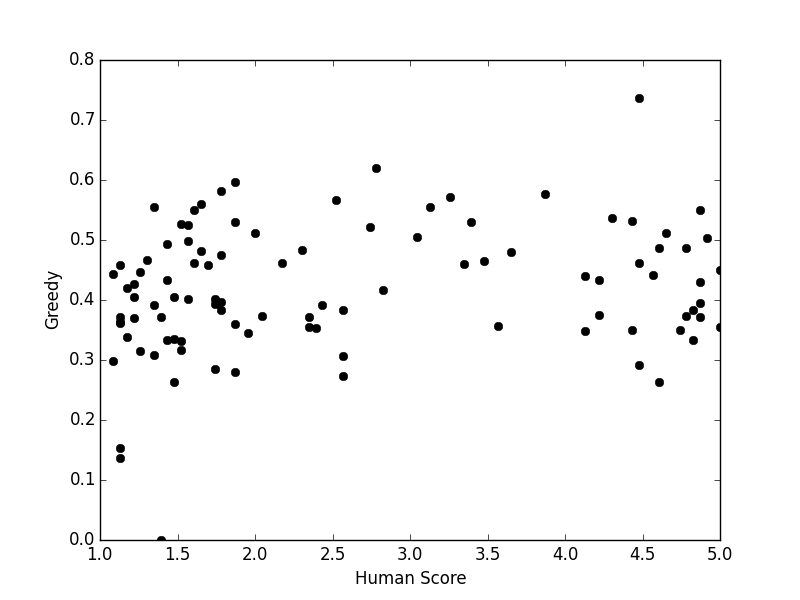
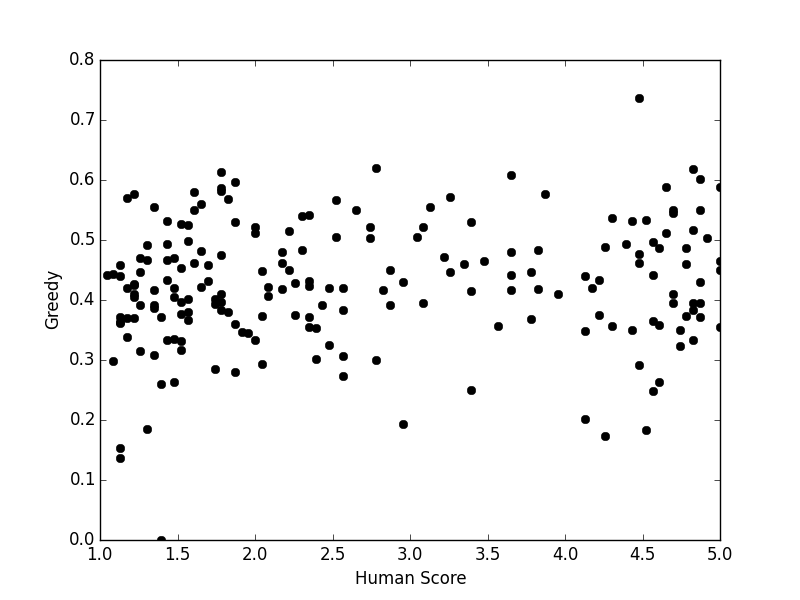
Figure 2: Vector Extrema
- Greedy Matching: Selects word pairs with the highest similarity across embeddings but overlooks the sequence and context, reducing its evaluative quality.
- Vector Extrema: Utilizes the most extreme values in vector dimensions; it is predisposed towards prioritizing outlier semantics which may not align with human judgments.
Figure 4: BLEU-1
Evaluation Against Human Judgments
The paper examines correlations between these metrics and human evaluations over several datasets and models—ranging from TF-IDF retrieval systems to RNN-based generative models. Results display drastic skew in correlation scores, with BLEU and embedding-based metrics barely aligning with human appraisals. Specifically, in technical contexts like Ubuntu Dialogue Corpus, metrics yield negligible agreements, accentuating the need for a metric shift (Figure 5).
Figure 5: ROUGE
Metrics Shortcomings and Future Directions
Through qualitative analysis, the research underscores discrepancies in metric assessments vis-à-vis human judgments, citing substantial variability in contextual and semantic applicability that current metrics fail to account for. The paper encourages exploration into context-aware or data-driven evaluative models to better reflect human-like response appropriateness.
Conclusion
The empirical findings of this paper suggest pivotal inadequacies in existing unsupervised metrics for dialogue systems. It calls for a paradigm shift toward developing evaluation strategies that are sensitive to the dynamic nature and semantic richness of human dialogues. Moving forward, there is an imperative for the research community to ideate metrics aligning closely with nuanced human perspectives to advance dialogue system efficacy.

